 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEDITS++: Limitless Image Editing using Text-to-Image Models
Nov 28, 2023

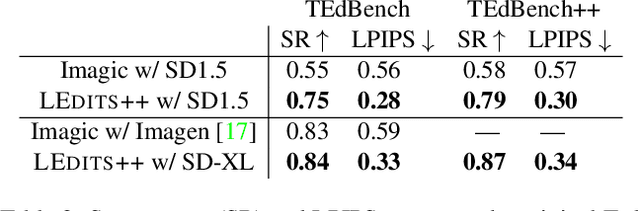

Text-to-image diffusion models have recently received increasing interest for their astonishing ability to produce high-fidelity images from solely text inputs. Subsequent research efforts aim to exploit and apply their capabilities to real image editing. However, existing image-to-image methods are often inefficient, imprecise, and of limited versatility. They either require time-consuming fine-tuning, deviate unnecessarily strongly from the input image, and/or lack support for multiple, simultaneous edits. To address these issues, we introduce LEDITS++, an efficient yet versatile and precise textual image manipulation technique. LEDITS++'s novel inversion approach requires no tuning nor optimization and produces high-fidelity results with a few diffusion steps. Second, our methodology supports multiple simultaneous edits and is architecture-agnostic. Third, we use a novel implicit masking technique that limits changes to relevant image regions. We propose the novel TEdBench++ benchmark as part of our exhaustive evaluation. Our results demonstrate the capabilities of LEDITS++ and its improvements over previous methods. The project page is available at https://leditsplusplus-project.static.hf.space .
Augmenting Zero-Shot Detection Training with Image Labels
Jun 12, 2023



Zero-shot detection (ZSD), i.e., detection on classes not seen during training, is essential for real world detection use-cases, but remains a difficult task. Recent research attempts ZSD with detection models that output embeddings instead of direct class labels. To this aim, the output of the detection model must be aligned to a learned embedding space such as CLIP. However, this alignment is hindered by detection data sets which are expensive to produce compared to image classification annotations, and the resulting lack of category diversity in the training data. We address this challenge by leveraging the CLIP embedding space in combination with image labels from ImageNet. Our results show that image labels are able to better align the detector output to the embedding space and thus have a high potential for ZSD. Compared to only training on detection data, we see a significant gain by adding image label data of 3.3 mAP for the 65/15 split on COCO on the unseen classes, i.e., we more than double the gain of related work.