 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling R-GCN Training with Graph Summarization
Mar 21, 2022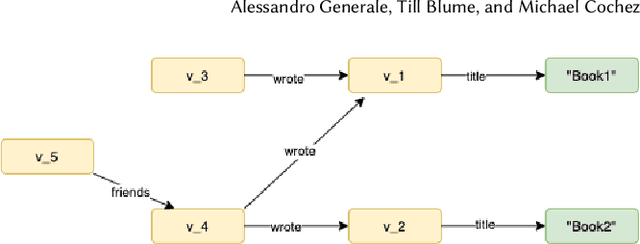


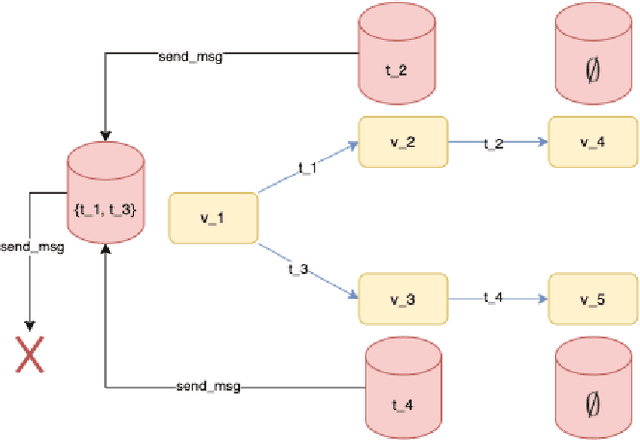
Training of Relational Graph Convolutional Networks (R-GCN) is a memory intense task. The amount of gradient information that needs to be stored during training for real-world graphs is often too large for the amount of memory available on most GPUs. In this work, we experiment with the use of graph summarization techniques to compress the graph and hence reduce the amount of memory needed. After training the R-GCN on the graph summary, we transfer the weights back to the original graph and attempt to perform inference on it. We obtain reasonable results on the AIFB, MUTAG and AM datasets. Our experiments show that training on the graph summary can yield a comparable or higher accuracy to training on the original graphs.Furthermore, if we take the time to compute the summary out of the equation, we observe that the smaller graph representations obtained with graph summarization methods reduces the computational overhead. However, further experiments are needed to evaluate additional graph summary models and whether our findings also holds true for very large graphs.