 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Language Models Good Classifiers? A Study on Edit Intent Classification in Scientific Document Revisions
Oct 02, 2024
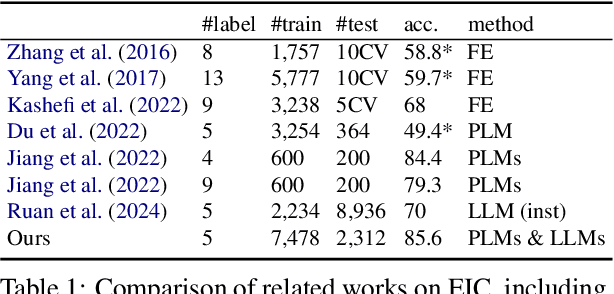


Classification is a core NLP task architecture with many potential applications. While large language models (LLMs) have brought substantial advancements in text generation, their potential for enhancing classification tasks remains underexplored. To address this gap, we propose a framework for thoroughly investigating fine-tuning LLMs for classification, including both generation- and encoding-based approaches. We instantiate this framework in edit intent classification (EIC), a challenging and underexplored classification task. Our extensive experiments and systematic comparisons with various training approaches and a representative selection of LLMs yield new insights into their application for EIC. We investigate the generalizability of these findings on five further classification tasks. To demonstrate the proposed methods and address the data shortage for empirical edit analysis, we use our best-performing EIC model to create Re3-Sci2.0, a new large-scale dataset of 1,780 scientific document revisions with over 94k labeled edits. The quality of the dataset is assessed through human evaluation. The new dataset enables an in-depth empirical study of human editing behavior in academic writing. We make our experimental framework, models and data publicly available.
Re3: A Holistic Framework and Dataset for Modeling Collaborative Document Revision
May 31, 2024Collaborative review and revision of textual documents is the core of knowledge work and a promising target for empirical analysis and NLP assistance. Yet, a holistic framework that would allow modeling complex relationships between document revisions, reviews and author responses is lacking. To address this gap, we introduce Re3, a framework for joint analysis of collaborative document revision. We instantiate this framework in the scholarly domain, and present Re3-Sci, a large corpus of aligned scientific paper revisions manually labeled according to their action and intent, and supplemented with the respective peer reviews and human-written edit summaries. We use the new data to provide first empirical insights into collaborative document revision in the academic domain, and to assess the capabilities of state-of-the-art LLMs at automating edit analysis and facilitating text-based collaboration. We make our annotation environment and protocols, the resulting data and experimental code publicly available.
HiStruct+: Improving Extractive Text Summarization with Hierarchical Structure Information
Mar 17, 2022
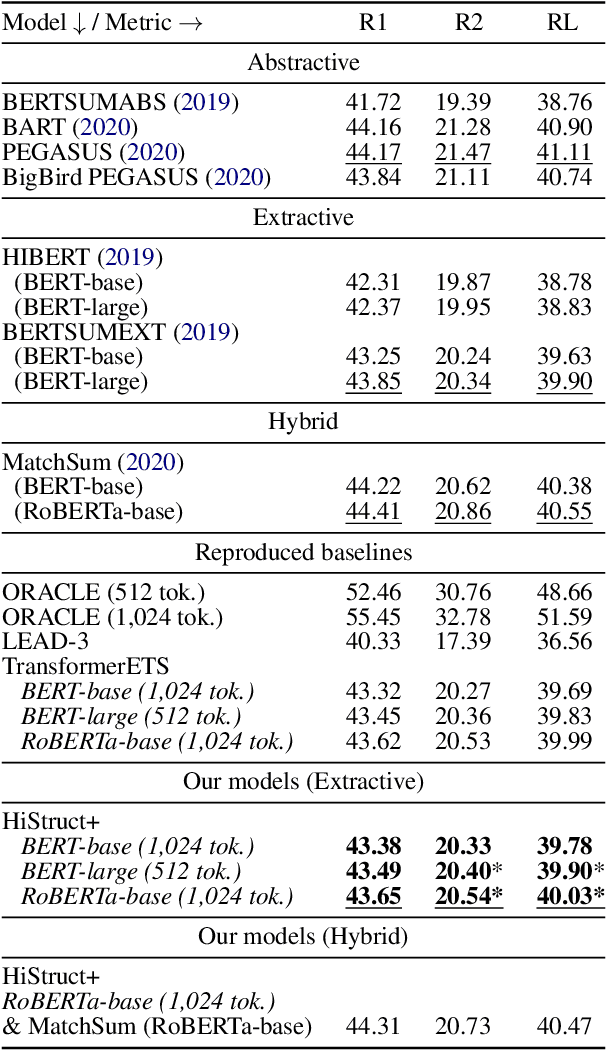

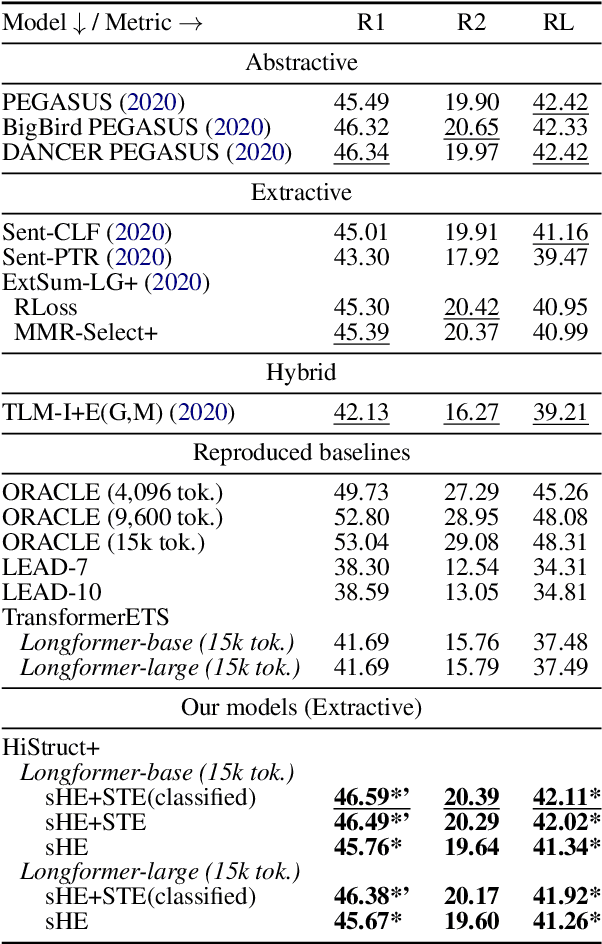
Transformer-based language models usually treat texts as linear sequences. However, most texts also have an inherent hierarchical structure, i.e., parts of a text can be identified using their position in this hierarchy. In addition, section titles usually indicate the common topic of their respective sentences. We propose a novel approach to formulate, extract, encode and inject hierarchical structure information explicitly into an extractive summarization model based on a pre-trained, encoder-only Transformer language model (HiStruct+ model), which improves SOTA ROUGEs for extractive summarization on PubMed and arXiv substantially. Using various experimental settings on three datasets (i.e., CNN/DailyMail, PubMed and arXiv), our HiStruct+ model outperforms a strong baseline collectively, which differs from our model only in that the hierarchical structure information is not injected. It is also observed that the more conspicuous hierarchical structure the dataset has, the larger improvements our method gains. The ablation study demonstrates that the hierarchical position information is the main contributor to our model's SOTA performance.