 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiStruct+: Improving Extractive Text Summarization with Hierarchical Structure Information
Paper and Code

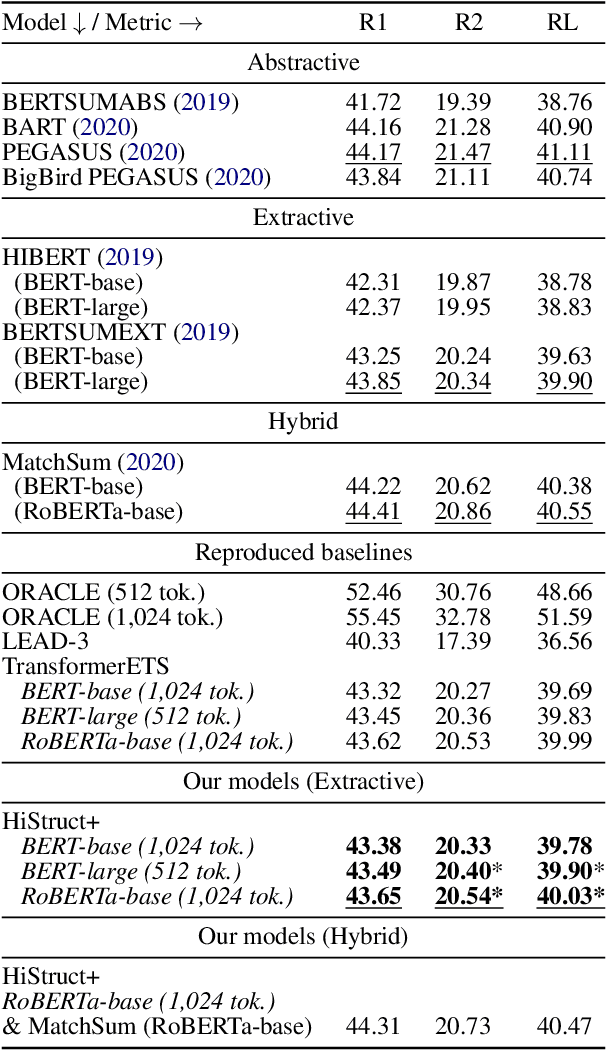

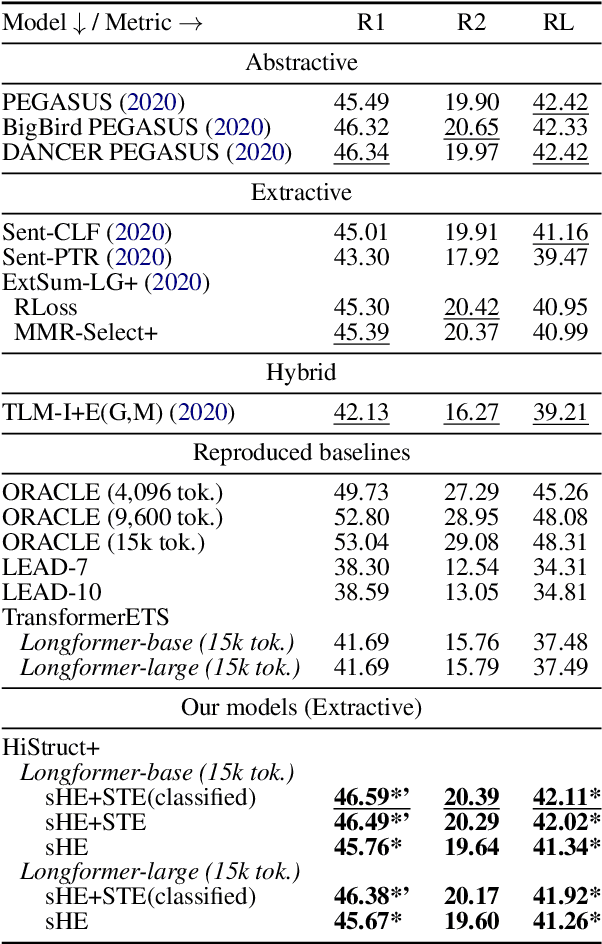
Transformer-based language models usually treat texts as linear sequences. However, most texts also have an inherent hierarchical structure, i.e., parts of a text can be identified using their position in this hierarchy. In addition, section titles usually indicate the common topic of their respective sentences. We propose a novel approach to formulate, extract, encode and inject hierarchical structure information explicitly into an extractive summarization model based on a pre-trained, encoder-only Transformer language model (HiStruct+ model), which improves SOTA ROUGEs for extractive summarization on PubMed and arXiv substantially. Using various experimental settings on three datasets (i.e., CNN/DailyMail, PubMed and arXiv), our HiStruct+ model outperforms a strong baseline collectively, which differs from our model only in that the hierarchical structure information is not injected. It is also observed that the more conspicuous hierarchical structure the dataset has, the larger improvements our method gains. The ablation study demonstrates that the hierarchical position information is the main contributor to our model's SOTA performance.