 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersuasion Tokens for Editing Factual Knowledge in LLMs
Jan 26, 2026In-context knowledge editing (IKE) is a promising technique for updating Large Language Models (LLMs) with new information. However, IKE relies on lengthy, fact-specific demonstrations which are costly to create and consume significant context window space. In this paper, we introduce persuasion tokens (P-Tokens) -- special tokens trained to replicate the effect of IKE demonstrations, enabling efficient knowledge editing without requiring fact-specific demonstrations. We evaluate P-Tokens across two editing datasets and three LLMs, demonstrating performance comparable to, and often exceeding, IKE. We further find that editing performance is robust to distractors with small negative effects to neighboring facts, and that increasing the number of P-Tokens improves performance. Our work addresses key limitations of IKE and provides a more practical and scalable alternative for editing LLMs.
Quantifying Edits Decay in Fine-tuned LLMs
Nov 12, 2025Knowledge editing has emerged as a lightweight alternative to retraining for correcting or injecting specific facts in large language models (LLMs). Meanwhile, fine-tuning remains the default operation for adapting LLMs to new domains and tasks. Despite their widespread adoption, these two post-training interventions have been studied in isolation, leaving open a crucial question: if we fine-tune an edited model, do the edits survive? This question is motivated by two practical scenarios: removing covert or malicious edits, and preserving beneficial edits. If fine-tuning impairs edits as shown in Figure 1, current KE methods become less useful, as every fine-tuned model would require re-editing, which significantly increases the cost; if edits persist, fine-tuned models risk propagating hidden malicious edits, raising serious safety concerns. To this end, we systematically quantify edits decay after fine-tuning, investigating how fine-tuning affects knowledge editing. We evaluate two state-of-the-art editing methods (MEMIT, AlphaEdit) and three fine-tuning approaches (full-parameter, LoRA, DoRA) across five LLMs and three datasets, yielding 232 experimental configurations. Our results show that edits decay after fine-tuning, with survival varying across configurations, e.g., AlphaEdit edits decay more than MEMIT edits. Further, we propose selective-layer fine-tuning and find that fine-tuning edited layers only can effectively remove edits, though at a slight cost to downstream performance. Surprisingly, fine-tuning non-edited layers impairs more edits than full fine-tuning. Overall, our study establishes empirical baselines and actionable strategies for integrating knowledge editing with fine-tuning, and underscores that evaluating model editing requires considering the full LLM application pipeline.
Tracing and Reversing Rank-One Model Edits
May 27, 2025Knowledge editing methods (KEs) are a cost-effective way to update the factual content of large language models (LLMs), but they pose a dual-use risk. While KEs are beneficial for updating outdated or incorrect information, they can be exploited maliciously to implant misinformation or bias. In order to defend against these types of malicious manipulation, we need robust techniques that can reliably detect, interpret, and mitigate adversarial edits. This work investigates the traceability and reversibility of knowledge edits, focusing on the widely used Rank-One Model Editing (ROME) method. We first show that ROME introduces distinctive distributional patterns in the edited weight matrices, which can serve as effective signals for locating the edited weights. Second, we show that these altered weights can reliably be used to predict the edited factual relation, enabling partial reconstruction of the modified fact. Building on this, we propose a method to infer the edited object entity directly from the modified weights, without access to the editing prompt, achieving over 95% accuracy. Finally, we demonstrate that ROME edits can be reversed, recovering the model's original outputs with $\geq$ 80% accuracy. Our findings highlight the feasibility of detecting, tracing, and reversing edits based on the edited weights, offering a robust framework for safeguarding LLMs against adversarial manipulations.
Position: Editing Large Language Models Poses Serious Safety Risks
Feb 05, 2025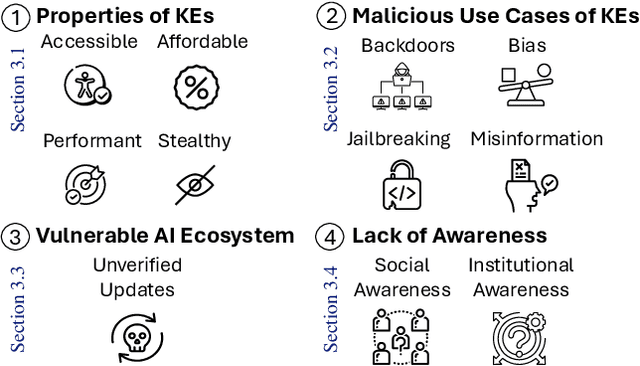



Large Language Models (LLMs) contain large amounts of facts about the world. These facts can become outdated over time, which has led to the development of knowledge editing methods (KEs) that can change specific facts in LLMs with limited side effects. This position paper argues that editing LLMs poses serious safety risks that have been largely overlooked. First, we note the fact that KEs are widely available, computationally inexpensive, highly performant, and stealthy makes them an attractive tool for malicious actors. Second, we discuss malicious use cases of KEs, showing how KEs can be easily adapted for a variety of malicious purposes. Third, we highlight vulnerabilities in the AI ecosystem that allow unrestricted uploading and downloading of updated models without verification. Fourth, we argue that a lack of social and institutional awareness exacerbates this risk, and discuss the implications for different stakeholders. We call on the community to (i) research tamper-resistant models and countermeasures against malicious model editing, and (ii) actively engage in securing the AI ecosystem.
Enhancing Fact Retrieval in PLMs through Truthfulness
Oct 17, 2024



Pre-trained Language Models (PLMs) encode various facts about the world at their pre-training phase as they are trained to predict the next or missing word in a sentence. There has a been an interest in quantifying and improving the amount of facts that can be extracted from PLMs, as they have been envisioned to act as soft knowledge bases, which can be queried in natural language. Different approaches exist to enhance fact retrieval from PLM. Recent work shows that the hidden states of PLMs can be leveraged to determine the truthfulness of the PLMs' inputs. Leveraging this finding to improve factual knowledge retrieval remains unexplored. In this work, we investigate the use of a helper model to improve fact retrieval. The helper model assesses the truthfulness of an input based on the corresponding hidden states representations from the PLMs. We evaluate this approach on several masked PLMs and show that it enhances fact retrieval by up to 33\%. Our findings highlight the potential of hidden states representations from PLMs in improving their factual knowledge retrieval.
Can We Reverse In-Context Knowledge Edits?
Oct 16, 2024
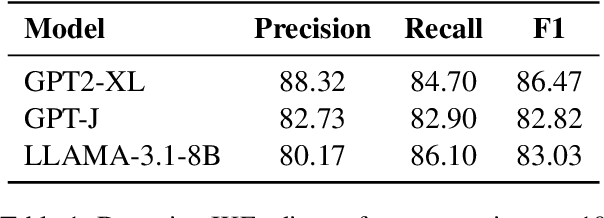

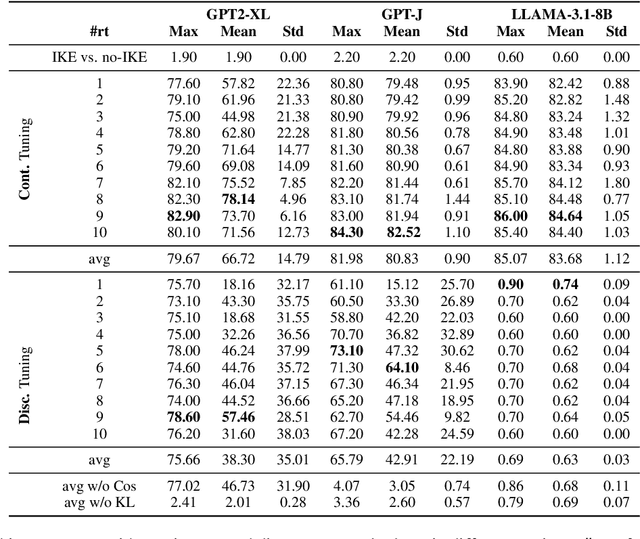
In-context knowledge editing (IKE) enables efficient modification of large language model (LLM) outputs without parameter changes and at zero-cost. However, it can be misused to manipulate responses opaquely, e.g., insert misinformation or offensive content. Such malicious interventions could be incorporated into high-level wrapped APIs where the final input prompt is not shown to end-users. To address this issue, we investigate the detection and reversal of IKE-edits. First, we demonstrate that IKE-edits can be detected with high accuracy (F1 > 80\%) using only the top-10 output probabilities of the next token, even in a black-box setting, e.g. proprietary LLMs with limited output information. Further, we introduce the novel task of reversing IKE-edits using specially tuned reversal tokens. We explore using both continuous and discrete reversal tokens, achieving over 80\% accuracy in recovering original, unedited outputs across multiple LLMs. Our continuous reversal tokens prove particularly effective, with minimal impact on unedited prompts. Through analysis of output distributions, attention patterns, and token rankings, we provide insights into IKE's effects on LLMs and how reversal tokens mitigate them. This work represents a significant step towards enhancing LLM resilience against potential misuse of in-context editing, improving their transparency and trustworthiness.
Detecting Edited Knowledge in Language Models
May 04, 2024



Knowledge editing techniques (KEs) can update language models' obsolete or inaccurate knowledge learned from pre-training. However, KE also faces potential malicious applications, e.g. inserting misinformation and toxic content. Moreover, in the context of responsible AI, it is instructive for end-users to know whether a generated output is driven by edited knowledge or first-hand knowledge from pre-training. To this end, we study detecting edited knowledge in language models by introducing a novel task: given an edited model and a specific piece of knowledge the model generates, our objective is to classify the knowledge as either "non-edited" (based on the pre-training), or ``edited'' (based on subsequent editing). We initiate the task with two state-of-the-art KEs, two language models, and two datasets. We further propose a simple classifier, RepReg, a logistic regression model that takes hidden state representations as input features. Our results reveal that RepReg establishes a strong baseline, achieving a peak accuracy of 99.81%, and 97.79% in out-of-domain settings. Second, RepReg achieves near-optimal performance with a limited training set (200 training samples), and it maintains its performance even in out-of-domain settings. Last, we find it more challenging to separate edited and non-edited knowledge when they contain the same subject or object.
LLMs for Generating and Evaluating Counterfactuals: A Comprehensive Study
Apr 26, 2024As NLP models become more complex, understanding their decisions becomes more crucial. Counterfactuals (CFs), where minimal changes to inputs flip a model's prediction, offer a way to explain these models. While Large Language Models (LLMs) have shown remarkable performance in NLP tasks, their efficacy in generating high-quality CFs remains uncertain. This work fills this gap by investigating how well LLMs generate CFs for two NLU tasks. We conduct a comprehensive comparison of several common LLMs, and evaluate their CFs, assessing both intrinsic metrics, and the impact of these CFs on data augmentation. Moreover, we analyze differences between human and LLM-generated CFs, providing insights for future research directions. Our results show that LLMs generate fluent CFs, but struggle to keep the induced changes minimal. Generating CFs for Sentiment Analysis (SA) is less challenging than NLI where LLMs show weaknesses in generating CFs that flip the original label. This also reflects on the data augmentation performance, where we observe a large gap between augmenting with human and LLMs CFs. Furthermore, we evaluate LLMs' ability to assess CFs in a mislabelled data setting, and show that they have a strong bias towards agreeing with the provided labels. GPT4 is more robust against this bias and its scores correlate well with automatic metrics. Our findings reveal several limitations and point to potential future work directions.
The Queen of England is not England's Queen: On the Lack of Factual Coherency in PLMs
Feb 02, 2024Factual knowledge encoded in Pre-trained Language Models (PLMs) enriches their representations and justifies their use as knowledge bases. Previous work has focused on probing PLMs for factual knowledge by measuring how often they can correctly predict an object entity given a subject and a relation, and improving fact retrieval by optimizing the prompts used for querying PLMs. In this work, we consider a complementary aspect, namely the coherency of factual knowledge in PLMs, i.e., how often can PLMs predict the subject entity given its initial prediction of the object entity. This goes beyond evaluating how much PLMs know, and focuses on the internal state of knowledge inside them. Our results indicate that PLMs have low coherency using manually written, optimized and paraphrased prompts, but including an evidence paragraph leads to substantial improvement. This shows that PLMs fail to model inverse relations and need further enhancements to be able to handle retrieving facts from their parameters in a coherent manner, and to be considered as knowledge bases.
Give Me the Facts! A Survey on Factual Knowledge Probing in Pre-trained Language Models
Oct 25, 2023



Pre-trained Language Models (PLMs) are trained on vast unlabeled data, rich in world knowledge. This fact has sparked the interest of the community in quantifying the amount of factual knowledge present in PLMs, as this explains their performance on downstream tasks, and potentially justifies their use as knowledge bases. In this work, we survey methods and datasets that are used to probe PLMs for factual knowledge. Our contributions are: (1) We propose a categorization scheme for factual probing methods that is based on how their inputs, outputs and the probed PLMs are adapted; (2) We provide an overview of the datasets used for factual probing; (3) We synthesize insights about knowledge retention and prompt optimization in PLMs, analyze obstacles to adopting PLMs as knowledge bases and outline directions for future work.