 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Reverse In-Context Knowledge Edits?
Paper and Code
Oct 16, 2024
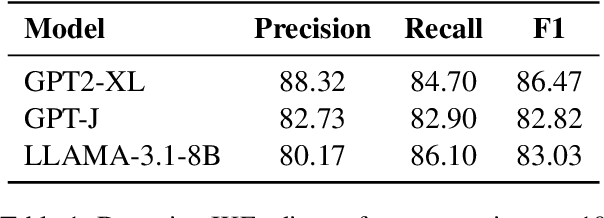

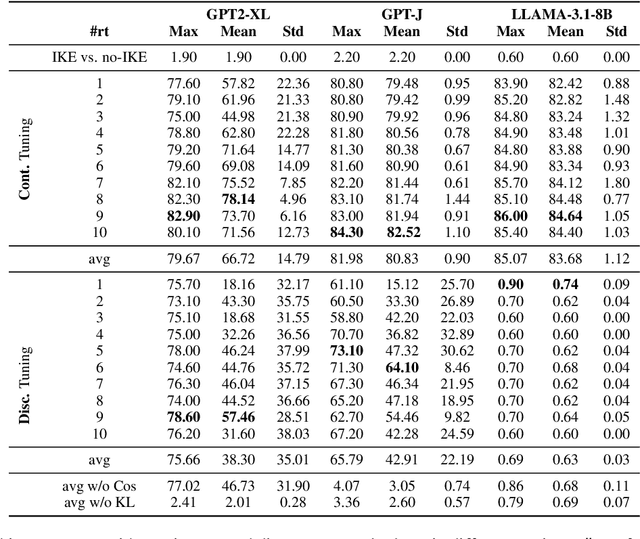
In-context knowledge editing (IKE) enables efficient modification of large language model (LLM) outputs without parameter changes and at zero-cost. However, it can be misused to manipulate responses opaquely, e.g., insert misinformation or offensive content. Such malicious interventions could be incorporated into high-level wrapped APIs where the final input prompt is not shown to end-users. To address this issue, we investigate the detection and reversal of IKE-edits. First, we demonstrate that IKE-edits can be detected with high accuracy (F1 > 80\%) using only the top-10 output probabilities of the next token, even in a black-box setting, e.g. proprietary LLMs with limited output information. Further, we introduce the novel task of reversing IKE-edits using specially tuned reversal tokens. We explore using both continuous and discrete reversal tokens, achieving over 80\% accuracy in recovering original, unedited outputs across multiple LLMs. Our continuous reversal tokens prove particularly effective, with minimal impact on unedited prompts. Through analysis of output distributions, attention patterns, and token rankings, we provide insights into IKE's effects on LLMs and how reversal tokens mitigate them. This work represents a significant step towards enhancing LLM resilience against potential misuse of in-context editing, improving their transparency and trustworthiness.