 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning methods for automatic evaluation of delayed enhancement-MRI. The results of the EMIDEC challenge
Aug 10, 2021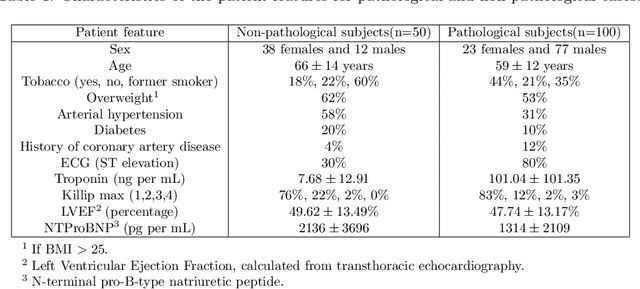

A key factor for assessing the state of the heart after myocardial infarction (MI) is to measure whether the myocardium segment is viable after reperfusion or revascularization therapy. Delayed enhancement-MRI or DE-MRI, which is performed several minutes after injection of the contrast agent, provides high contrast between viable and nonviable myocardium and is therefore a method of choice to evaluate the extent of MI. To automatically assess myocardial status, the results of the EMIDEC challenge that focused on this task are presented in this paper. The challenge's main objectives were twofold. First, to evaluate if deep learning methods can distinguish between normal and pathological cases. Second, to automatically calculate the extent of myocardial infarction. The publicly available database consists of 150 exams divided into 50 cases with normal MRI after injection of a contrast agent and 100 cases with myocardial infarction (and then with a hyperenhanced area on DE-MRI), whatever their inclusion in the cardiac emergency department. Along with MRI, clinical characteristics are also provided. The obtained results issued from several works show that the automatic classification of an exam is a reachable task (the best method providing an accuracy of 0.92), and the automatic segmentation of the myocardium is possible. However, the segmentation of the diseased area needs to be improved, mainly due to the small size of these areas and the lack of contrast with the surrounding structures.
Binary Particle Swarm Optimization versus Hybrid Genetic Algorithm for Inferring Well Supported Phylogenetic Trees
Aug 31, 2016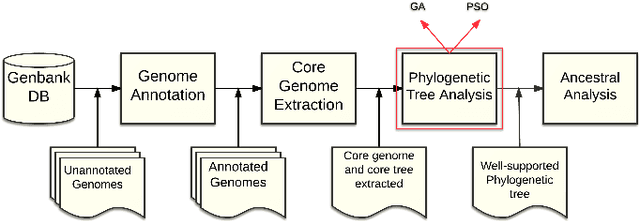
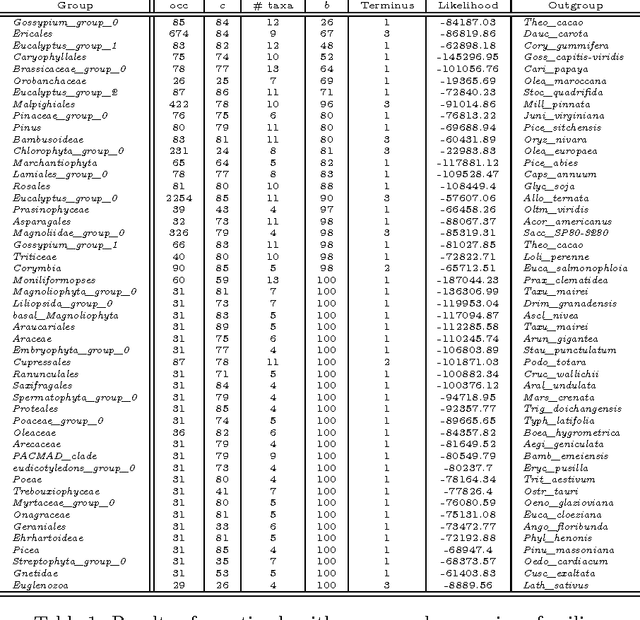

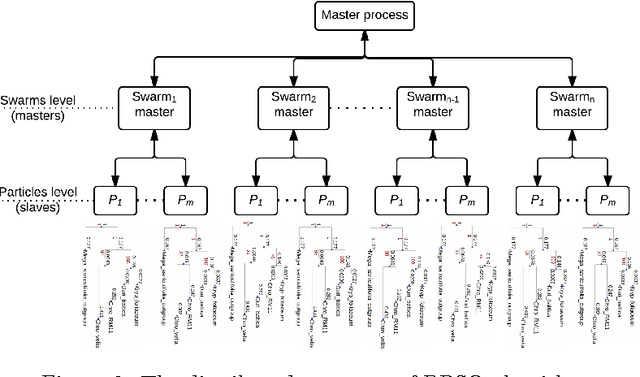
The amount of completely sequenced chloroplast genomes increases rapidly every day, leading to the possibility to build large-scale phylogenetic trees of plant species. Considering a subset of close plant species defined according to their chloroplasts, the phylogenetic tree that can be inferred by their core genes is not necessarily well supported, due to the possible occurrence of problematic genes (i.e., homoplasy, incomplete lineage sorting, horizontal gene transfers, etc.) which may blur the phylogenetic signal. However, a trustworthy phylogenetic tree can still be obtained provided such a number of blurring genes is reduced. The problem is thus to determine the largest subset of core genes that produces the best-supported tree. To discard problematic genes and due to the overwhelming number of possible combinations, this article focuses on how to extract the largest subset of sequences in order to obtain the most supported species tree. Due to computational complexity, a distributed Binary Particle Swarm Optimization (BPSO) is proposed in sequential and distributed fashions. Obtained results from both versions of the BPSO are compared with those computed using an hybrid approach embedding both genetic algorithms and statistical tests. The proposal has been applied to different cases of plant families, leading to encouraging results for these families.
Neural Networks and Chaos: Construction, Evaluation of Chaotic Networks, and Prediction of Chaos with Multilayer Feedforward Networks
Aug 21, 2016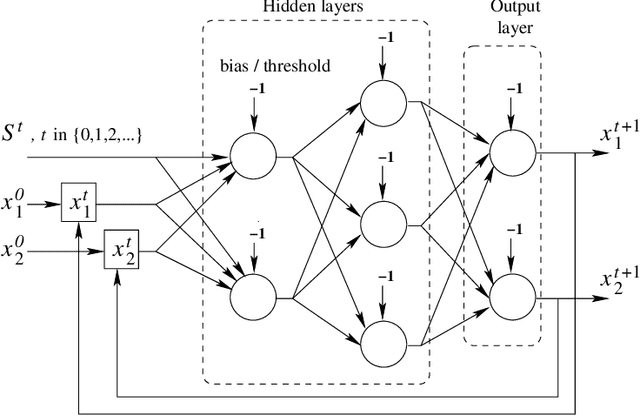
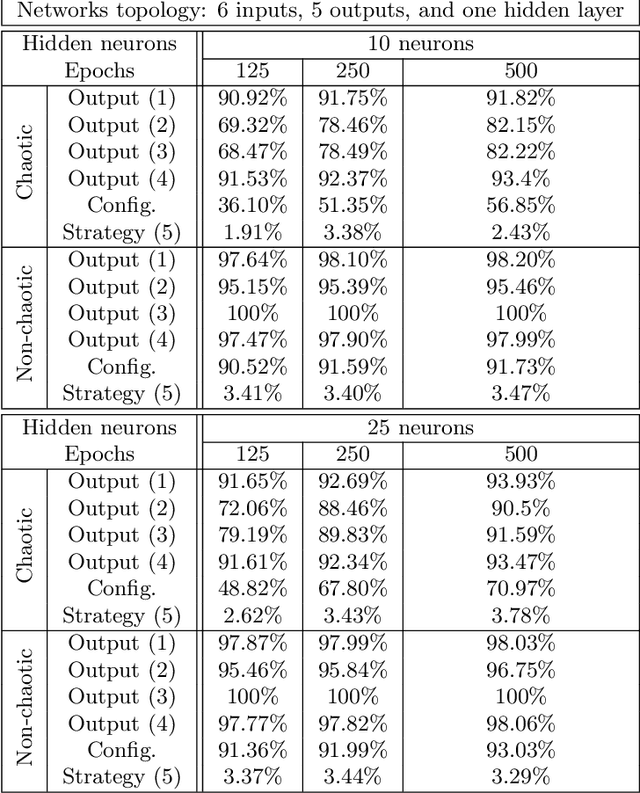
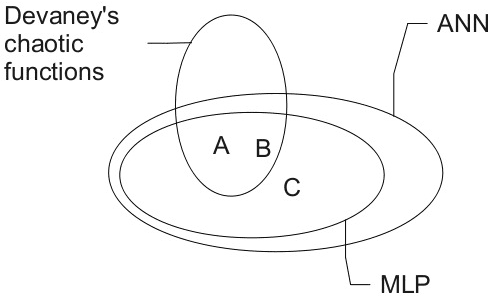

Many research works deal with chaotic neural networks for various fields of application. Unfortunately, up to now these networks are usually claimed to be chaotic without any mathematical proof. The purpose of this paper is to establish, based on a rigorous theoretical framework, an equivalence between chaotic iterations according to Devaney and a particular class of neural networks. On the one hand we show how to build such a network, on the other hand we provide a method to check if a neural network is a chaotic one. Finally, the ability of classical feedforward multilayer perceptrons to learn sets of data obtained from a dynamical system is regarded. Various Boolean functions are iterated on finite states. Iterations of some of them are proven to be chaotic as it is defined by Devaney. In that context, important differences occur in the training process, establishing with various neural networks that chaotic behaviors are far more difficult to learn.
Hybrid Genetic Algorithm and Lasso Test Approach for Inferring Well Supported Phylogenetic Trees based on Subsets of Chloroplastic Core Genes
Apr 20, 2015
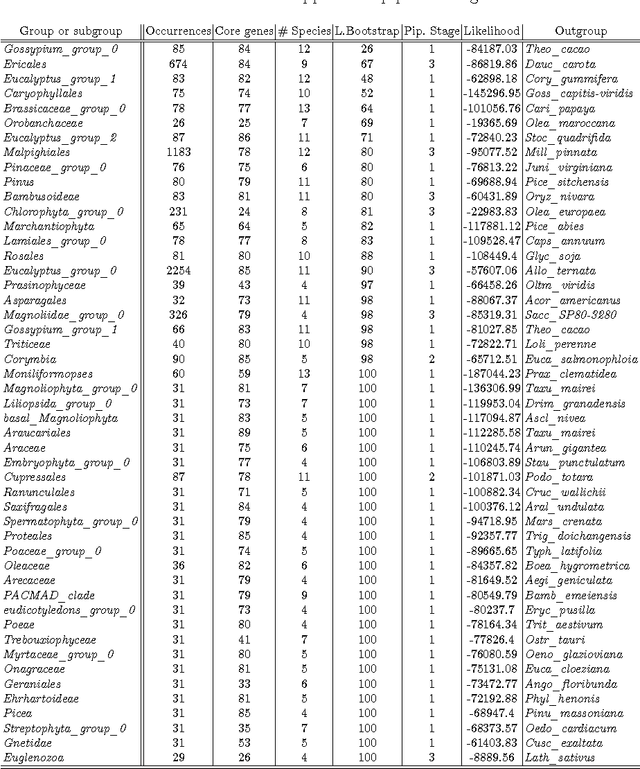
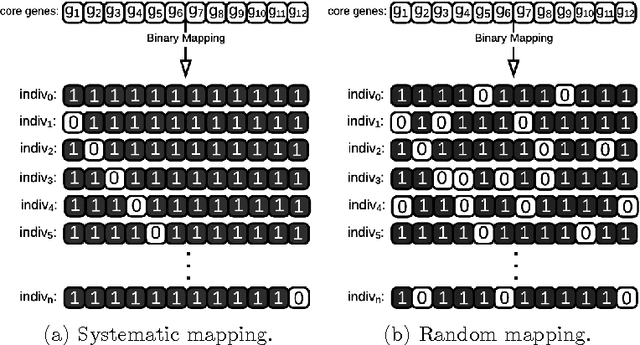
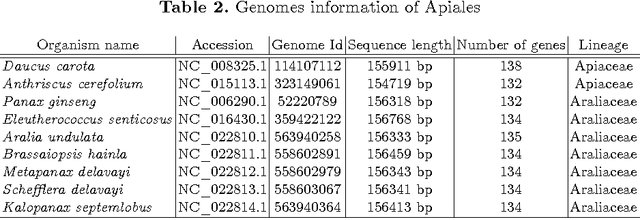
The amount of completely sequenced chloroplast genomes increases rapidly every day, leading to the possibility to build large scale phylogenetic trees of plant species. Considering a subset of close plant species defined according to their chloroplasts, the phylogenetic tree that can be inferred by their core genes is not necessarily well supported, due to the possible occurrence of "problematic" genes (i.e., homoplasy, incomplete lineage sorting, horizontal gene transfers, etc.) which may blur phylogenetic signal. However, a trustworthy phylogenetic tree can still be obtained if the number of problematic genes is low, the problem being to determine the largest subset of core genes that produces the best supported tree. To discard problematic genes and due to the overwhelming number of possible combinations, we propose an hybrid approach that embeds both genetic algorithms and statistical tests. Given a set of organisms, the result is a pipeline of many stages for the production of well supported phylogenetic trees. The proposal has been applied to different cases of plant families, leading to encouraging results for these families.
Gene Similarity-based Approaches for Determining Core-Genes of Chloroplasts
Dec 17, 2014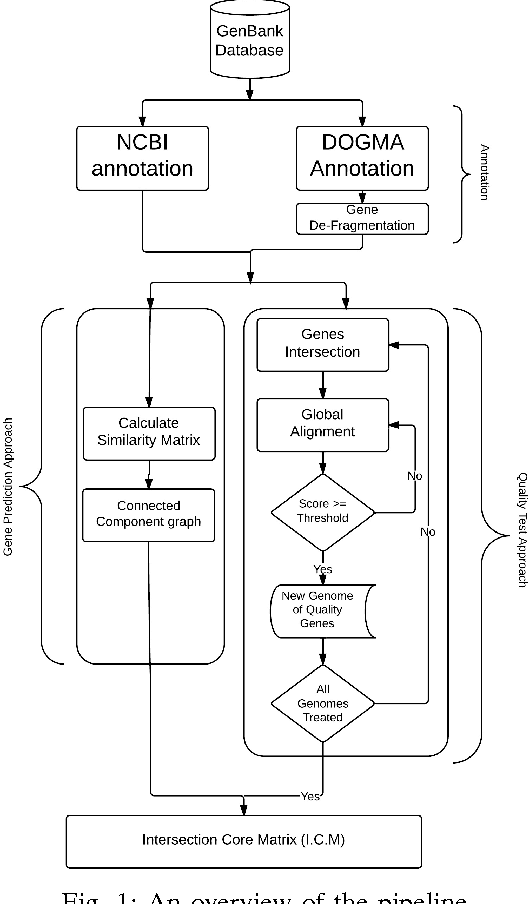
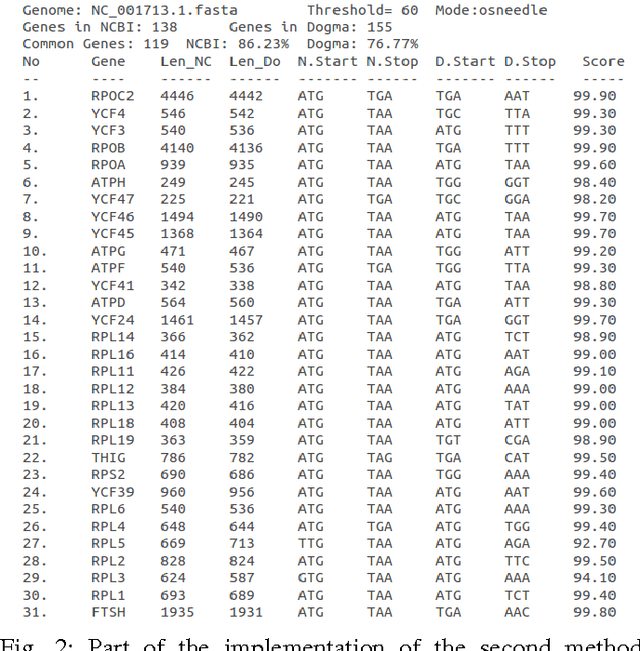
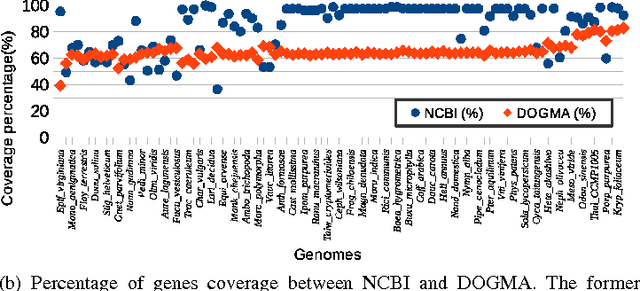
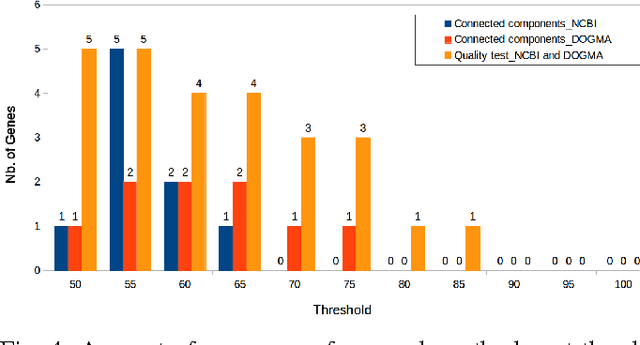
In computational biology and bioinformatics, the manner to understand evolution processes within various related organisms paid a lot of attention these last decades. However, accurate methodologies are still needed to discover genes content evolution. In a previous work, two novel approaches based on sequence similarities and genes features have been proposed. More precisely, we proposed to use genes names, sequence similarities, or both, insured either from NCBI or from DOGMA annotation tools. Dogma has the advantage to be an up-to-date accurate automatic tool specifically designed for chloroplasts, whereas NCBI possesses high quality human curated genes (together with wrongly annotated ones). The key idea of the former proposal was to take the best from these two tools. However, the first proposal was limited by name variations and spelling errors on the NCBI side, leading to core trees of low quality. In this paper, these flaws are fixed by improving the comparison of NCBI and DOGMA results, and by relaxing constraints on gene names while adding a stage of post-validation on gene sequences. The two stages of similarity measures, on names and sequences, are thus proposed for sequence clustering. This improves results that can be obtained using either NCBI or DOGMA alone. Results obtained with this quality control test are further investigated and compared with previously released ones, on both computational and biological aspects, considering a set of 99 chloroplastic genomes.
Building a Chaotic Proved Neural Network
Jan 23, 2011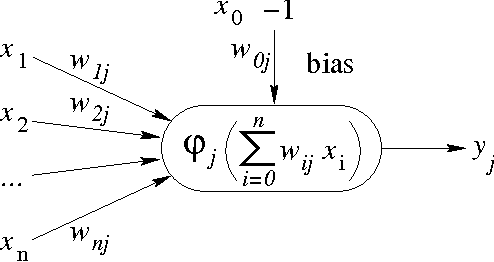
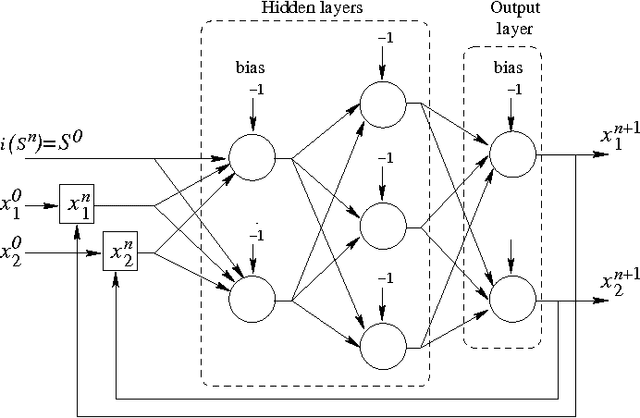

Chaotic neural networks have received a great deal of attention these last years. In this paper we establish a precise correspondence between the so-called chaotic iterations and a particular class of artificial neural networks: global recurrent multi-layer perceptrons. We show formally that it is possible to make these iterations behave chaotically, as defined by Devaney, and thus we obtain the first neural networks proven chaotic. Several neural networks with different architectures are trained to exhibit a chaotical behavior.