 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Semi-Supervised Domain Adaptation for Semantic Segmentation: A New Role for Labeled Target Samples
Dec 12, 2023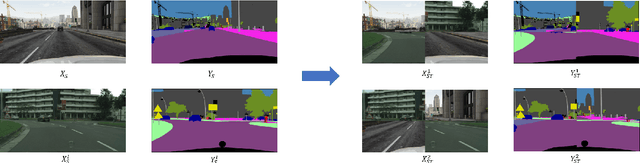
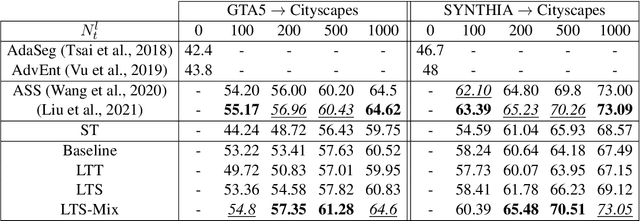
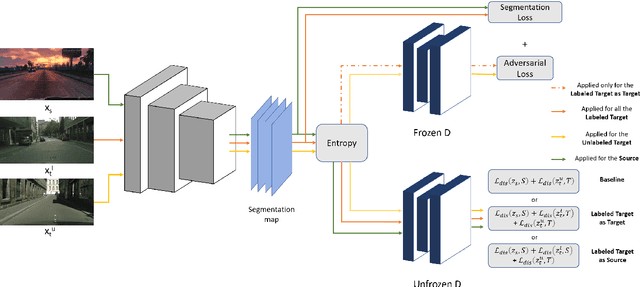
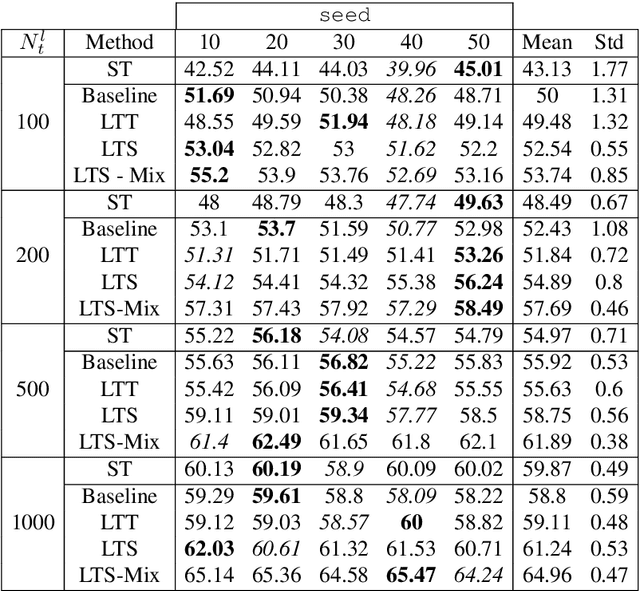
Adversarial learning baselines for domain adaptation (DA) approaches in the context of semantic segmentation are under explored in semi-supervised framework. These baselines involve solely the available labeled target samples in the supervision loss. In this work, we propose to enhance their usefulness on both semantic segmentation and the single domain classifier neural networks. We design new training objective losses for cases when labeled target data behave as source samples or as real target samples. The underlying rationale is that considering the set of labeled target samples as part of source domain helps reducing the domain discrepancy and, hence, improves the contribution of the adversarial loss. To support our approach, we consider a complementary method that mixes source and labeled target data, then applies the same adaptation process. We further propose an unsupervised selection procedure using entropy to optimize the choice of labeled target samples for adaptation. We illustrate our findings through extensive experiments on the benchmarks GTA5, SYNTHIA, and Cityscapes. The empirical evaluation highlights competitive performance of our proposed approach.
Open Set Domain Adaptation using Optimal Transport
Oct 02, 2020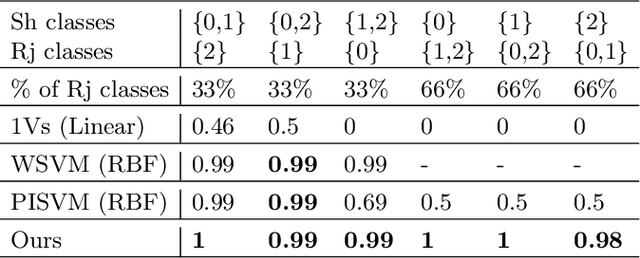
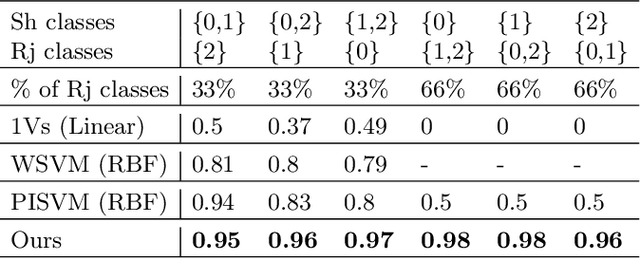
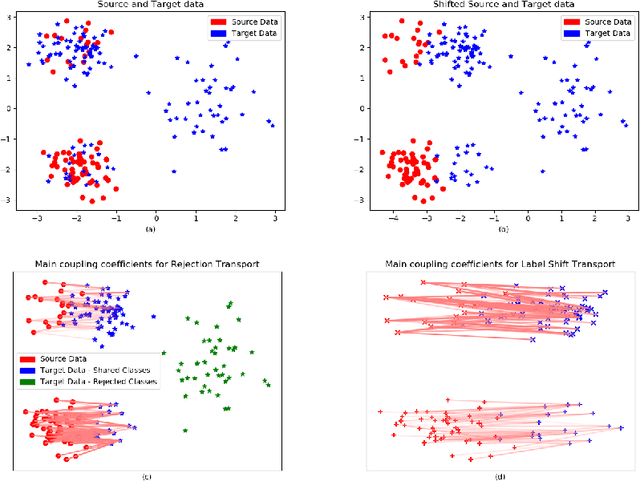
We present a 2-step optimal transport approach that performs a mapping from a source distribution to a target distribution. Here, the target has the particularity to present new classes not present in the source domain. The first step of the approach aims at rejecting the samples issued from these new classes using an optimal transport plan. The second step solves the target (class ratio) shift still as an optimal transport problem. We develop a dual approach to solve the optimization problem involved at each step and we prove that our results outperform recent state-of-the-art performances. We further apply the approach to the setting where the source and target distributions present both a label-shift and an increasing covariate (features) shift to show its robustness.