 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Patient Survival with Airway Biomarkers using nn-Unet/Radiomics
Jun 13, 2025The primary objective of the AIIB 2023 competition is to evaluate the predictive significance of airway-related imaging biomarkers in determining the survival outcomes of patients with lung fibrosis.This study introduces a comprehensive three-stage approach. Initially, a segmentation network, namely nn-Unet, is employed to delineate the airway's structural boundaries. Subsequently, key features are extracted from the radiomic images centered around the trachea and an enclosing bounding box around the airway. This step is motivated by the potential presence of critical survival-related insights within the tracheal region as well as pertinent information encoded in the structure and dimensions of the airway. Lastly, radiomic features obtained from the segmented areas are integrated into an SVM classifier. We could obtain an overall-score of 0.8601 for the segmentation in Task 1 while 0.7346 for the classification in Task 2.
TD-Paint: Faster Diffusion Inpainting Through Time Aware Pixel Conditioning
Oct 11, 2024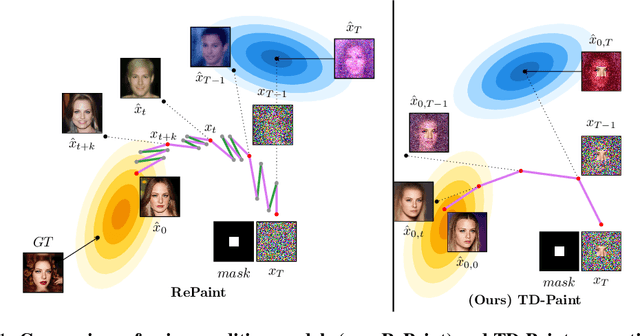



Diffusion models have emerged as highly effective techniques for inpainting, however, they remain constrained by slow sampling rates. While recent advances have enhanced generation quality, they have also increased sampling time, thereby limiting scalability in real-world applications. We investigate the generative sampling process of diffusion-based inpainting models and observe that these models make minimal use of the input condition during the initial sampling steps. As a result, the sampling trajectory deviates from the data manifold, requiring complex synchronization mechanisms to realign the generation process. To address this, we propose Time-aware Diffusion Paint (TD-Paint), a novel approach that adapts the diffusion process by modeling variable noise levels at the pixel level. This technique allows the model to efficiently use known pixel values from the start, guiding the generation process toward the target manifold. By embedding this information early in the diffusion process, TD-Paint significantly accelerates sampling without compromising image quality. Unlike conventional diffusion-based inpainting models, which require a dedicated architecture or an expensive generation loop, TD-Paint achieves faster sampling times without architectural modifications. Experimental results across three datasets show that TD-Paint outperforms state-of-the-art diffusion models while maintaining lower complexity.
Random Forest Dissimilarity for High-Dimension Low Sample Size Classification
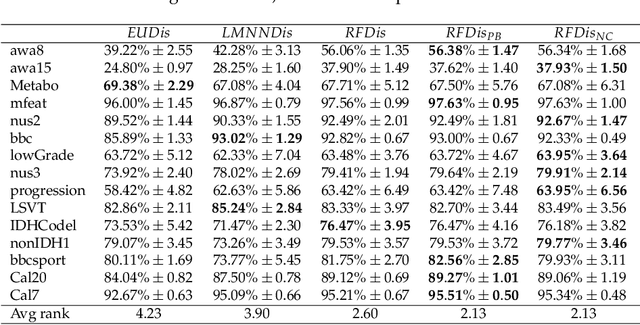
Oct 23, 2023High dimension, low sample size (HDLSS) problems are numerous among real-world applications of machine learning. From medical images to text processing, traditional machine learning algorithms are usually unsuccessful in learning the best possible concept from such data. In a previous work, we proposed a dissimilarity-based approach for multi-view classification, the Random Forest Dissimilarity (RFD), that perfoms state-of-the-art results for such problems. In this work, we transpose the core principle of this approach to solving HDLSS classification problems, by using the RF similarity measure as a learned precomputed SVM kernel (RFSVM). We show that such a learned similarity measure is particularly suited and accurate for this classification context. Experiments conducted on 40 public HDLSS classification datasets, supported by rigorous statistical analyses, show that the RFSVM method outperforms existing methods for the majority of HDLSS problems and remains at the same time very competitive for low or non-HDLSS problems.
* 23 pages. To be published in statistics and computing (accepted September 26, 2023)
Multiple Noises in Diffusion Model for Semi-Supervised Multi-Domain Translation
Sep 25, 2023Domain-to-domain translation involves generating a target domain sample given a condition in the source domain. Most existing methods focus on fixed input and output domains, i.e. they only work for specific configurations (i.e. for two domains, either $D_1\rightarrow{}D_2$ or $D_2\rightarrow{}D_1$). This paper proposes Multi-Domain Diffusion (MDD), a conditional diffusion framework for multi-domain translation in a semi-supervised context. Unlike previous methods, MDD does not require defining input and output domains, allowing translation between any partition of domains within a set (such as $(D_1, D_2)\rightarrow{}D_3$, $D_2\rightarrow{}(D_1, D_3)$, $D_3\rightarrow{}D_1$, etc. for 3 domains), without the need to train separate models for each domain configuration. The key idea behind MDD is to leverage the noise formulation of diffusion models by incorporating one noise level per domain, which allows missing domains to be modeled with noise in a natural way. This transforms the training task from a simple reconstruction task to a domain translation task, where the model relies on less noisy domains to reconstruct more noisy domains. We present results on a multi-domain (with more than two domains) synthetic image translation dataset with challenging semantic domain inversion.
Towards Long-Term predictions of Turbulence using Neural Operators
Jul 25, 2023



This paper explores Neural Operators to predict turbulent flows, focusing on the Fourier Neural Operator (FNO) model. It aims to develop reduced-order/surrogate models for turbulent flow simulations using Machine Learning. Different model configurations are analyzed, with U-NET structures (UNO and U-FNET) performing better than the standard FNO in accuracy and stability. U-FNET excels in predicting turbulence at higher Reynolds numbers. Regularization terms, like gradient and stability losses, are essential for stable and accurate predictions. The study emphasizes the need for improved metrics for deep learning models in fluid flow prediction. Further research should focus on models handling complex flows and practical benchmarking metrics.
Domain Translation via Latent Space Mapping
Dec 06, 2022In this paper, we investigate the problem of multi-domain translation: given an element $a$ of domain $A$, we would like to generate a corresponding $b$ sample in another domain $B$, and vice versa. Acquiring supervision in multiple domains can be a tedious task, also we propose to learn this translation from one domain to another when supervision is available as a pair $(a,b)\sim A\times B$ and leveraging possible unpaired data when only $a\sim A$ or only $b\sim B$ is available. We introduce a new unified framework called Latent Space Mapping (\model) that exploits the manifold assumption in order to learn, from each domain, a latent space. Unlike existing approaches, we propose to further regularize each latent space using available domains by learning each dependency between pairs of domains. We evaluate our approach in three tasks performing i) synthetic dataset with image translation, ii) real-world task of semantic segmentation for medical images, and iii) real-world task of facial landmark detection.
Random Forest for Dissimilarity-based Multi-view Learning
Jul 16, 2020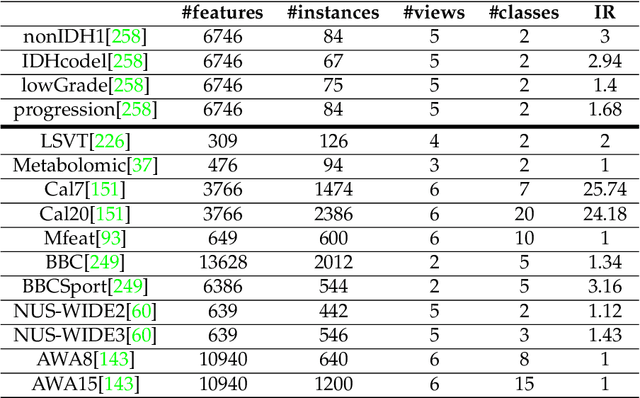
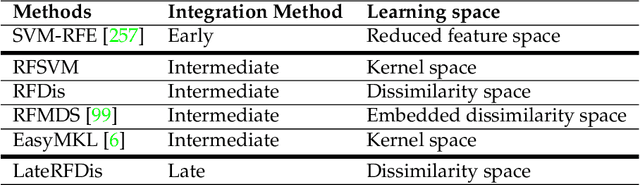
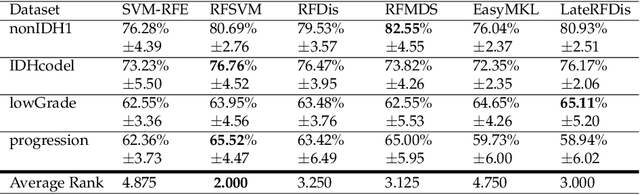
Many classification problems are naturally multi-view in the sense their data are described through multiple heterogeneous descriptions. For such tasks, dissimilarity strategies are effective ways to make the different descriptions comparable and to easily merge them, by (i) building intermediate dissimilarity representations for each view and (ii) fusing these representations by averaging the dissimilarities over the views. In this work, we show that the Random Forest proximity measure can be used to build the dissimilarity representations, since this measure reflects similarities between features but also class membership. We then propose a Dynamic View Selection method to better combine the view-specific dissimilarity representations. This allows to take a decision, on each instance to predict, with only the most relevant views for that instance. Experiments are conducted on several real-world multi-view datasets, and show that the Dynamic View Selection offers a significant improvement in performance compared to the simple average combination and two state-of-the-art static view combinations.
A Novel Random Forest Dissimilarity Measure for Multi-View Learning
Jul 06, 2020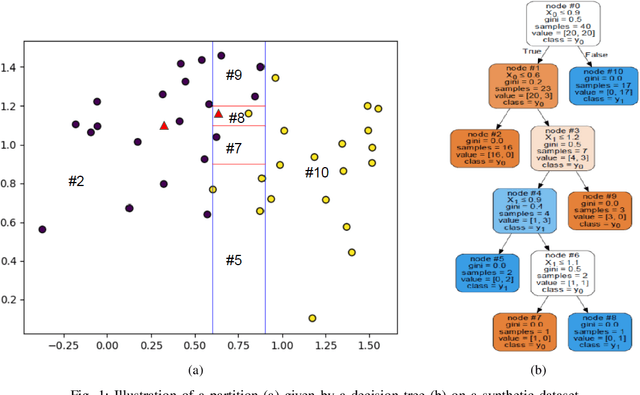
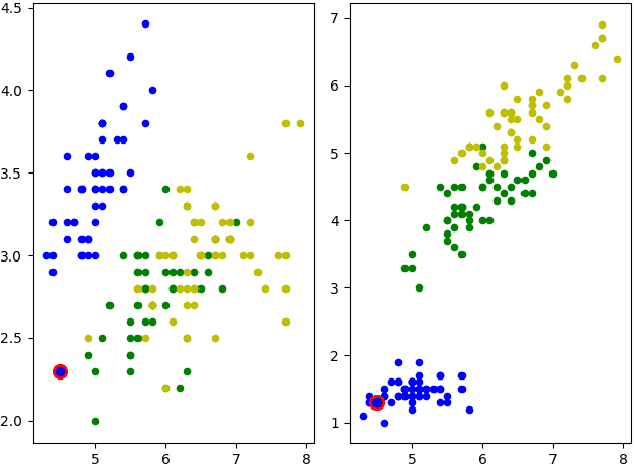
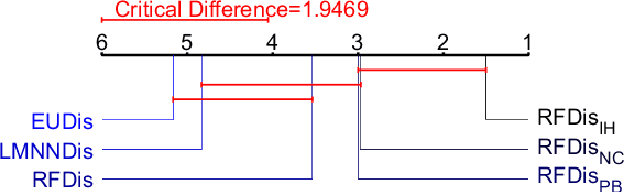
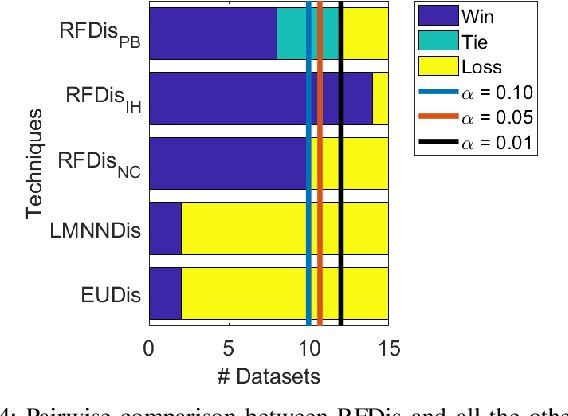
Multi-view learning is a learning task in which data is described by several concurrent representations. Its main challenge is most often to exploit the complementarities between these representations to help solve a classification/regression task. This is a challenge that can be met nowadays if there is a large amount of data available for learning. However, this is not necessarily true for all real-world problems, where data are sometimes scarce (e.g. problems related to the medical environment). In these situations, an effective strategy is to use intermediate representations based on the dissimilarities between instances. This work presents new ways of constructing these dissimilarity representations, learning them from data with Random Forest classifiers. More precisely, two methods are proposed, which modify the Random Forest proximity measure, to adapt it to the context of High Dimension Low Sample Size (HDLSS) multi-view classification problems. The second method, based on an Instance Hardness measurement, is significantly more accurate than other state-of-the-art measurements including the original RF Proximity measurement and the Large Margin Nearest Neighbor (LMNN) metric learning measurement.
Dynamic voting in multi-view learning for radiomics applications
Jun 26, 2018
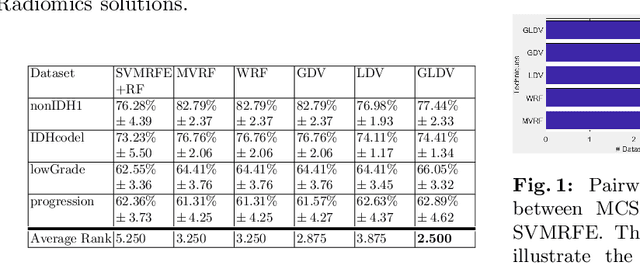
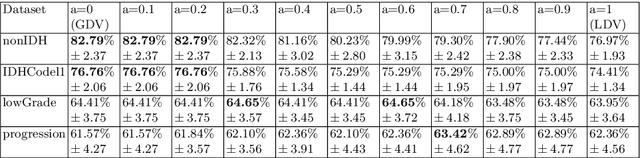
Cancer diagnosis and treatment often require a personalized analysis for each patient nowadays, due to the heterogeneity among the different types of tumor and among patients. Radiomics is a recent medical imaging field that has shown during the past few years to be promising for achieving this personalization. However, a recent study shows that most of the state-of-the-art works in Radiomics fail to identify this problem as a multi-view learning task and that multi-view learning techniques are generally more efficient. In this work, we propose to further investigate the potential of one family of multi-view learning methods based on Multiple Classifiers Systems where one classifier is learnt on each view and all classifiers are combined afterwards. In particular, we propose a random forest based dynamic weighted voting scheme, which personalizes the combination of views for each new patient for classification tasks. The proposed method is validated on several real-world Radiomics problems.
Improve the performance of transfer learning without fine-tuning using dissimilarity-based multi-view learning for breast cancer histology images
Mar 29, 2018

Breast cancer is one of the most common types of cancer and leading cancer-related death causes for women. In the context of ICIAR 2018 Grand Challenge on Breast Cancer Histology Images, we compare one handcrafted feature extractor and five transfer learning feature extractors based on deep learning. We find out that the deep learning networks pretrained on ImageNet have better performance than the popular handcrafted features used for breast cancer histology images. The best feature extractor achieves an average accuracy of 79.30%. To improve the classification performance, a random forest dissimilarity based integration method is used to combine different feature groups together. When the five deep learning feature groups are combined, the average accuracy is improved to 82.90% (best accuracy 85.00%). When handcrafted features are combined with the five deep learning feature groups, the average accuracy is improved to 87.10% (best accuracy 93.00%).