 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Forest Dissimilarity for High-Dimension Low Sample Size Classification
Oct 23, 2023High dimension, low sample size (HDLSS) problems are numerous among real-world applications of machine learning. From medical images to text processing, traditional machine learning algorithms are usually unsuccessful in learning the best possible concept from such data. In a previous work, we proposed a dissimilarity-based approach for multi-view classification, the Random Forest Dissimilarity (RFD), that perfoms state-of-the-art results for such problems. In this work, we transpose the core principle of this approach to solving HDLSS classification problems, by using the RF similarity measure as a learned precomputed SVM kernel (RFSVM). We show that such a learned similarity measure is particularly suited and accurate for this classification context. Experiments conducted on 40 public HDLSS classification datasets, supported by rigorous statistical analyses, show that the RFSVM method outperforms existing methods for the majority of HDLSS problems and remains at the same time very competitive for low or non-HDLSS problems.
* 23 pages. To be published in statistics and computing (accepted September 26, 2023)
scikit-dyn2sel -- A Dynamic Selection Framework for Data Streams
Aug 17, 2020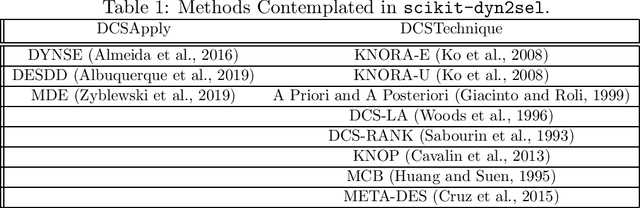

Mining data streams is a challenge per se. It must be ready to deal with an enormous amount of data and with problems not present in batch machine learning, such as concept drift. Therefore, applying a batch-designed technique, such as dynamic selection of classifiers (DCS) also presents a challenge. The dynamic characteristic of ensembles that deal with streams presents barriers to the application of traditional DCS techniques in such classifiers. scikit-dyn2sel is an open-source python library tailored for dynamic selection techniques in streaming data. scikit-dyn2sel's development follows code quality and testing standards, including PEP8 compliance and automated high test coverage using codecov.io and circleci.com. Source code, documentation, and examples are made available on GitHub at https://github.com/luccaportes/Scikit-DYN2SEL.