 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Modality and View Selection for Multimodal Emotion Recognition with Missing Modalities
Apr 18, 2024



The study of human emotions, traditionally a cornerstone in fields like psychology and neuroscience, has been profoundly impacted by the advent of artificial intelligence (AI). Multiple channels, such as speech (voice) and facial expressions (image), are crucial in understanding human emotions. However, AI's journey in multimodal emotion recognition (MER) is marked by substantial technical challenges. One significant hurdle is how AI models manage the absence of a particular modality - a frequent occurrence in real-world situations. This study's central focus is assessing the performance and resilience of two strategies when confronted with the lack of one modality: a novel multimodal dynamic modality and view selection and a cross-attention mechanism. Results on the RECOLA dataset show that dynamic selection-based methods are a promising approach for MER. In the missing modalities scenarios, all dynamic selection-based methods outperformed the baseline. The study concludes by emphasizing the intricate interplay between audio and video modalities in emotion prediction, showcasing the adaptability of dynamic selection methods in handling missing modalities.
Methods for Generating Drift in Text Streams
Mar 18, 2024



Systems and individuals produce data continuously. On the Internet, people share their knowledge, sentiments, and opinions, provide reviews about services and products, and so on. Automatically learning from these textual data can provide insights to organizations and institutions, thus preventing financial impacts, for example. To learn from textual data over time, the machine learning system must account for concept drift. Concept drift is a frequent phenomenon in real-world datasets and corresponds to changes in data distribution over time. For instance, a concept drift occurs when sentiments change or a word's meaning is adjusted over time. Although concept drift is frequent in real-world applications, benchmark datasets with labeled drifts are rare in the literature. To bridge this gap, this paper provides four textual drift generation methods to ease the production of datasets with labeled drifts. These methods were applied to Yelp and Airbnb datasets and tested using incremental classifiers respecting the stream mining paradigm to evaluate their ability to recover from the drifts. Results show that all methods have their performance degraded right after the drifts, and the incremental SVM is the fastest to run and recover the previous performance levels regarding accuracy and Macro F1-Score.
Improving Sampling Methods for Fine-tuning SentenceBERT in Text Streams
Mar 18, 2024



The proliferation of textual data on the Internet presents a unique opportunity for institutions and companies to monitor public opinion about their services and products. Given the rapid generation of such data, the text stream mining setting, which handles sequentially arriving, potentially infinite text streams, is often more suitable than traditional batch learning. While pre-trained language models are commonly employed for their high-quality text vectorization capabilities in streaming contexts, they face challenges adapting to concept drift - the phenomenon where the data distribution changes over time, adversely affecting model performance. Addressing the issue of concept drift, this study explores the efficacy of seven text sampling methods designed to selectively fine-tune language models, thereby mitigating performance degradation. We precisely assess the impact of these methods on fine-tuning the SBERT model using four different loss functions. Our evaluation, focused on Macro F1-score and elapsed time, employs two text stream datasets and an incremental SVM classifier to benchmark performance. Our findings indicate that Softmax loss and Batch All Triplets loss are particularly effective for text stream classification, demonstrating that larger sample sizes generally correlate with improved macro F1-scores. Notably, our proposed WordPieceToken ratio sampling method significantly enhances performance with the identified loss functions, surpassing baseline results.
Temporal Analysis of Drifting Hashtags in Textual Data Streams: A Graph-Based Application
Feb 08, 2024Social media has played an important role since its emergence. People use the internet to express opinions about anything, making social media platforms a social sensor. Initially supported by Twitter, the hashtags are now in use on several social media platforms. Hashtags are helpful to tag, track, and group posts on similar topics. In this paper, we analyze hashtag drifts over time using concepts from graph analysis and textual data streams using the Girvan-Newman method to uncover hashtag communities in annual snapshots. More specifically, we analyzed the #mybodymychoice hashtag between 2018 and 2022. In addition, we offer insights about some hashtags found in the study. Furthermore, our approach can be useful for monitoring changes over time in opinions and sentiment patterns about an entity on social media. Even though the hashtag #mybodymychoice was initially coupled with women's rights, abortion, and bodily autonomy, we observe that it suffered drifts during the studied period across topics such as drug legalization, vaccination, political protests, war, and civil rights. The year 2021 was the most significant drifting year, in which the communities detected suggest that #mybodymychoice significantly drifted to vaccination and Covid-19-related topics.
Distance Functions and Normalization Under Stream Scenarios
Jul 04, 2023



Data normalization is an essential task when modeling a classification system. When dealing with data streams, data normalization becomes especially challenging since we may not know in advance the properties of the features, such as their minimum/maximum values, and these properties may change over time. We compare the accuracies generated by eight well-known distance functions in data streams without normalization, normalized considering the statistics of the first batch of data received, and considering the previous batch received. We argue that experimental protocols for streams that consider the full stream as normalized are unrealistic and can lead to biased and poor results. Our results indicate that using the original data stream without applying normalization, and the Canberra distance, can be a good combination when no information about the data stream is known beforehand.
scikit-dyn2sel -- A Dynamic Selection Framework for Data Streams
Aug 17, 2020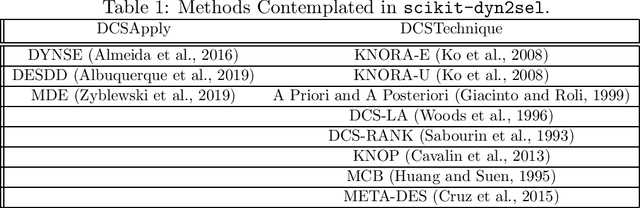

Mining data streams is a challenge per se. It must be ready to deal with an enormous amount of data and with problems not present in batch machine learning, such as concept drift. Therefore, applying a batch-designed technique, such as dynamic selection of classifiers (DCS) also presents a challenge. The dynamic characteristic of ensembles that deal with streams presents barriers to the application of traditional DCS techniques in such classifiers. scikit-dyn2sel is an open-source python library tailored for dynamic selection techniques in streaming data. scikit-dyn2sel's development follows code quality and testing standards, including PEP8 compliance and automated high test coverage using codecov.io and circleci.com. Source code, documentation, and examples are made available on GitHub at https://github.com/luccaportes/Scikit-DYN2SEL.
Multi-label Classification of User Reactions in Online News
Sep 08, 2018
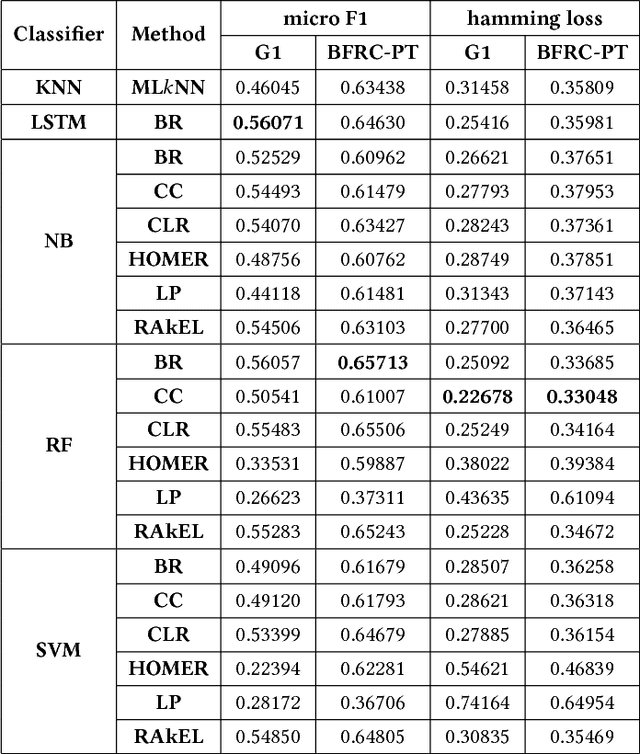
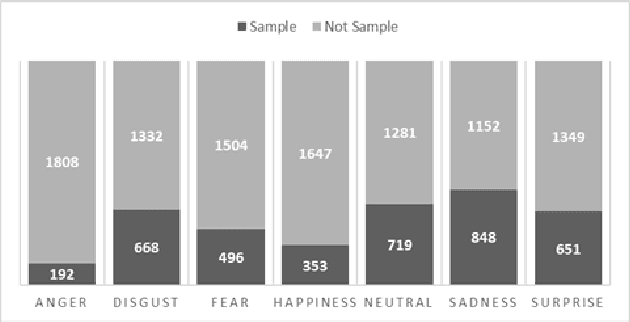
The increase in the number of Internet users and the strong interaction brought by Web 2.0 made the Opinion Mining an important task in the area of natural language processing. Although several methods are capable of performing this task, few use multi-label classification, where there is a group of true labels for each example. This type of classification is useful for situations where the opinions are analyzed from the perspective of the reader. Recently, Deep Learning has been registering the state of the art in several single-label problems. This paper discuss the efficiency of the Long Short-Term Memory compared to traditional multi-label classification approaches. To do that, extensive tests were carried out on two news corpora written in Brazilian Portuguese annotated with reactions. A new corpus called BFRC-PT is presented. In the tests performed, the highest number of correct predictions was obtained with the Classifier Chains method combined with the Random Forest algorithm. When considering the class distribution, the best results were obtained with the Binary Relevance method combined with the LSTM and Random Forest algorithms.