 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Task Completion: Revealing Corrupt Success in LLM Agents through Procedure-Aware Evaluation
Mar 03, 2026Large Language Model (LLM)-based agents are increasingly adopted in high-stakes settings, but current benchmarks evaluate mainly whether a task was completed, not how. We introduce Procedure-Aware Evaluation (PAE), a framework that formalizes agent procedures as structured observations and exposes consistency relationships between what agents observe, communicate, and execute. PAE evaluates agents along complementary axes (Utility, Efficiency, Interaction Quality, Procedural Integrity) and applies multi-dimensional gating that categorically disqualifies corrupt outcomes. Evaluating state-of-the-art LLM agents on tau-bench yields findings at the axis, compliance, and benchmark levels. At the axis level, the dimensions capture non-redundant failure modes: utility masks reliability gaps, speed does not imply precision, and conciseness does not predict intent adherence. At the procedural compliance level, 27-78% of benchmark reported successes are corrupt successes concealing violations across interaction and integrity. Furthermore, gating substantially collapses Pass^4 rate and affects model rankings. The analysis of corrupt success cases reveals distinctive per-model failure signatures: GPT-5 spreads errors across policy, execution, and intent dimensions; Kimi-K2-Thinking concentrates 78% of violations in policy faithfulness and compliance; and Mistral-Large-3 is dominated by faithfulness failures. At the benchmark level, our analysis exposes structural flaws in the benchmark design, including task scope gaps, contradictory reward signals, and simulator artifacts that produce accidental successes.
Diverse And Private Synthetic Datasets Generation for RAG evaluation: A multi-agent framework
Aug 26, 2025Retrieval-augmented generation (RAG) systems improve large language model outputs by incorporating external knowledge, enabling more informed and context-aware responses. However, the effectiveness and trustworthiness of these systems critically depends on how they are evaluated, particularly on whether the evaluation process captures real-world constraints like protecting sensitive information. While current evaluation efforts for RAG systems have primarily focused on the development of performance metrics, far less attention has been given to the design and quality of the underlying evaluation datasets, despite their pivotal role in enabling meaningful, reliable assessments. In this work, we introduce a novel multi-agent framework for generating synthetic QA datasets for RAG evaluation that prioritize semantic diversity and privacy preservation. Our approach involves: (1) a Diversity agent leveraging clustering techniques to maximize topical coverage and semantic variability, (2) a Privacy Agent that detects and mask sensitive information across multiple domains and (3) a QA curation agent that synthesizes private and diverse QA pairs suitable as ground truth for RAG evaluation. Extensive experiments demonstrate that our evaluation sets outperform baseline methods in diversity and achieve robust privacy masking on domain-specific datasets. This work offers a practical and ethically aligned pathway toward safer, more comprehensive RAG system evaluation, laying the foundation for future enhancements aligned with evolving AI regulations and compliance standards.
Enhancing Negation Awareness in Universal Text Embeddings: A Data-efficient and Computational-efficient Approach
Apr 01, 2025
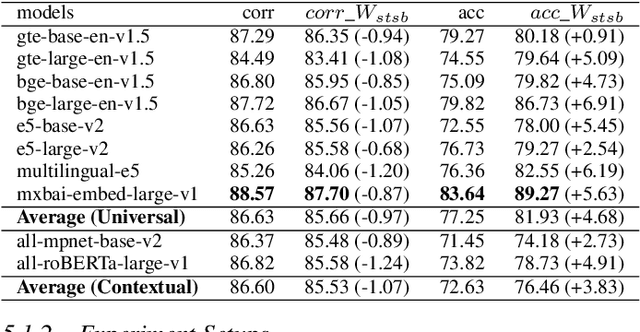

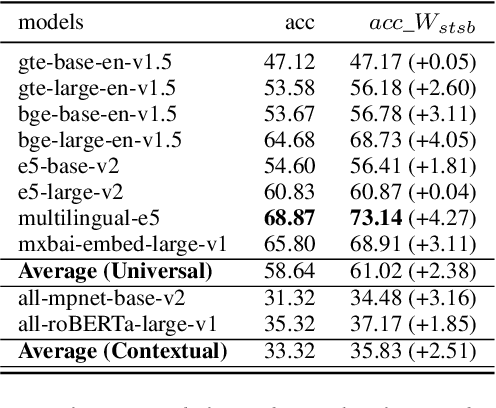
Negation plays an important role in various natural language processing tasks such as Natural Language Inference and Sentiment Analysis tasks. Numerous prior studies have found that contextual text embedding models such as BERT, ELMO, RoBERTa or XLNet face challenges in accurately understanding negation. Recent advancements in universal text embeddings have demonstrated superior performance over contextual text embeddings in various tasks. However, due to the bias in popular evaluation benchmarks, the negation awareness capacity of these models remains unclear. To bridge the gap in existing literature, an in-depth analysis is initiated in this work to study the negation awareness of cutting-edge universal text embedding models. Our findings reveal a significant lack of negation awareness in these models, often interpreting negated text pairs as semantically similar. To efficiently deal with the conflict that different tasks need different trade-offs between topic and negation information among other semantic information, a data-efficient and computational-efficient embedding re-weighting method is proposed without modifying the parameters of text embedding models. The proposed solution is able to improve text embedding models' negation awareness significantly on both simple negation understanding task and complex negation understanding task. Furthermore, the proposed solution can also significantly improve the negation awareness of Large Language Model based task-specific high dimensional universal text embeddings.
Writing Style Matters: An Examination of Bias and Fairness in Information Retrieval Systems
Nov 20, 2024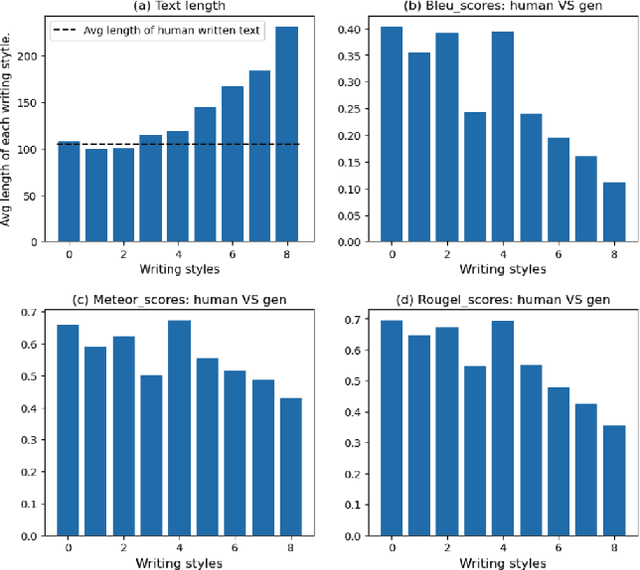
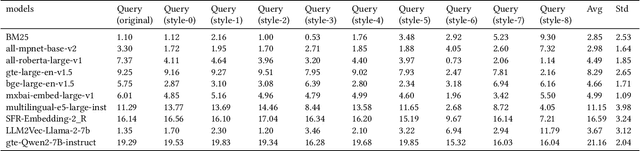
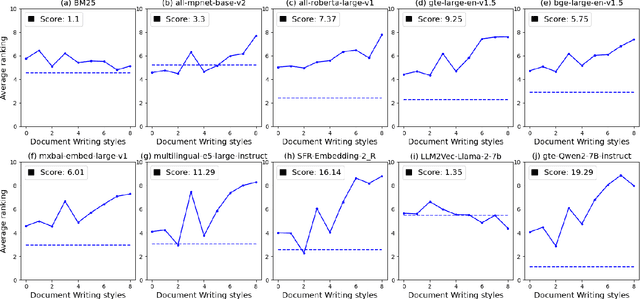
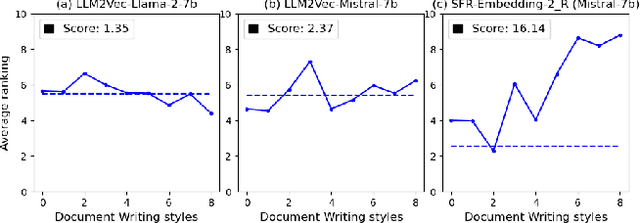
The rapid advancement of Language Model technologies has opened new opportunities, but also introduced new challenges related to bias and fairness. This paper explores the uncharted territory of potential biases in state-of-the-art universal text embedding models towards specific document and query writing styles within Information Retrieval (IR) systems. Our investigation reveals that different embedding models exhibit different preferences of document writing style, while more informal and emotive styles are less favored by most embedding models. In terms of query writing styles, many embedding models tend to match the style of the query with the style of the retrieved documents, but some show a consistent preference for specific styles. Text embedding models fine-tuned on synthetic data generated by LLMs display a consistent preference for certain style of generated data. These biases in text embedding based IR systems can inadvertently silence or marginalize certain communication styles, thereby posing a significant threat to fairness in information retrieval. Finally, we also compare the answer styles of Retrieval Augmented Generation (RAG) systems based on different LLMs and find out that most text embedding models are biased towards LLM's answer styles when used as evaluation metrics for answer correctness. This study sheds light on the critical issue of writing style based bias in IR systems, offering valuable insights for the development of more fair and robust models.
Recent advances in text embedding: A Comprehensive Review of Top-Performing Methods on the MTEB Benchmark
May 27, 2024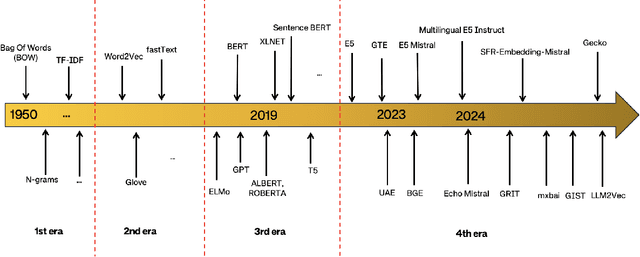
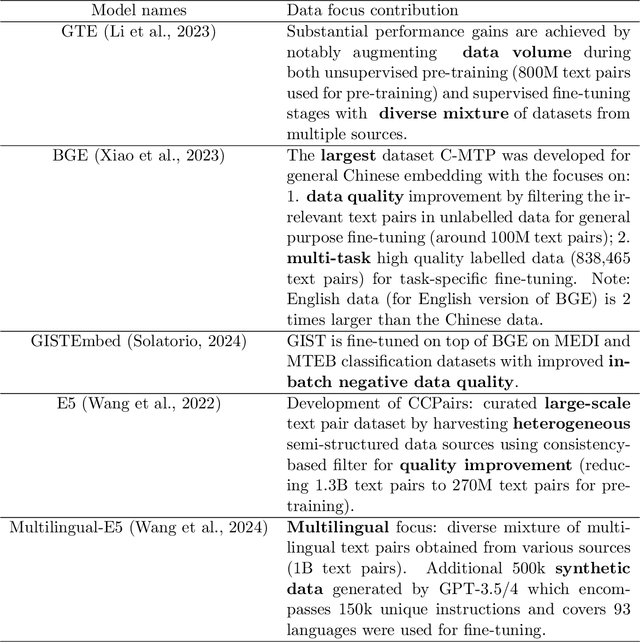
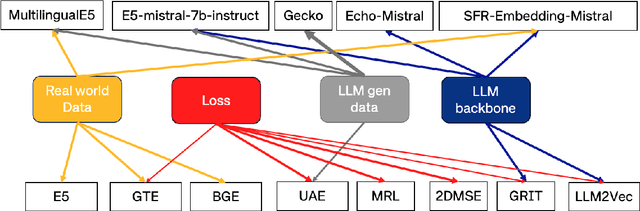
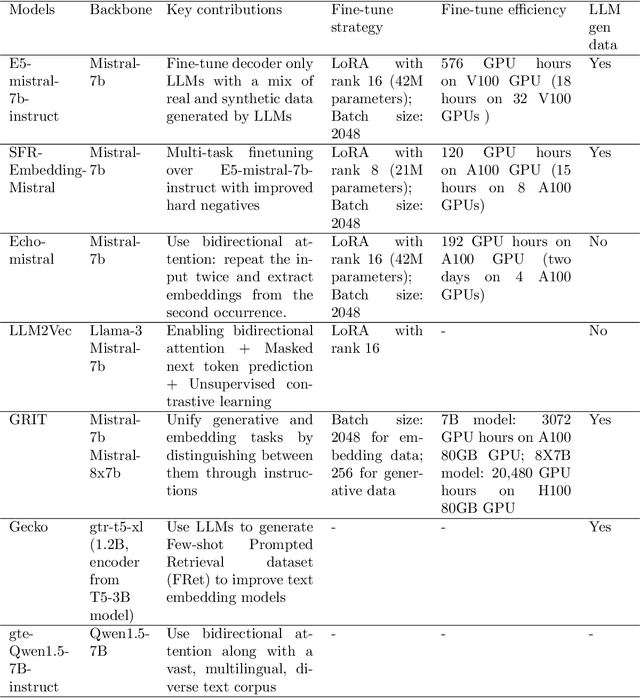
Text embedding methods have become increasingly popular in both industrial and academic fields due to their critical role in a variety of natural language processing tasks. The significance of universal text embeddings has been further highlighted with the rise of Large Language Models (LLMs) applications such as Retrieval-Augmented Systems (RAGs). While previous models have attempted to be general-purpose, they often struggle to generalize across tasks and domains. However, recent advancements in training data quantity, quality and diversity; synthetic data generation from LLMs as well as using LLMs as backbones encourage great improvements in pursuing universal text embeddings. In this paper, we provide an overview of the recent advances in universal text embedding models with a focus on the top performing text embeddings on Massive Text Embedding Benchmark (MTEB). Through detailed comparison and analysis, we highlight the key contributions and limitations in this area, and propose potentially inspiring future research directions.
Inclusive normalization of face images to passport format
Dec 22, 2023Face recognition has been used more and more in real world applications in recent years. However, when the skin color bias is coupled with intra-personal variations like harsh illumination, the face recognition task is more likely to fail, even during human inspection. Face normalization methods try to deal with such challenges by removing intra-personal variations from an input image while keeping the identity the same. However, most face normalization methods can only remove one or two variations and ignore dataset biases such as skin color bias. The outputs of many face normalization methods are also not realistic to human observers. In this work, a style based face normalization model (StyleFNM) is proposed to remove most intra-personal variations including large changes in pose, bad or harsh illumination, low resolution, blur, facial expressions, and accessories like sunglasses among others. The dataset bias is also dealt with in this paper by controlling a pretrained GAN to generate a balanced dataset of passport-like images. The experimental results show that StyleFNM can generate more realistic outputs and can improve significantly the accuracy and fairness of face recognition systems.
Multi-view user representation learning for user matching without personal information
Dec 22, 2023



As the digitization of travel industry accelerates, analyzing and understanding travelers' behaviors becomes increasingly important. However, traveler data frequently exhibit high data sparsity due to the relatively low frequency of user interactions with travel providers. Compounding this effect the multiplication of devices, accounts and platforms while browsing travel products online also leads to data dispersion. To deal with these challenges, probabilistic traveler matching can be used. Most existing solutions for user matching are not suitable for traveler matching as a traveler's browsing history is typically short and URLs in the travel industry are very heterogeneous with many tokens. To deal with these challenges, we propose the similarity based multi-view information fusion to learn a better user representation from URLs by treating the URLs as multi-view data. The experimental results show that the proposed multi-view user representation learning can take advantage of the complementary information from different views, highlight the key information in URLs and perform significantly better than other representation learning solutions for the user matching task.
Towards more sustainable enterprise data and application management with cross silo Federated Learning and Analytics
Dec 22, 2023To comply with new legal requirements and policies committed to privacy protection, more and more companies start to deploy cross-silo Federated Learning at global scale, where several clients/silos collaboratively train a global model under the coordination of a central server. Instead of data sharing and transmission, clients train models using their private local data and exchange model updates. However, there is little understanding of the carbon emission impact of cross silo Federated Learning due to the lack of related works. In this study, we first analyze the sustainability aspect of cross-silo Federated Learning, across the AI product life cycle instead of focusing only on the model training, with the comparison to the centralized method. A more holistic quantitative cost and CO2 emission estimation method for real world cross-silo Federated Learning setting is proposed. Secondly, we propose a novel data and application management system using cross silo Federated Learning and analytics to make IT companies more sustainable and cost effective.
Destination similarity based on implicit user interest
Feb 18, 2021
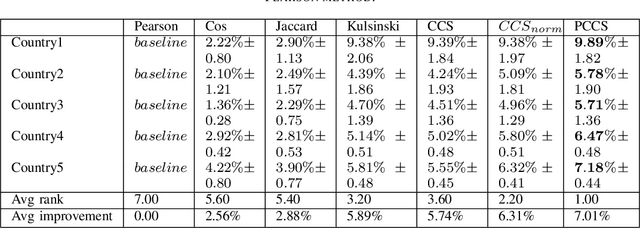

With the digitization of travel industry, it is more and more important to understand users from their online behaviors. However, online travel industry data are more challenging to analyze due to extra sparseness, dispersed user history actions, fast change of user interest and lack of direct or indirect feedbacks. In this work, a new similarity method is proposed to measure the destination similarity in terms of implicit user interest. By comparing the proposed method to several other widely used similarity measures in recommender systems, the proposed method achieves a significant improvement on travel data. Key words: Destination similarity, Travel industry, Recommender System, Implicit user interest
Random Forest for Dissimilarity-based Multi-view Learning
Jul 16, 2020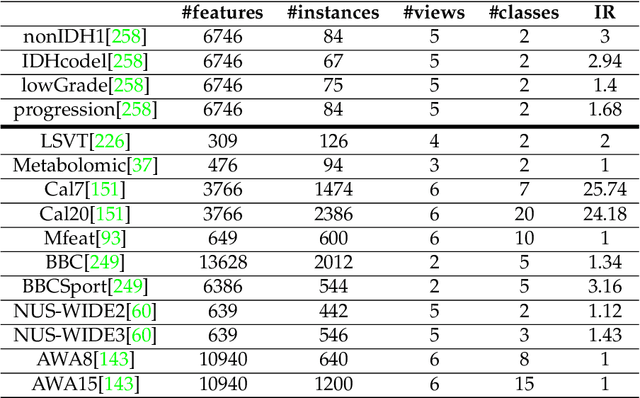
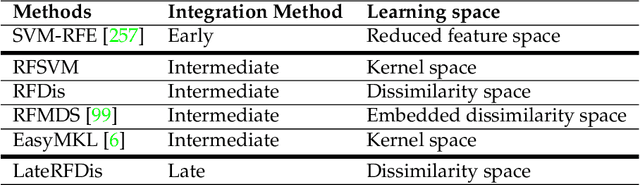
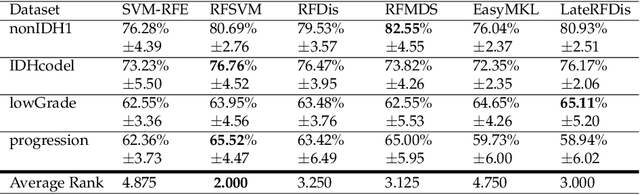
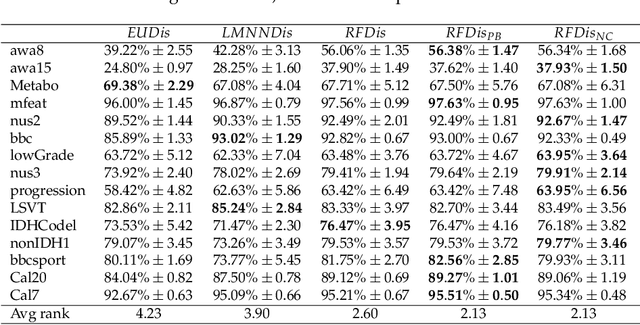
Many classification problems are naturally multi-view in the sense their data are described through multiple heterogeneous descriptions. For such tasks, dissimilarity strategies are effective ways to make the different descriptions comparable and to easily merge them, by (i) building intermediate dissimilarity representations for each view and (ii) fusing these representations by averaging the dissimilarities over the views. In this work, we show that the Random Forest proximity measure can be used to build the dissimilarity representations, since this measure reflects similarities between features but also class membership. We then propose a Dynamic View Selection method to better combine the view-specific dissimilarity representations. This allows to take a decision, on each instance to predict, with only the most relevant views for that instance. Experiments are conducted on several real-world multi-view datasets, and show that the Dynamic View Selection offers a significant improvement in performance compared to the simple average combination and two state-of-the-art static view combinations.