 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWriting Style Matters: An Examination of Bias and Fairness in Information Retrieval Systems
Paper and Code
Nov 20, 2024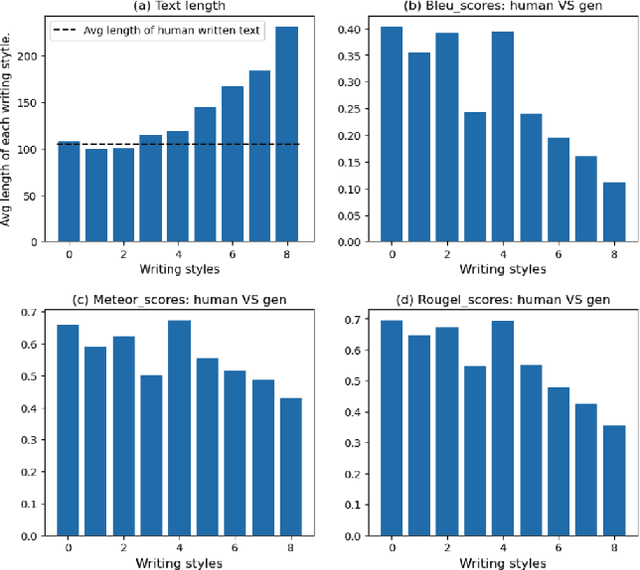
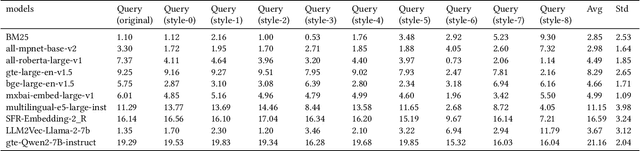
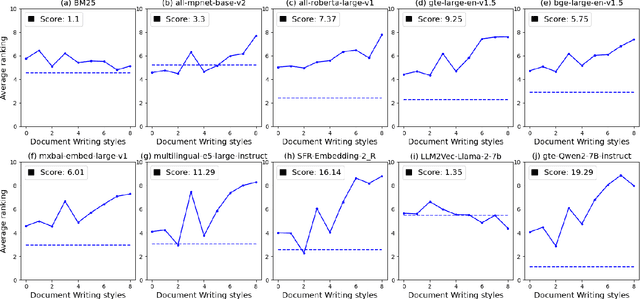
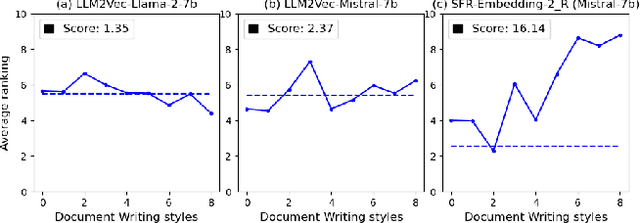
The rapid advancement of Language Model technologies has opened new opportunities, but also introduced new challenges related to bias and fairness. This paper explores the uncharted territory of potential biases in state-of-the-art universal text embedding models towards specific document and query writing styles within Information Retrieval (IR) systems. Our investigation reveals that different embedding models exhibit different preferences of document writing style, while more informal and emotive styles are less favored by most embedding models. In terms of query writing styles, many embedding models tend to match the style of the query with the style of the retrieved documents, but some show a consistent preference for specific styles. Text embedding models fine-tuned on synthetic data generated by LLMs display a consistent preference for certain style of generated data. These biases in text embedding based IR systems can inadvertently silence or marginalize certain communication styles, thereby posing a significant threat to fairness in information retrieval. Finally, we also compare the answer styles of Retrieval Augmented Generation (RAG) systems based on different LLMs and find out that most text embedding models are biased towards LLM's answer styles when used as evaluation metrics for answer correctness. This study sheds light on the critical issue of writing style based bias in IR systems, offering valuable insights for the development of more fair and robust models.