 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgricultural Landscape Understanding At Country-Scale
Nov 08, 2024Agricultural landscapes are quite complex, especially in the Global South where fields are smaller, and agricultural practices are more varied. In this paper we report on our progress in digitizing the agricultural landscape (natural and man-made) in our study region of India. We use high resolution imagery and a UNet style segmentation model to generate the first of its kind national-scale multi-class panoptic segmentation output. Through this work we have been able to identify individual fields across 151.7M hectares, and delineating key features such as water resources and vegetation. We share how this output was validated by our team and externally by downstream users, including some sample use cases that can lead to targeted data driven decision making. We believe this dataset will contribute towards digitizing agriculture by generating the foundational baselayer.
Conciseness: An Overlooked Language Task
Nov 08, 2022



We report on novel investigations into training models that make sentences concise. We define the task and show that it is different from related tasks such as summarization and simplification. For evaluation, we release two test sets, consisting of 2000 sentences each, that were annotated by two and five human annotators, respectively. We demonstrate that conciseness is a difficult task for which zero-shot setups with large neural language models often do not perform well. Given the limitations of these approaches, we propose a synthetic data generation method based on round-trip translations. Using this data to either train Transformers from scratch or fine-tune T5 models yields our strongest baselines that can be further improved by fine-tuning on an artificial conciseness dataset that we derived from multi-annotator machine translation test sets.
Attack Agnostic Statistical Method for Adversarial Detection
Nov 22, 2019
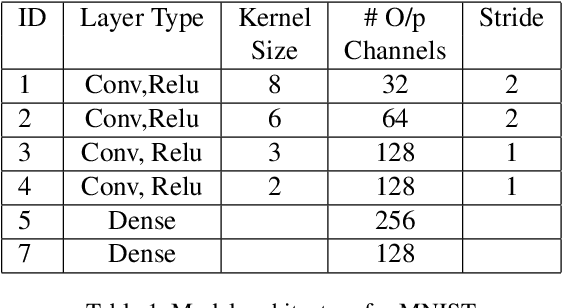
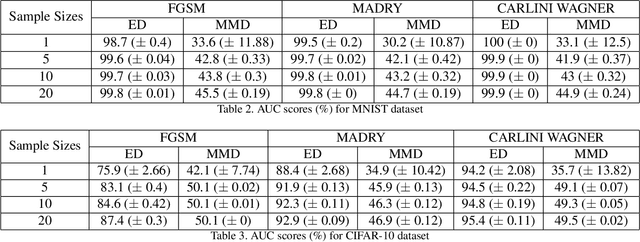
Deep Learning based AI systems have shown great promise in various domains such as vision, audio, autonomous systems (vehicles, drones), etc. Recent research on neural networks has shown the susceptibility of deep networks to adversarial attacks - a technique of adding small perturbations to the inputs which can fool a deep network into misclassifying them. Developing defenses against such adversarial attacks is an active research area, with some approaches proposing robust models that are immune to such adversaries, while other techniques attempt to detect such adversarial inputs. In this paper, we present a novel statistical approach for adversarial detection in image classification. Our approach is based on constructing a per-class feature distribution and detecting adversaries based on comparison of features of a test image with the feature distribution of its class. For this purpose, we make use of various statistical distances such as ED (Energy Distance), MMD (Maximum Mean Discrepancy) for adversarial detection, and analyze the performance of each metric. We experimentally show that our approach achieves good adversarial detection performance on MNIST and CIFAR-10 datasets irrespective of the attack method, sample size and the degree of adversarial perturbation.