 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Block-Level Draft Verification for Accelerating Speculative Decoding
Mar 15, 2024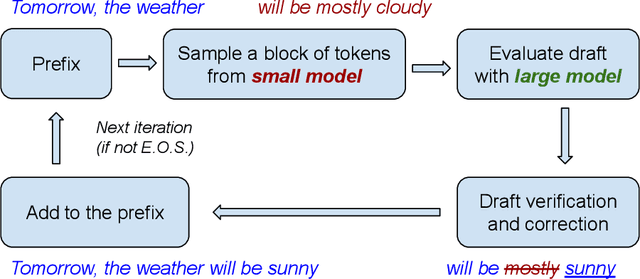



Speculative decoding has shown to be an effective method for lossless acceleration of large language models (LLMs) during inference. In each iteration, the algorithm first uses a smaller model to draft a block of tokens. The tokens are then verified by the large model in parallel and only a subset of tokens will be kept to guarantee that the final output follows the distribution of the large model. In all of the prior speculative decoding works, the draft verification is performed token-by-token independently. In this work, we propose a better draft verification algorithm that provides additional wall-clock speedup without incurring additional computation cost and draft tokens. We first formulate the draft verification step as a block-level optimal transport problem. The block-level formulation allows us to consider a wider range of draft verification algorithms and obtain a higher number of accepted tokens in expectation in one draft block. We propose a verification algorithm that achieves the optimal accepted length for the block-level transport problem. We empirically evaluate our proposed block-level verification algorithm in a wide range of tasks and datasets, and observe consistent improvements in wall-clock speedup when compared to token-level verification algorithm. To the best of our knowledge, our work is the first to establish improvement over speculative decoding through a better draft verification algorithm.
Efficient Language Model Architectures for Differentially Private Federated Learning
Mar 12, 2024



Cross-device federated learning (FL) is a technique that trains a model on data distributed across typically millions of edge devices without data leaving the devices. SGD is the standard client optimizer for on device training in cross-device FL, favored for its memory and computational efficiency. However, in centralized training of neural language models, adaptive optimizers are preferred as they offer improved stability and performance. In light of this, we ask if language models can be modified such that they can be efficiently trained with SGD client optimizers and answer this affirmatively. We propose a scale-invariant Coupled Input Forget Gate (SI CIFG) recurrent network by modifying the sigmoid and tanh activations in the recurrent cell and show that this new model converges faster and achieves better utility than the standard CIFG recurrent model in cross-device FL in large scale experiments. We further show that the proposed scale invariant modification also helps in federated learning of larger transformer models. Finally, we demonstrate the scale invariant modification is also compatible with other non-adaptive algorithms. Particularly, our results suggest an improved privacy utility trade-off in federated learning with differential privacy.
SpecTr: Fast Speculative Decoding via Optimal Transport
Oct 23, 2023



Autoregressive sampling from large language models has led to state-of-the-art results in several natural language tasks. However, autoregressive sampling generates tokens one at a time making it slow, and even prohibitive in certain tasks. One way to speed up sampling is $\textit{speculative decoding}$: use a small model to sample a $\textit{draft}$ (block or sequence of tokens), and then score all tokens in the draft by the large language model in parallel. A subset of the tokens in the draft are accepted (and the rest rejected) based on a statistical method to guarantee that the final output follows the distribution of the large model. In this work, we provide a principled understanding of speculative decoding through the lens of optimal transport (OT) with $\textit{membership cost}$. This framework can be viewed as an extension of the well-known $\textit{maximal-coupling}$ problem. This new formulation enables us to generalize the speculative decoding method to allow for a set of $k$ candidates at the token-level, which leads to an improved optimal membership cost. We show that the optimal draft selection algorithm (transport plan) can be computed via linear programming, whose best-known runtime is exponential in $k$. We then propose a valid draft selection algorithm whose acceptance probability is $(1-1/e)$-optimal multiplicatively. Moreover, it can be computed in time almost linear with size of domain of a single token. Using this $new draft selection$ algorithm, we develop a new autoregressive sampling algorithm called $\textit{SpecTr}$, which provides speedup in decoding while ensuring that there is no quality degradation in the decoded output. We experimentally demonstrate that for state-of-the-art large language models, the proposed approach achieves a wall clock speedup of 2.13X, a further 1.37X speedup over speculative decoding on standard benchmarks.
Correlated quantization for distributed mean estimation and optimization
Mar 09, 2022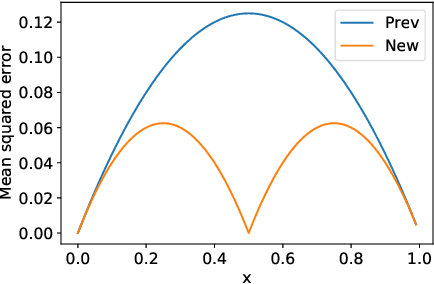
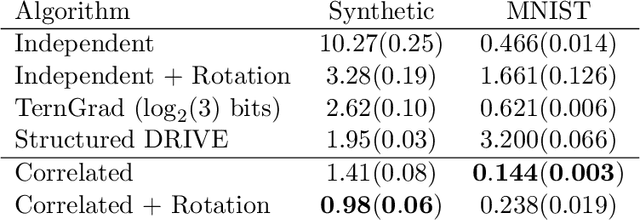
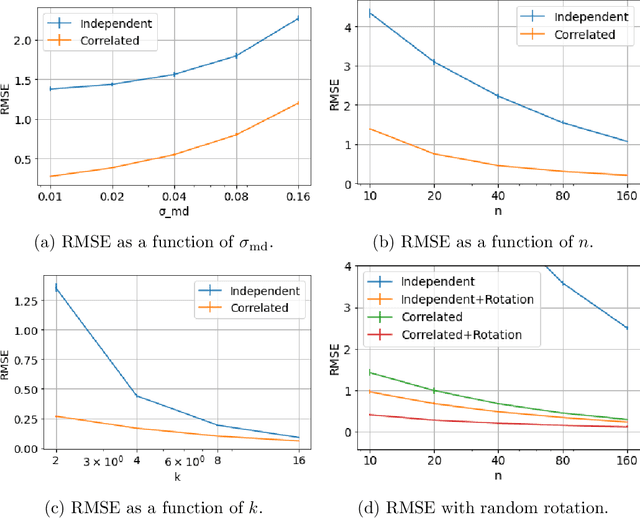

We study the problem of distributed mean estimation and optimization under communication constraints. We propose a correlated quantization protocol whose error guarantee depends on the deviation of data points instead of their absolute range. The design doesn't need any prior knowledge on the concentration property of the dataset, which is required to get such dependence in previous works. We show that applying the proposed protocol as sub-routine in distributed optimization algorithms leads to better convergence rates. We also prove the optimality of our protocol under mild assumptions. Experimental results show that our proposed algorithm outperforms existing mean estimation protocols on a diverse set of tasks.
Transformer-based Models of Text Normalization for Speech Applications
Feb 01, 2022



Text normalization, or the process of transforming text into a consistent, canonical form, is crucial for speech applications such as text-to-speech synthesis (TTS). In TTS, the system must decide whether to verbalize "1995" as "nineteen ninety five" in "born in 1995" or as "one thousand nine hundred ninety five" in "page 1995". We present an experimental comparison of various Transformer-based sequence-to-sequence (seq2seq) models of text normalization for speech and evaluate them on a variety of datasets of written text aligned to its normalized spoken form. These models include variants of the 2-stage RNN-based tagging/seq2seq architecture introduced by Zhang et al. (2019), where we replace the RNN with a Transformer in one or more stages, as well as vanilla Transformers that output string representations of edit sequences. Of our approaches, using Transformers for sentence context encoding within the 2-stage model proved most effective, with the fine-tuned BERT encoder yielding the best performance.
FedJAX: Federated learning simulation with JAX
Aug 04, 2021



Federated learning is a machine learning technique that enables training across decentralized data. Recently, federated learning has become an active area of research due to the increased concerns over privacy and security. In light of this, a variety of open source federated learning libraries have been developed and released. We introduce FedJAX, a JAX-based open source library for federated learning simulations that emphasizes ease-of-use in research. With its simple primitives for implementing federated learning algorithms, prepackaged datasets, models and algorithms, and fast simulation speed, FedJAX aims to make developing and evaluating federated algorithms faster and easier for researchers. Our benchmark results show that FedJAX can be used to train models with federated averaging on the EMNIST dataset in a few minutes and the Stack Overflow dataset in roughly an hour with standard hyperparmeters using TPUs.