 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePERL: Parameter Efficient Reinforcement Learning from Human Feedback
Paper and Code
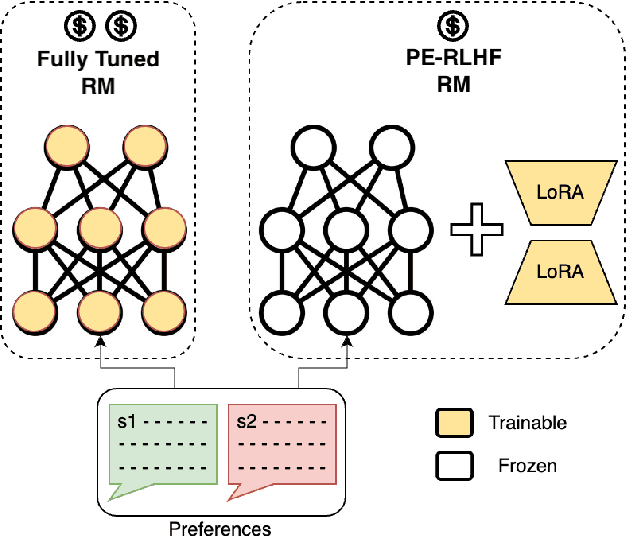
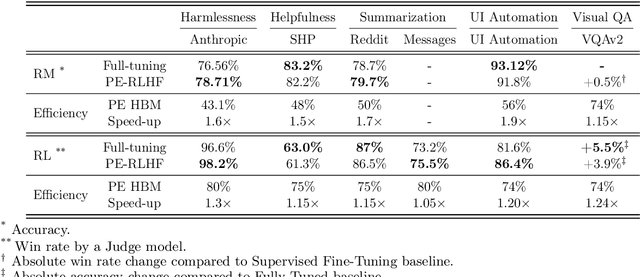
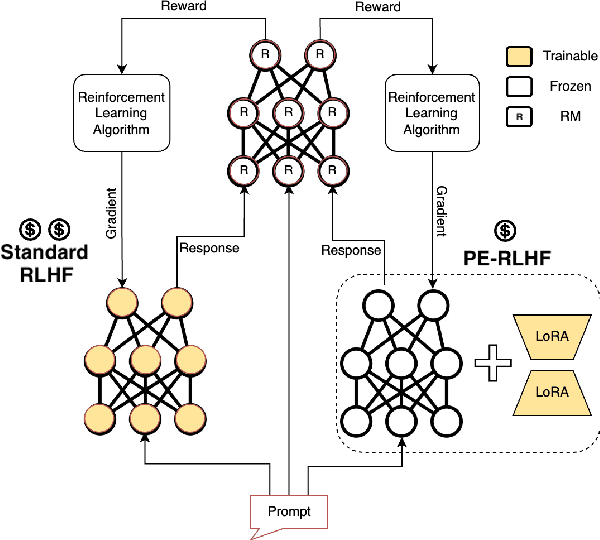
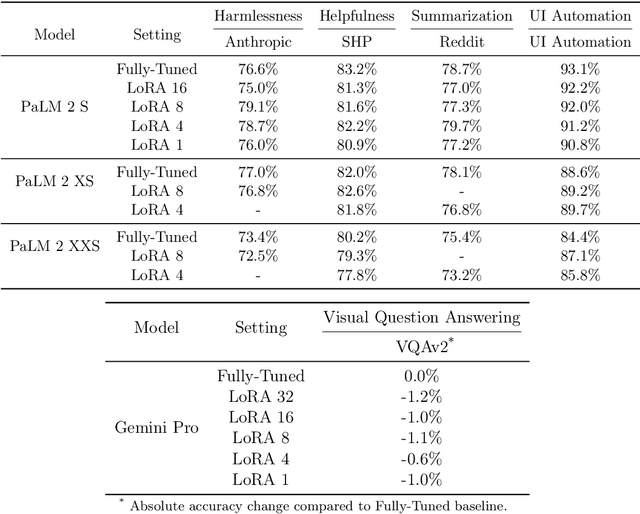
Reinforcement Learning from Human Feedback (RLHF) has proven to be a strong method to align Pretrained Large Language Models (LLMs) with human preferences. But training models with RLHF is computationally expensive, and an overall complex process. In this work, we study RLHF where the underlying models are trained using the parameter efficient method of Low-Rank Adaptation (LoRA) introduced by Hu et al. [2021]. We investigate the setup of "Parameter Efficient Reinforcement Learning" (PERL), in which we perform reward model training and reinforcement learning using LoRA. We compare PERL to conventional fine-tuning (full-tuning) across various configurations for 7 benchmarks, including 2 novel datasets, of reward modeling and reinforcement learning. We find that PERL performs on par with the conventional RLHF setting, while training faster, and with less memory. This enables the high performance of RLHF, while reducing the computational burden that limits its adoption as an alignment technique for Large Language Models. We also release 2 novel thumbs up/down preference datasets: "Taskmaster Coffee", and "Taskmaster Ticketing" to promote research around RLHF.