 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Preference-driven Paradigm for Enhanced Translation with Large Language Models
Paper and Code
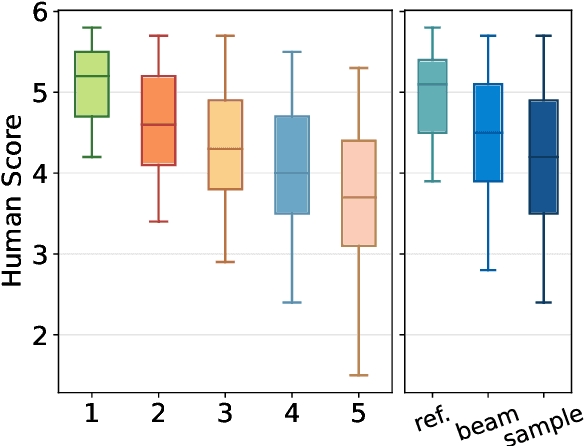

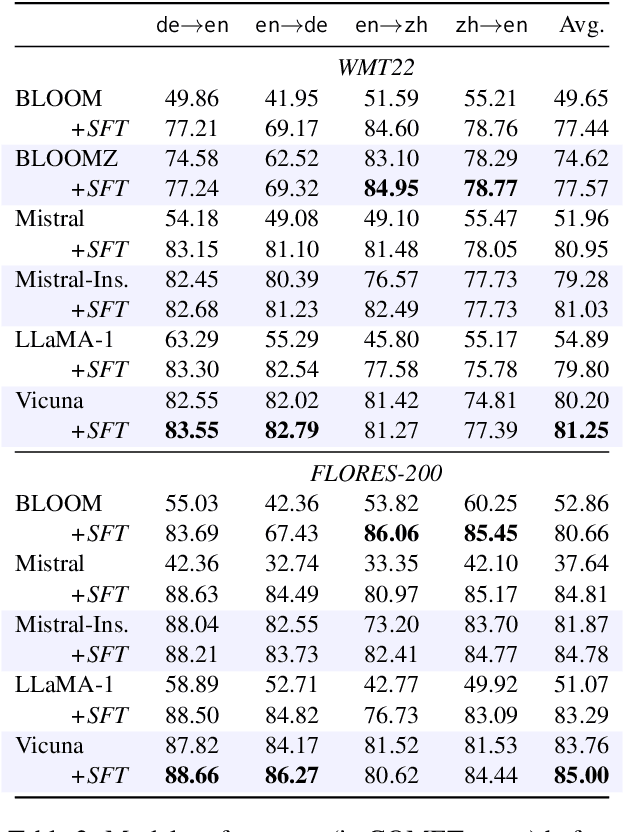

Recent research has shown that large language models (LLMs) can achieve remarkable translation performance through supervised fine-tuning (SFT) using only a small amount of parallel data. However, SFT simply instructs the model to imitate the reference translations at the token level, making it vulnerable to the noise present in the references. Hence, the assistance from SFT often reaches a plateau once the LLMs have achieved a certain level of translation capability, and further increasing the size of parallel data does not provide additional benefits. To overcome this plateau associated with imitation-based SFT, we propose a preference-based approach built upon the Plackett-Luce model. The objective is to steer LLMs towards a more nuanced understanding of translation preferences from a holistic view, while also being more resilient in the absence of gold translations. We further build a dataset named MAPLE to verify the effectiveness of our approach, which includes multiple translations of varying quality for each source sentence. Extensive experiments demonstrate the superiority of our approach in "breaking the plateau" across diverse LLMs and test settings. Our in-depth analysis underscores the pivotal role of diverse translations and accurate preference scores in the success of our approach.