 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidating Large Language Models with ReLM
Paper and Code


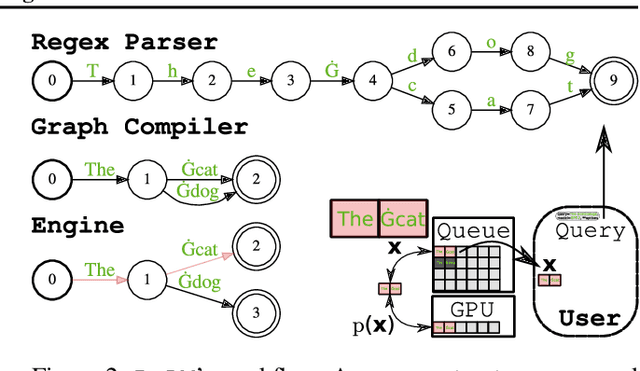

Although large language models (LLMs) have been touted for their ability to generate natural-sounding text, there are growing concerns around possible negative effects of LLMs such as data memorization, bias, and inappropriate language. Unfortunately, the complexity and generation capacities of LLMs make validating (and correcting) such concerns difficult. In this work, we introduce ReLM, a system for validating and querying LLMs using standard regular expressions. ReLM formalizes and enables a broad range of language model evaluations, reducing complex evaluation rules to simple regular expression queries. Our results exploring queries surrounding memorization, gender bias, toxicity, and language understanding show that ReLM achieves up to 15x higher system efficiency, 2.5x data efficiency, and increased statistical and prompt-tuning coverage compared to state-of-the-art ad-hoc queries. ReLM offers a competitive and general baseline for the increasingly important problem of LLM validation.