 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Information Gaps in Dialogues With Grounded Exchanges Using Knowledge Graphs
Aug 02, 2024



Knowledge models are fundamental to dialogue systems for enabling conversational interactions, which require handling domain-specific knowledge. Ensuring effective communication in information-providing conversations entails aligning user understanding with the knowledge available to the system. However, dialogue systems often face challenges arising from semantic inconsistencies in how information is expressed in natural language compared to how it is represented within the system's internal knowledge. To address this problem, we study the potential of large language models for conversational grounding, a mechanism to bridge information gaps by establishing shared knowledge between dialogue participants. Our approach involves annotating human conversations across five knowledge domains to create a new dialogue corpus called BridgeKG. Through a series of experiments on this dataset, we empirically evaluate the capabilities of large language models in classifying grounding acts and identifying grounded information items within a knowledge graph structure. Our findings offer insights into how these models use in-context learning for conversational grounding tasks and common prediction errors, which we illustrate with examples from challenging dialogues. We discuss how the models handle knowledge graphs as a semantic layer between unstructured dialogue utterances and structured information items.
Towards Harnessing Large Language Models for Comprehension of Conversational Grounding
Jun 03, 2024Conversational grounding is a collaborative mechanism for establishing mutual knowledge among participants engaged in a dialogue. This experimental study analyzes information-seeking conversations to investigate the capabilities of large language models in classifying dialogue turns related to explicit or implicit grounding and predicting grounded knowledge elements. Our experimental results reveal challenges encountered by large language models in the two tasks and discuss ongoing research efforts to enhance large language model-based conversational grounding comprehension through pipeline architectures and knowledge bases. These initiatives aim to develop more effective dialogue systems that are better equipped to handle the intricacies of grounded knowledge in conversations.
Evaluating Large Language Models in Semantic Parsing for Conversational Question Answering over Knowledge Graphs
Jan 03, 2024Conversational question answering systems often rely on semantic parsing to enable interactive information retrieval, which involves the generation of structured database queries from a natural language input. For information-seeking conversations about facts stored within a knowledge graph, dialogue utterances are transformed into graph queries in a process that is called knowledge-based conversational question answering. This paper evaluates the performance of large language models that have not been explicitly pre-trained on this task. Through a series of experiments on an extensive benchmark dataset, we compare models of varying sizes with different prompting techniques and identify common issue types in the generated output. Our results demonstrate that large language models are capable of generating graph queries from dialogues, with significant improvements achievable through few-shot prompting and fine-tuning techniques, especially for smaller models that exhibit lower zero-shot performance.
From Data to Dialogue: Leveraging the Structure of Knowledge Graphs for Conversational Exploratory Search
Oct 08, 2023Exploratory search is an open-ended information retrieval process that aims at discovering knowledge about a topic or domain rather than searching for a specific answer or piece of information. Conversational interfaces are particularly suitable for supporting exploratory search, allowing users to refine queries and examine search results through interactive dialogues. In addition to conversational search interfaces, knowledge graphs are also useful in supporting information exploration due to their rich semantic representation of data items. In this study, we demonstrate the synergistic effects of combining knowledge graphs and conversational interfaces for exploratory search, bridging the gap between structured and unstructured information retrieval. To this end, we propose a knowledge-driven dialogue system for exploring news articles by asking natural language questions and using the graph structure to navigate between related topics. Based on a user study with 54 participants, we empirically evaluate the effectiveness of the graph-based exploratory search and discuss design implications for developing such systems.
Voice-Based Conversational Agents and Knowledge Graphs for Improving News Search in Assisted Living
Mar 24, 2023As the healthcare sector is facing major challenges, such as aging populations, staff shortages, and common chronic diseases, delivering high-quality care to individuals has become very difficult. Conversational agents have shown to be a promising technology to alleviate some of these issues. In the form of digital health assistants, they have the potential to improve the everyday life of the elderly and chronically ill people. This includes, for example, medication reminders, routine checks, or social chit-chat. In addition, conversational agents can satisfy the fundamental need of having access to information about daily news or local events, which enables individuals to stay informed and connected with the world around them. However, finding relevant news sources and navigating the plethora of news articles available online can be overwhelming, particularly for those who may have limited technological literacy or health-related impairments. To address this challenge, we propose an innovative solution that combines knowledge graphs and conversational agents for news search in assisted living. By leveraging graph databases to semantically structure news data and implementing an intuitive voice-based interface, our system can help care-dependent people to easily discover relevant news articles and give personalized recommendations. We explain our design choices, provide a system architecture, share insights of an initial user test, and give an outlook on planned future work.
Staircase Network: structural language identification via hierarchical attentive units
Apr 30, 2018

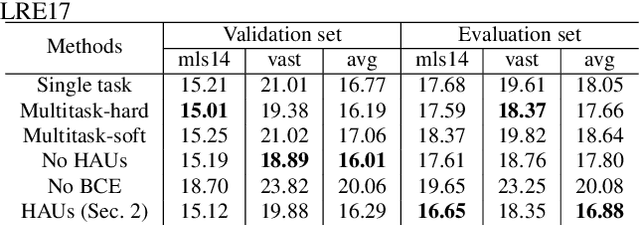
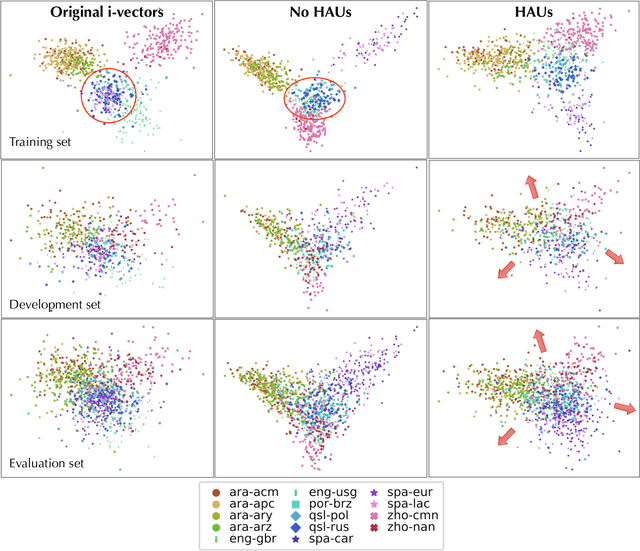
Language recognition system is typically trained directly to optimize classification error on the target language labels, without using the external, or meta-information in the estimation of the model parameters. However labels are not independent of each other, there is a dependency enforced by, for example, the language family, which affects negatively on classification. The other external information sources (e.g. audio encoding, telephony or video speech) can also decrease classification accuracy. In this paper, we attempt to solve these issues by constructing a deep hierarchical neural network, where different levels of meta-information are encapsulated by attentive prediction units and also embedded into the training progress. The proposed method learns auxiliary tasks to obtain robust internal representation and to construct a variant of attentive units within the hierarchical model. The final result is the structural prediction of the target language and a closely related language family. The algorithm reflects a "staircase" way of learning in both its architecture and training, advancing from the fundamental audio encoding to the language family level and finally to the target language level. This process not only improves generalization but also tackles the issues of imbalanced class priors and channel variability in the deep neural network model. Our experimental findings show that the proposed architecture outperforms the state-of-the-art i-vector approaches on both small and big language corpora by a significant margin.