 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStaircase Network: structural language identification via hierarchical attentive units
Paper and Code
Apr 30, 2018

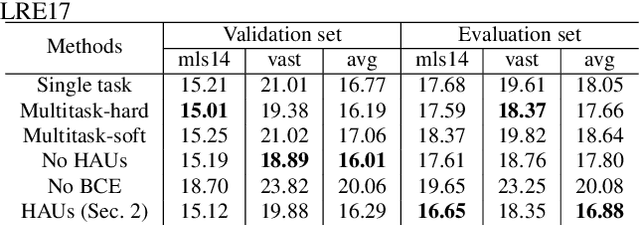
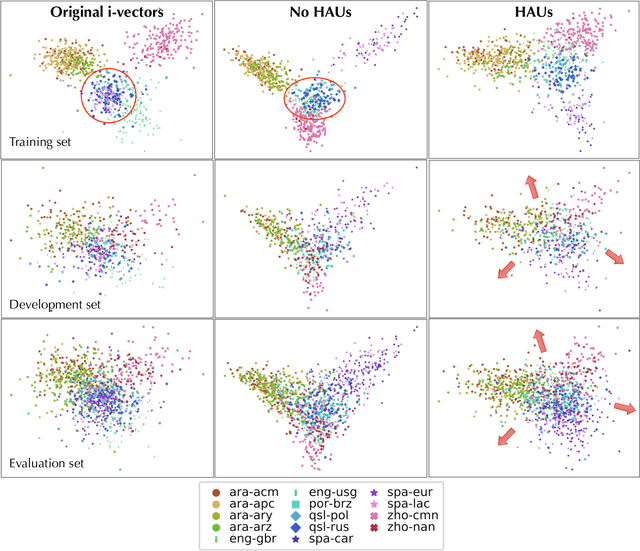
Language recognition system is typically trained directly to optimize classification error on the target language labels, without using the external, or meta-information in the estimation of the model parameters. However labels are not independent of each other, there is a dependency enforced by, for example, the language family, which affects negatively on classification. The other external information sources (e.g. audio encoding, telephony or video speech) can also decrease classification accuracy. In this paper, we attempt to solve these issues by constructing a deep hierarchical neural network, where different levels of meta-information are encapsulated by attentive prediction units and also embedded into the training progress. The proposed method learns auxiliary tasks to obtain robust internal representation and to construct a variant of attentive units within the hierarchical model. The final result is the structural prediction of the target language and a closely related language family. The algorithm reflects a "staircase" way of learning in both its architecture and training, advancing from the fundamental audio encoding to the language family level and finally to the target language level. This process not only improves generalization but also tackles the issues of imbalanced class priors and channel variability in the deep neural network model. Our experimental findings show that the proposed architecture outperforms the state-of-the-art i-vector approaches on both small and big language corpora by a significant margin.