 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxCeleb Enrichment for Age and Gender Recognition
Sep 28, 2021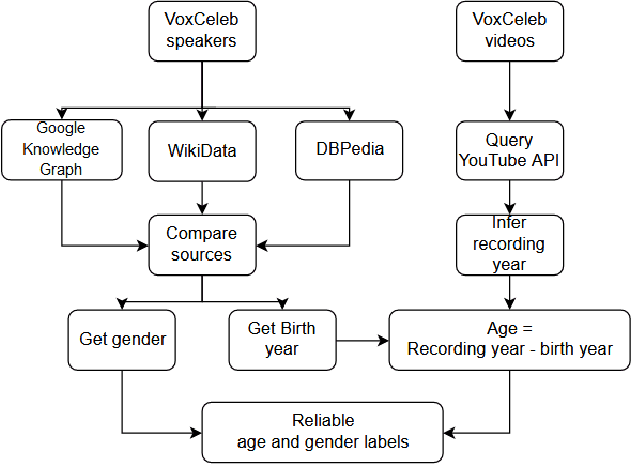
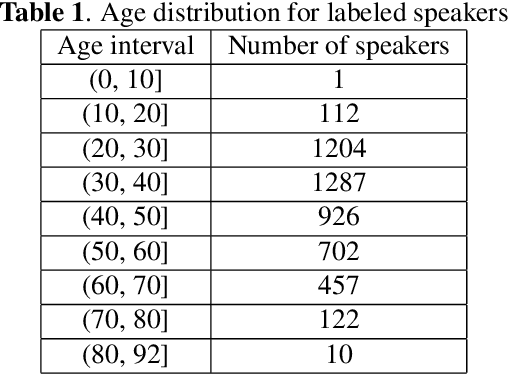
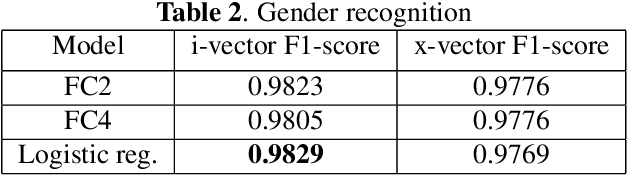
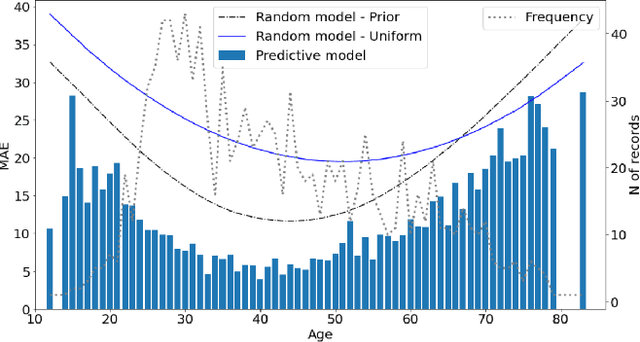
VoxCeleb datasets are widely used in speaker recognition studies. Our work serves two purposes. First, we provide speaker age labels and (an alternative) annotation of speaker gender. Second, we demonstrate the use of this metadata by constructing age and gender recognition models with different features and classifiers. We query different celebrity databases and apply consensus rules to derive age and gender labels. We also compare the original VoxCeleb gender labels with our labels to identify records that might be mislabeled in the original VoxCeleb data. On modeling side, we design a comprehensive study of multiple features and models for recognizing gender and age. Our best system, using i-vector features, achieved an F1-score of 0.9829 for gender recognition task using logistic regression, and the lowest mean absolute error (MAE) in age regression, 9.443 years, is obtained with ridge regression. This indicates challenge in age estimation from in-the-wild style speech data.
Towards Debugging Deep Neural Networks by Generating Speech Utterances
Jul 06, 2019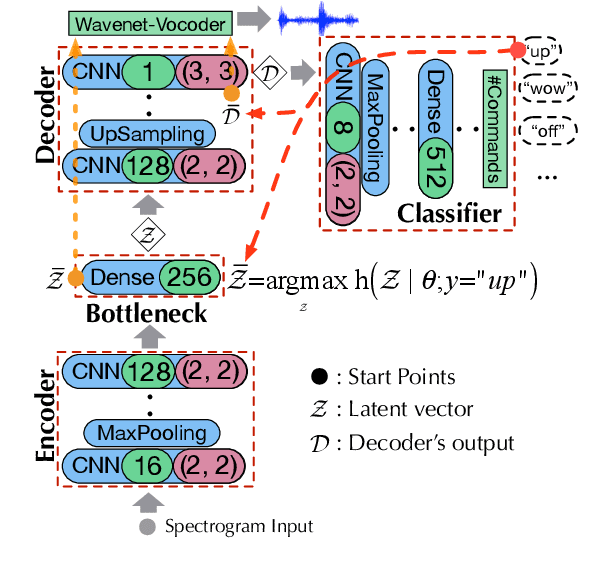
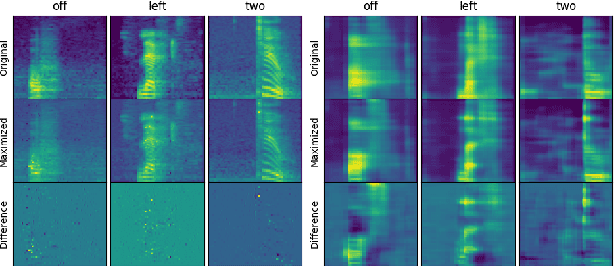
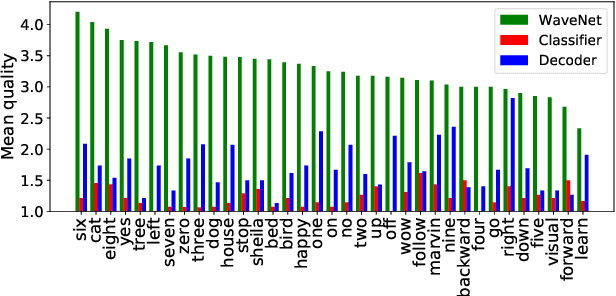
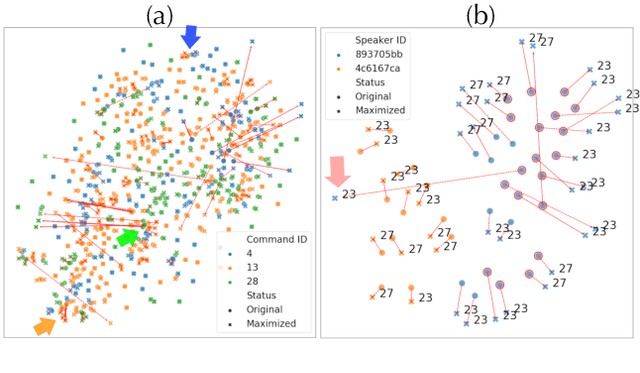
Deep neural networks (DNN) are able to successfully process and classify speech utterances. However, understanding the reason behind a classification by DNN is difficult. One such debugging method used with image classification DNNs is activation maximization, which generates example-images that are classified as one of the classes. In this work, we evaluate applicability of this method to speech utterance classifiers as the means to understanding what DNN "listens to". We trained a classifier using the speech command corpus and then use activation maximization to pull samples from the trained model. Then we synthesize audio from features using WaveNet vocoder for subjective analysis. We measure the quality of generated samples by objective measurements and crowd-sourced human evaluations. Results show that when combined with the prior of natural speech, activation maximization can be used to generate examples of different classes. Based on these results, activation maximization can be used to start opening up the DNN black-box in speech tasks.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019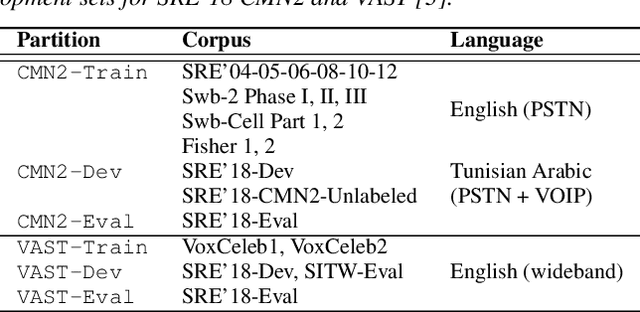
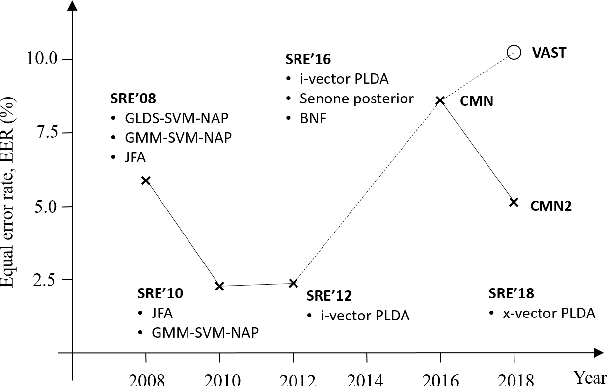
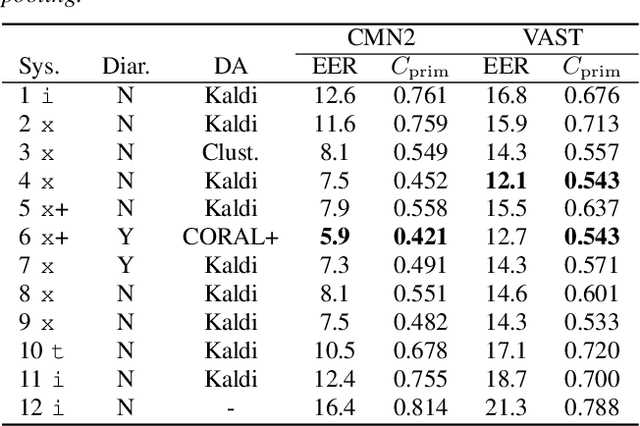
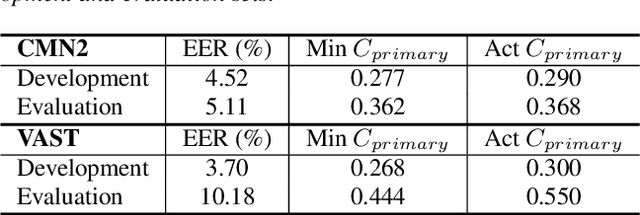
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.
Staircase Network: structural language identification via hierarchical attentive units
Apr 30, 2018

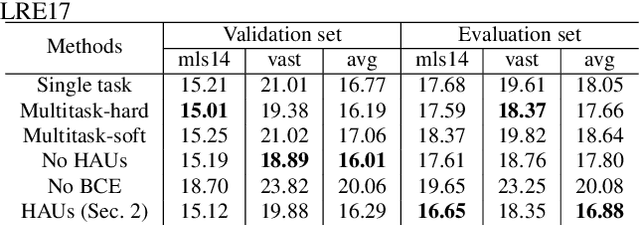
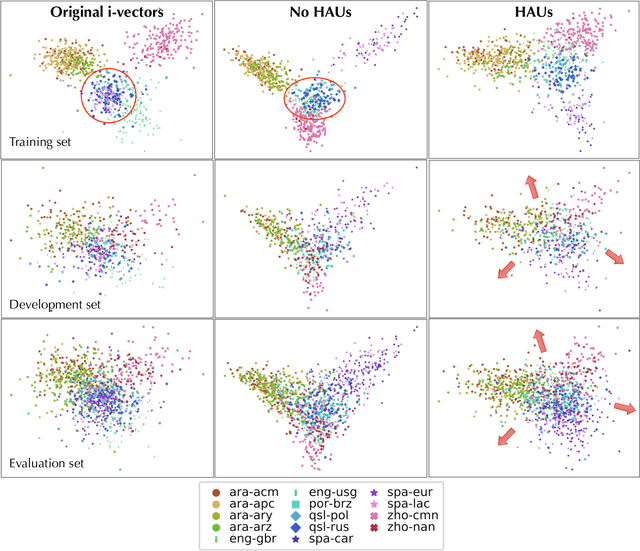
Language recognition system is typically trained directly to optimize classification error on the target language labels, without using the external, or meta-information in the estimation of the model parameters. However labels are not independent of each other, there is a dependency enforced by, for example, the language family, which affects negatively on classification. The other external information sources (e.g. audio encoding, telephony or video speech) can also decrease classification accuracy. In this paper, we attempt to solve these issues by constructing a deep hierarchical neural network, where different levels of meta-information are encapsulated by attentive prediction units and also embedded into the training progress. The proposed method learns auxiliary tasks to obtain robust internal representation and to construct a variant of attentive units within the hierarchical model. The final result is the structural prediction of the target language and a closely related language family. The algorithm reflects a "staircase" way of learning in both its architecture and training, advancing from the fundamental audio encoding to the language family level and finally to the target language level. This process not only improves generalization but also tackles the issues of imbalanced class priors and channel variability in the deep neural network model. Our experimental findings show that the proposed architecture outperforms the state-of-the-art i-vector approaches on both small and big language corpora by a significant margin.
Fantastic 4 system for NIST 2015 Language Recognition Evaluation
Feb 05, 2016
This article describes the systems jointly submitted by Institute for Infocomm (I$^2$R), the Laboratoire d'Informatique de l'Universit\'e du Maine (LIUM), Nanyang Technology University (NTU) and the University of Eastern Finland (UEF) for 2015 NIST Language Recognition Evaluation (LRE). The submitted system is a fusion of nine sub-systems based on i-vectors extracted from different types of features. Given the i-vectors, several classifiers are adopted for the language detection task including support vector machines (SVM), multi-class logistic regression (MCLR), Probabilistic Linear Discriminant Analysis (PLDA) and Deep Neural Networks (DNN).