 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2SA: Multimodal and Multilingual Model for Sentiment Analysis of Tweets
Apr 02, 2024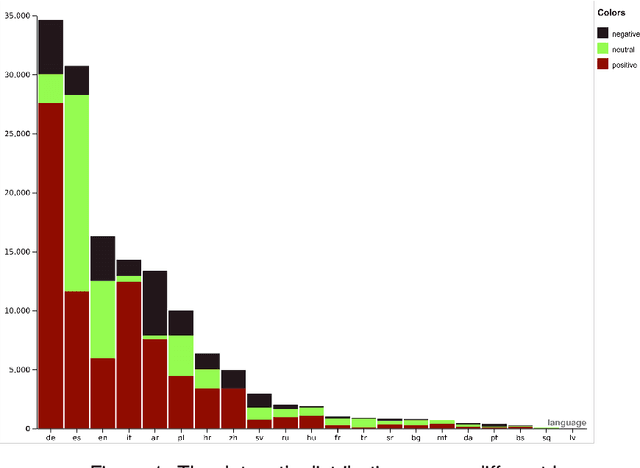
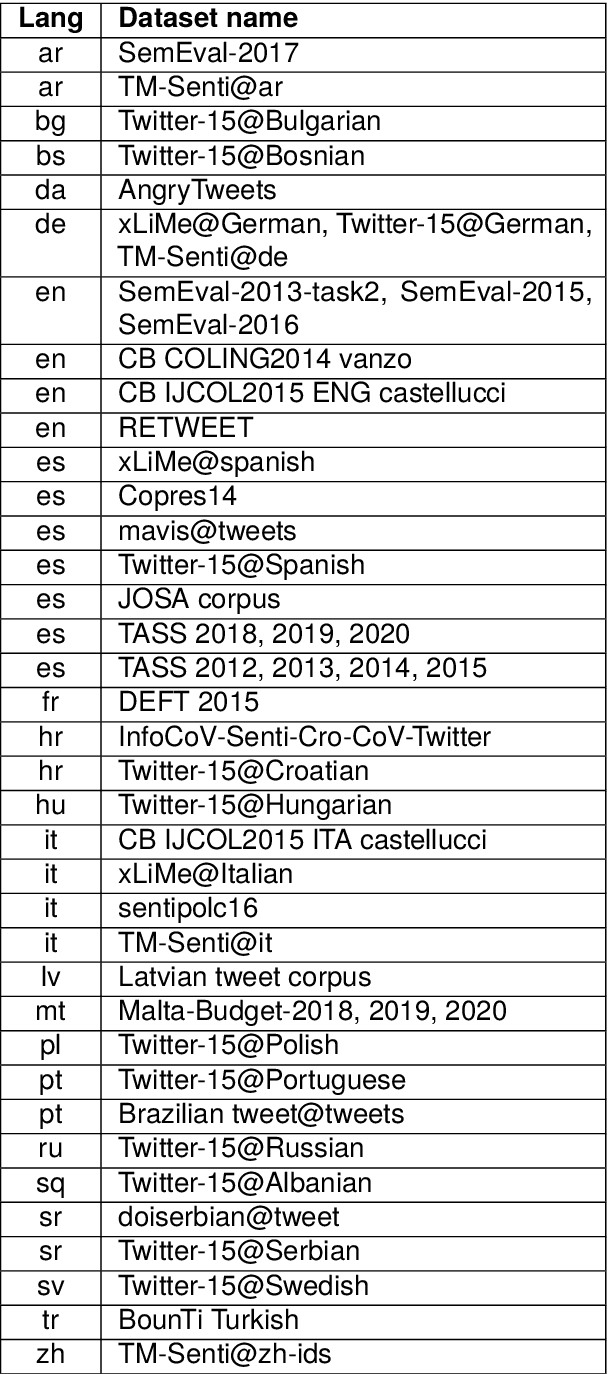
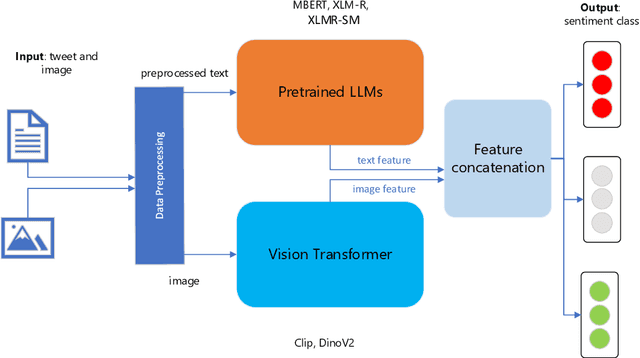
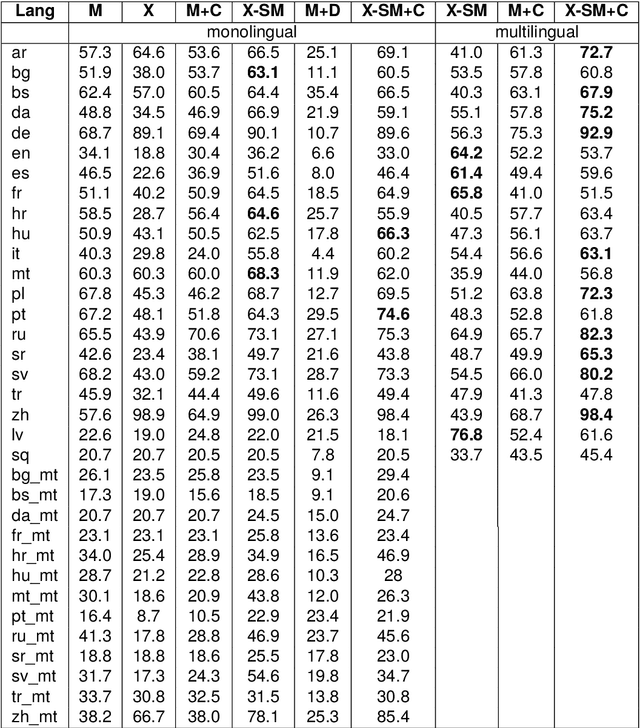
In recent years, multimodal natural language processing, aimed at learning from diverse data types, has garnered significant attention. However, there needs to be more clarity when it comes to analysing multimodal tasks in multi-lingual contexts. While prior studies on sentiment analysis of tweets have predominantly focused on the English language, this paper addresses this gap by transforming an existing textual Twitter sentiment dataset into a multimodal format through a straightforward curation process. Our work opens up new avenues for sentiment-related research within the research community. Additionally, we conduct baseline experiments utilising this augmented dataset and report the findings. Notably, our evaluations reveal that when comparing unimodal and multimodal configurations, using a sentiment-tuned large language model as a text encoder performs exceptionally well.
Croatian Film Review Dataset (Cro-FiReDa): A Sentiment Annotated Dataset of Film Reviews
May 14, 2023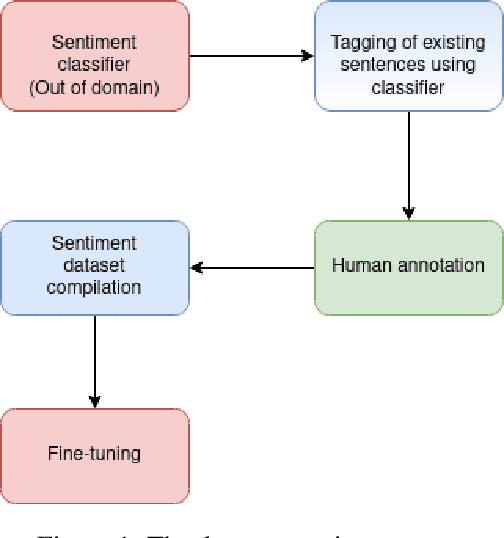
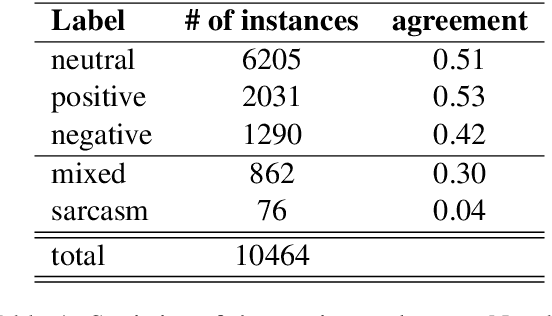
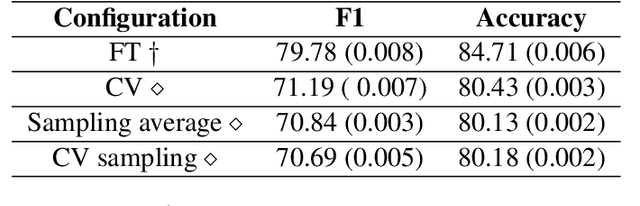

This paper introduces Cro-FiReDa, a sentiment-annotated dataset for Croatian in the domain of movie reviews. The dataset, which contains over 10,000 sentences, has been annotated at the sentence level. In addition to presenting the overall annotation process, we also present benchmark results based on the transformer-based fine-tuning approach
CroSentiNews 2.0: A Sentence-Level News Sentiment Corpus
May 14, 2023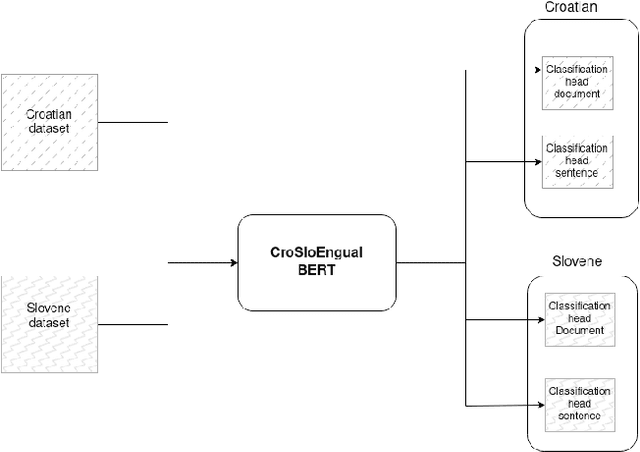



This article presents a sentence-level sentiment dataset for the Croatian news domain. In addition to the 3K annotated texts already present, our dataset contains 14.5K annotated sentence occurrences that have been tagged with 5 classes. We provide baseline scores in addition to the annotation process and inter-annotator agreement.
OEKG: The Open Event Knowledge Graph
Feb 28, 2023



Accessing and understanding contemporary and historical events of global impact such as the US elections and the Olympic Games is a major prerequisite for cross-lingual event analytics that investigate event causes, perception and consequences across country borders. In this paper, we present the Open Event Knowledge Graph (OEKG), a multilingual, event-centric, temporal knowledge graph composed of seven different data sets from multiple application domains, including question answering, entity recommendation and named entity recognition. These data sets are all integrated through an easy-to-use and robust pipeline and by linking to the event-centric knowledge graph EventKG. We describe their common schema and demonstrate the use of the OEKG at the example of three use cases: type-specific image retrieval, hybrid question answering over knowledge graphs and news articles, as well as language-specific event recommendation. The OEKG and its query endpoint are publicly available.
Multi-task Learning for Cross-Lingual Sentiment Analysis
Dec 14, 2022
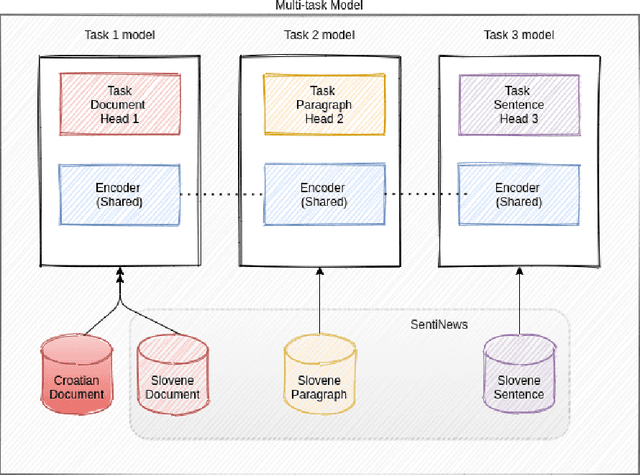


This paper presents a cross-lingual sentiment analysis of news articles using zero-shot and few-shot learning. The study aims to classify the Croatian news articles with positive, negative, and neutral sentiments using the Slovene dataset. The system is based on a trilingual BERT-based model trained in three languages: English, Slovene, Croatian. The paper analyses different setups using datasets in two languages and proposes a simple multi-task model to perform sentiment classification. The evaluation is performed using the few-shot and zero-shot scenarios in single-task and multi-task experiments for Croatian and Slovene.
Quotations, Coreference Resolution, and Sentiment Annotations in Croatian News Articles: An Exploratory Study
Dec 14, 2022This paper presents a corpus annotated for the task of direct-speech extraction in Croatian. The paper focuses on the annotation of the quotation, co-reference resolution, and sentiment annotation in SETimes news corpus in Croatian and on the analysis of its language-specific differences compared to English. From this, a list of the phenomena that require special attention when performing these annotations is derived. The generated corpus with quotation features annotations can be used for multiple tasks in the field of Natural Language Processing.
Building and Evaluating Universal Named-Entity Recognition English corpus
Dec 14, 2022This article presents the application of the Universal Named Entity framework to generate automatically annotated corpora. By using a workflow that extracts Wikipedia data and meta-data and DBpedia information, we generated an English dataset which is described and evaluated. Furthermore, we conducted a set of experiments to improve the annotations in terms of precision, recall, and F1-measure. The final dataset is available and the established workflow can be applied to any language with existing Wikipedia and DBpedia. As part of future research, we intend to continue improving the annotation process and extend it to other languages.
Building Multilingual Corpora for a Complex Named Entity Recognition and Classification Hierarchy using Wikipedia and DBpedia
Dec 14, 2022



With the ever-growing popularity of the field of NLP, the demand for datasets in low resourced-languages follows suit. Following a previously established framework, in this paper, we present the UNER dataset, a multilingual and hierarchical parallel corpus annotated for named-entities. We describe in detail the developed procedure necessary to create this type of dataset in any language available on Wikipedia with DBpedia information. The three-step procedure extracts entities from Wikipedia articles, links them to DBpedia, and maps the DBpedia sets of classes to the UNER labels. This is followed by a post-processing procedure that significantly increases the number of identified entities in the final results. The paper concludes with a statistical and qualitative analysis of the resulting dataset.
Natural Language Processing Chains Inside a Cross-lingual Event-Centric Knowledge Pipeline for European Union Under-resourced Languages
Oct 23, 2020
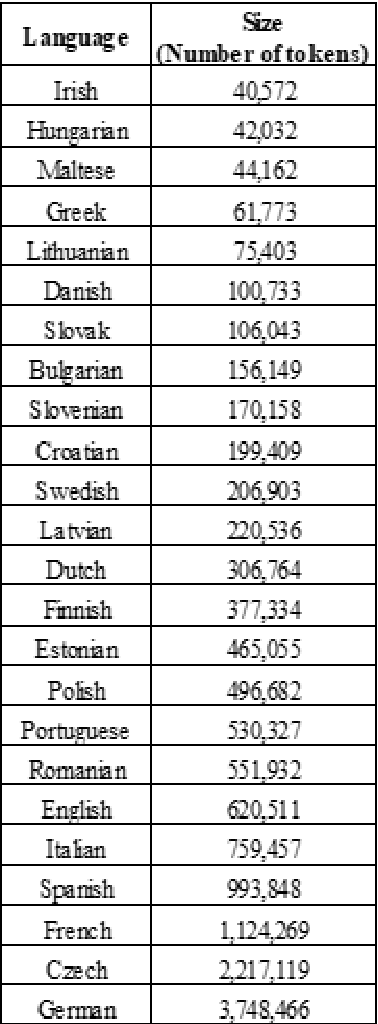
This article presents the strategy for developing a platform containing Language Processing Chains for European Union languages, consisting of Tokenization to Parsing, also including Named Entity recognition andwith addition ofSentiment Analysis. These chains are part of the first step of an event-centric knowledge processing pipeline whose aim is to process multilingual media information about major events that can cause an impactin Europe and the rest of the world. Due to the differences in terms of availability of language resources for each language, we have built this strategy in three steps, starting with processing chains for the well-resourced languages and finishing with the development of new modules for the under-resourced ones. In order to classify all European Union official languages in terms of resources, we have analysed the size of annotated corpora as well as the existence of pre-trained models in mainstream Language Processing tools, and we have combined this information with the proposed classification published at META-NETwhitepaper series.
Evaluating Language Tools for Fifteen EU-official Under-resourced Languages
Oct 23, 2020
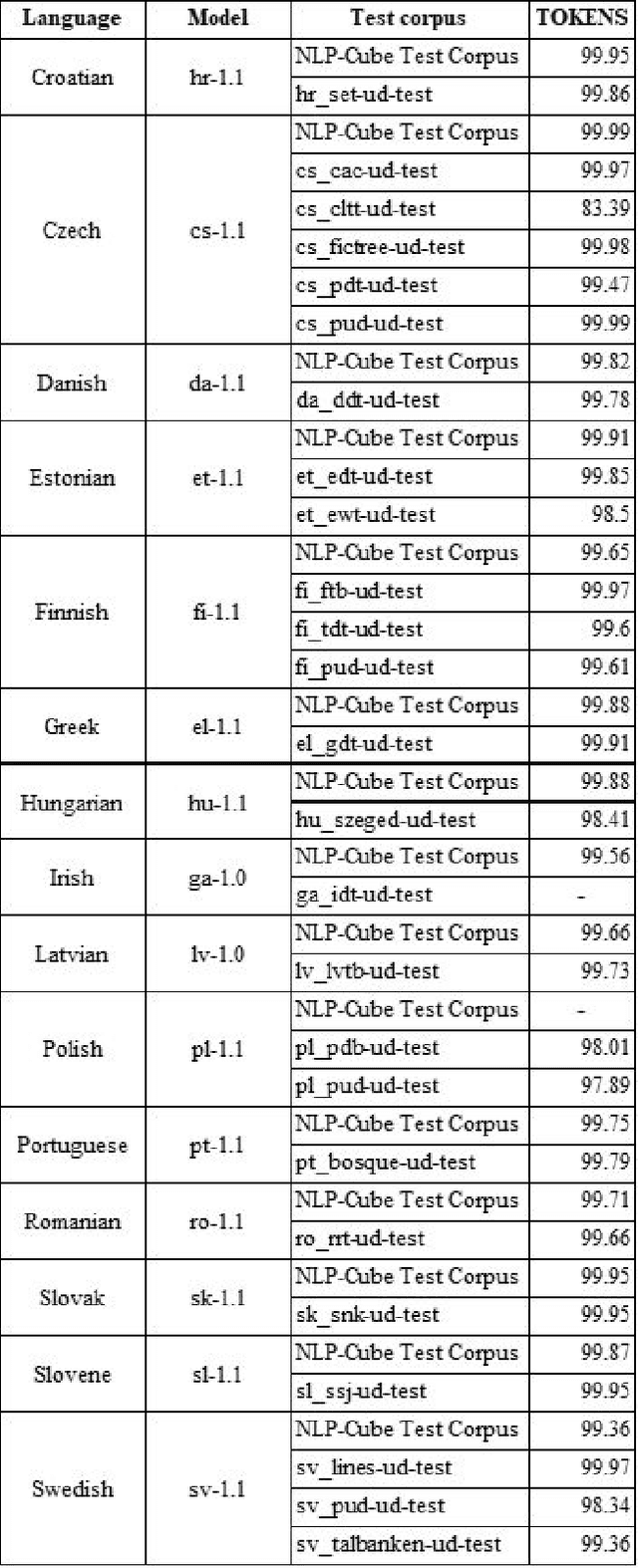
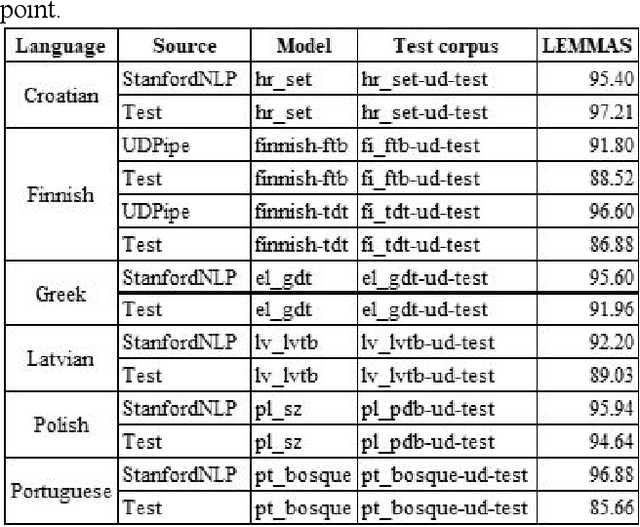
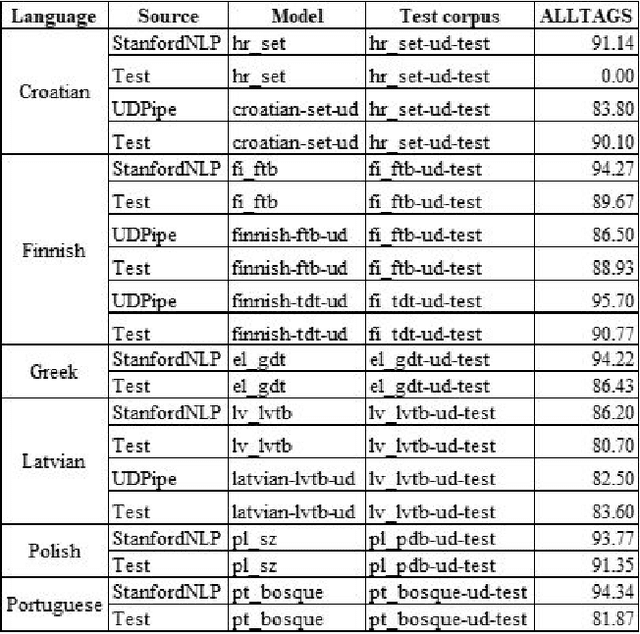
This article presents the results of the evaluation campaign of language tools available for fifteen EU-official under-resourced languages. The evaluation was conducted within the MSC ITN CLEOPATRA action that aims at building the cross-lingual event-centric knowledge processing on top of the application of linguistic processing chains (LPCs) for at least 24 EU-official languages. In this campaign, we concentrated on three existing NLP platforms (Stanford CoreNLP, NLP Cube, UDPipe) that all provide models for under-resourced languages and in this first run we covered 15 under-resourced languages for which the models were available. We present the design of the evaluation campaign and present the results as well as discuss them. We considered the difference between reported and our tested results within a single percentage point as being within the limits of acceptable tolerance and thus consider this result as reproducible. However, for a number of languages, the results are below what was reported in the literature, and in some cases, our testing results are even better than the ones reported previously. Particularly problematic was the evaluation of NERC systems. One of the reasons is the absence of universally or cross-lingually applicable named entities classification scheme that would serve the NERC task in different languages analogous to the Universal Dependency scheme in parsing task. To build such a scheme has become one of our the future research directions.