 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCroSentiNews 2.0: A Sentence-Level News Sentiment Corpus
May 14, 2023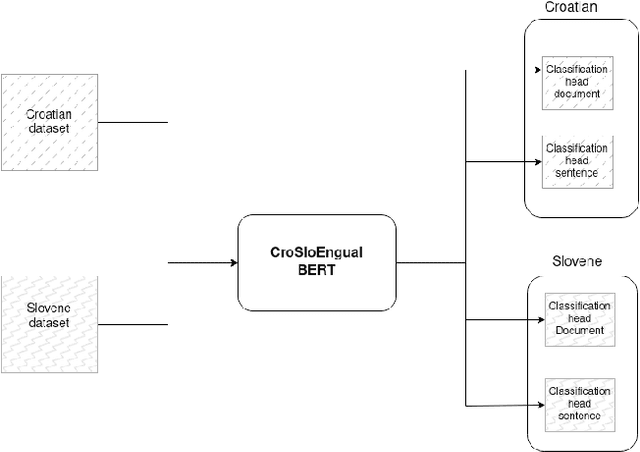



This article presents a sentence-level sentiment dataset for the Croatian news domain. In addition to the 3K annotated texts already present, our dataset contains 14.5K annotated sentence occurrences that have been tagged with 5 classes. We provide baseline scores in addition to the annotation process and inter-annotator agreement.
Quotations, Coreference Resolution, and Sentiment Annotations in Croatian News Articles: An Exploratory Study
Dec 14, 2022This paper presents a corpus annotated for the task of direct-speech extraction in Croatian. The paper focuses on the annotation of the quotation, co-reference resolution, and sentiment annotation in SETimes news corpus in Croatian and on the analysis of its language-specific differences compared to English. From this, a list of the phenomena that require special attention when performing these annotations is derived. The generated corpus with quotation features annotations can be used for multiple tasks in the field of Natural Language Processing.