 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Learning for Cross-Lingual Sentiment Analysis
Dec 14, 2022
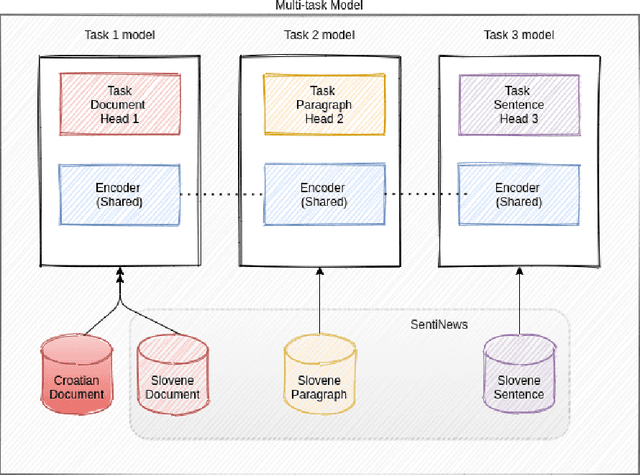


This paper presents a cross-lingual sentiment analysis of news articles using zero-shot and few-shot learning. The study aims to classify the Croatian news articles with positive, negative, and neutral sentiments using the Slovene dataset. The system is based on a trilingual BERT-based model trained in three languages: English, Slovene, Croatian. The paper analyses different setups using datasets in two languages and proposes a simple multi-task model to perform sentiment classification. The evaluation is performed using the few-shot and zero-shot scenarios in single-task and multi-task experiments for Croatian and Slovene.
UNER: Universal Named-Entity RecognitionFramework
Oct 23, 2020


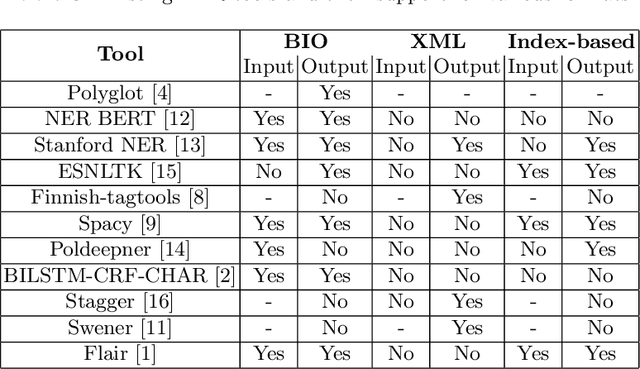
We introduce the Universal Named-Entity Recognition (UNER)framework, a 4-level classification hierarchy, and the methodology that isbeing adopted to create the first multilingual UNER corpus: the SETimesparallel corpus annotated for named-entities. First, the English SETimescorpus will be annotated using existing tools and knowledge bases. Afterevaluating the resulting annotations through crowdsourcing campaigns,they will be propagated automatically to other languages within the SE-Times corpora. Finally, as an extrinsic evaluation, the UNER multilin-gual dataset will be used to train and test available NER tools. As part offuture research directions, we aim to increase the number of languages inthe UNER corpus and to investigate possible ways of integrating UNERwith available knowledge graphs to improve named-entity recognition.