 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCroatian Film Review Dataset (Cro-FiReDa): A Sentiment Annotated Dataset of Film Reviews
May 14, 2023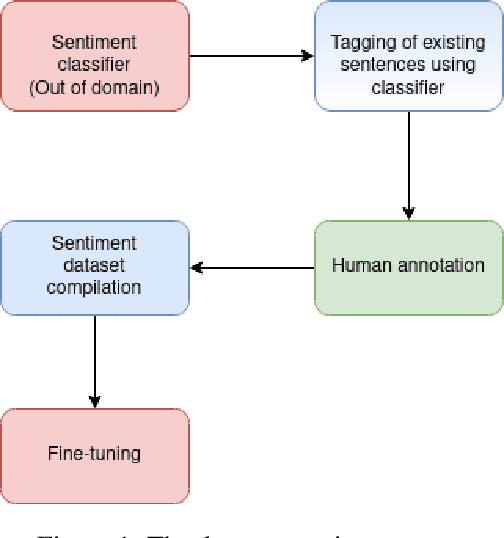
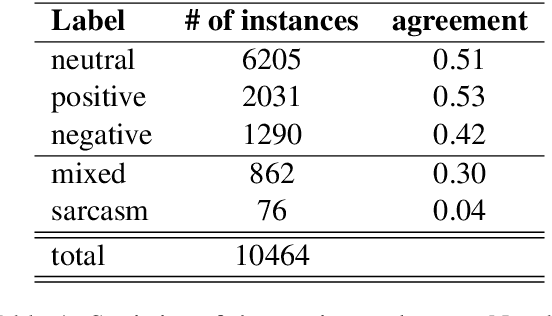

This paper introduces Cro-FiReDa, a sentiment-annotated dataset for Croatian in the domain of movie reviews. The dataset, which contains over 10,000 sentences, has been annotated at the sentence level. In addition to presenting the overall annotation process, we also present benchmark results based on the transformer-based fine-tuning approach
Multi-task Learning for Cross-Lingual Sentiment Analysis
Dec 14, 2022
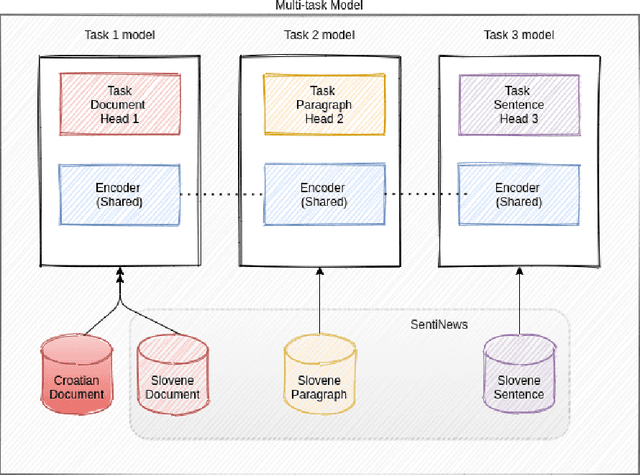


This paper presents a cross-lingual sentiment analysis of news articles using zero-shot and few-shot learning. The study aims to classify the Croatian news articles with positive, negative, and neutral sentiments using the Slovene dataset. The system is based on a trilingual BERT-based model trained in three languages: English, Slovene, Croatian. The paper analyses different setups using datasets in two languages and proposes a simple multi-task model to perform sentiment classification. The evaluation is performed using the few-shot and zero-shot scenarios in single-task and multi-task experiments for Croatian and Slovene.