Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCroatian Film Review Dataset (Cro-FiReDa): A Sentiment Annotated Dataset of Film Reviews
Paper and Code
May 14, 2023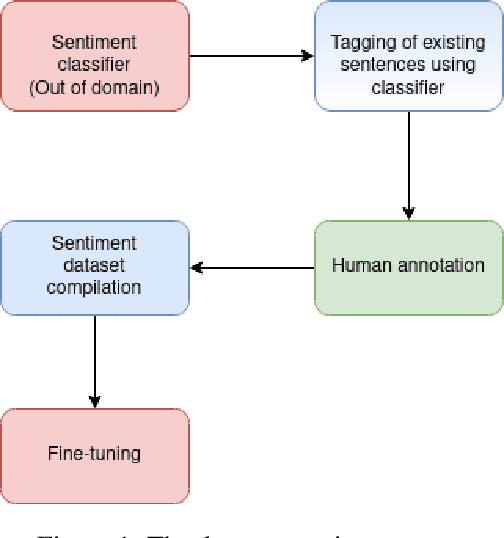
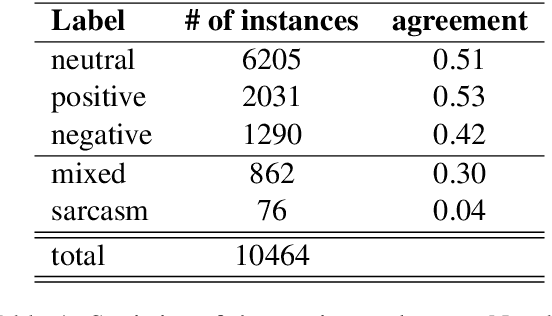
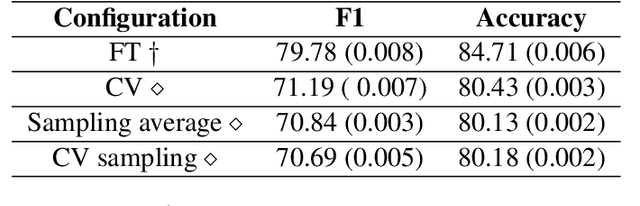

This paper introduces Cro-FiReDa, a sentiment-annotated dataset for Croatian in the domain of movie reviews. The dataset, which contains over 10,000 sentences, has been annotated at the sentence level. In addition to presenting the overall annotation process, we also present benchmark results based on the transformer-based fine-tuning approach
* LTC 2023
View paper on