 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Processing Chains Inside a Cross-lingual Event-Centric Knowledge Pipeline for European Union Under-resourced Languages
Paper and Code
Oct 23, 2020
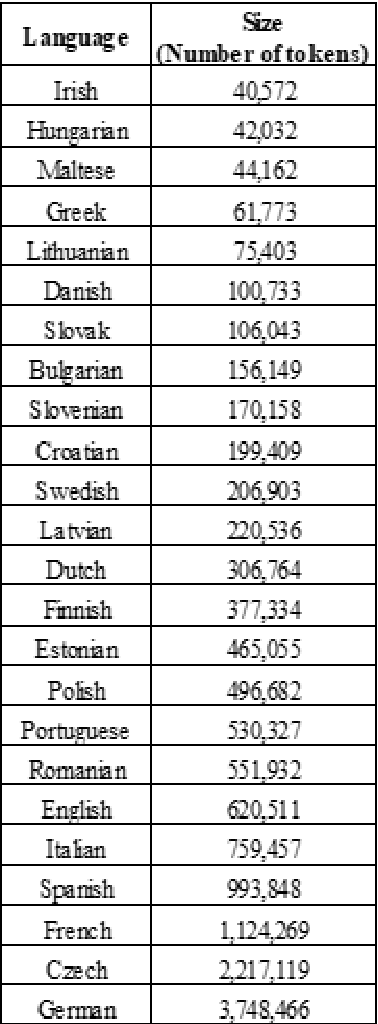
This article presents the strategy for developing a platform containing Language Processing Chains for European Union languages, consisting of Tokenization to Parsing, also including Named Entity recognition andwith addition ofSentiment Analysis. These chains are part of the first step of an event-centric knowledge processing pipeline whose aim is to process multilingual media information about major events that can cause an impactin Europe and the rest of the world. Due to the differences in terms of availability of language resources for each language, we have built this strategy in three steps, starting with processing chains for the well-resourced languages and finishing with the development of new modules for the under-resourced ones. In order to classify all European Union official languages in terms of resources, we have analysed the size of annotated corpora as well as the existence of pre-trained models in mainstream Language Processing tools, and we have combined this information with the proposed classification published at META-NETwhitepaper series.