 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Visual Contrastive learning models via Preference Optimization
Nov 12, 2024Contrastive learning models have demonstrated impressive abilities to capture semantic similarities by aligning representations in the embedding space. However, their performance can be limited by the quality of the training data and its inherent biases. While Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) have been applied to generative models to align them with human preferences, their use in contrastive learning has yet to be explored. This paper introduces a novel method for training contrastive learning models using Preference Optimization (PO) to break down complex concepts. Our method systematically aligns model behavior with desired preferences, enhancing performance on the targeted task. In particular, we focus on enhancing model robustness against typographic attacks, commonly seen in contrastive models like CLIP. We further apply our method to disentangle gender understanding and mitigate gender biases, offering a more nuanced control over these sensitive attributes. Our experiments demonstrate that models trained using PO outperform standard contrastive learning techniques while retaining their ability to handle adversarial challenges and maintain accuracy on other downstream tasks. This makes our method well-suited for tasks requiring fairness, robustness, and alignment with specific preferences. We evaluate our method on several vision-language tasks, tackling challenges such as typographic attacks. Additionally, we explore the model's ability to disentangle gender concepts and mitigate gender bias, showcasing the versatility of our approach.
Robust Semi-supervised Learning via $f$-Divergence and $α$-Rényi Divergence
May 01, 2024
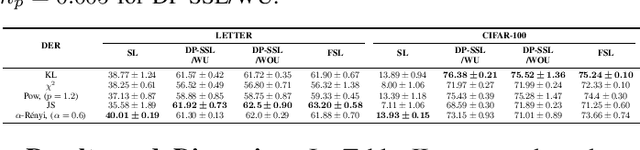
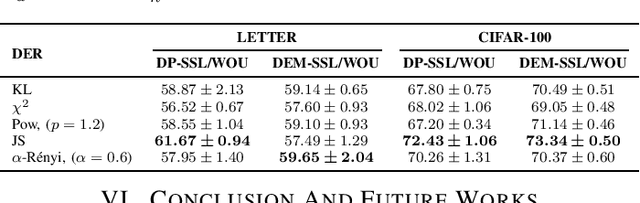

This paper investigates a range of empirical risk functions and regularization methods suitable for self-training methods in semi-supervised learning. These approaches draw inspiration from various divergence measures, such as $f$-divergences and $\alpha$-R\'enyi divergences. Inspired by the theoretical foundations rooted in divergences, i.e., $f$-divergences and $\alpha$-R\'enyi divergence, we also provide valuable insights to enhance the understanding of our empirical risk functions and regularization techniques. In the pseudo-labeling and entropy minimization techniques as self-training methods for effective semi-supervised learning, the self-training process has some inherent mismatch between the true label and pseudo-label (noisy pseudo-labels) and some of our empirical risk functions are robust, concerning noisy pseudo-labels. Under some conditions, our empirical risk functions demonstrate better performance when compared to traditional self-training methods.
Belief Samples Are All You Need For Social Learning
Mar 25, 2024In this paper, we consider the problem of social learning, where a group of agents embedded in a social network are interested in learning an underlying state of the world. Agents have incomplete, noisy, and heterogeneous sources of information, providing them with recurring private observations of the underlying state of the world. Agents can share their learning experience with their peers by taking actions observable to them, with values from a finite feasible set of states. Actions can be interpreted as samples from the beliefs which agents may form and update on what the true state of the world is. Sharing samples, in place of full beliefs, is motivated by the limited communication, cognitive, and information-processing resources available to agents especially in large populations. Previous work (Salhab et al.) poses the question as to whether learning with probability one is still achievable if agents are only allowed to communicate samples from their beliefs. We provide a definite positive answer to this question, assuming a strongly connected network and a ``collective distinguishability'' assumption, which are both required for learning even in full-belief-sharing settings. In our proposed belief update mechanism, each agent's belief is a normalized weighted geometric interpolation between a fully Bayesian private belief -- aggregating information from the private source -- and an ensemble of empirical distributions of the samples shared by her neighbors over time. By carefully constructing asymptotic almost-sure lower/upper bounds on the frequency of shared samples matching the true state/or not, we rigorously prove the convergence of all the beliefs to the true state, with probability one.