 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Semi-supervised Learning via $f$-Divergence and $α$-Rényi Divergence
May 01, 2024
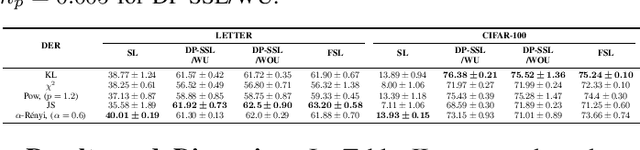
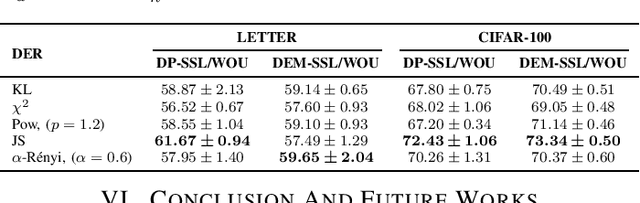

This paper investigates a range of empirical risk functions and regularization methods suitable for self-training methods in semi-supervised learning. These approaches draw inspiration from various divergence measures, such as $f$-divergences and $\alpha$-R\'enyi divergences. Inspired by the theoretical foundations rooted in divergences, i.e., $f$-divergences and $\alpha$-R\'enyi divergence, we also provide valuable insights to enhance the understanding of our empirical risk functions and regularization techniques. In the pseudo-labeling and entropy minimization techniques as self-training methods for effective semi-supervised learning, the self-training process has some inherent mismatch between the true label and pseudo-label (noisy pseudo-labels) and some of our empirical risk functions are robust, concerning noisy pseudo-labels. Under some conditions, our empirical risk functions demonstrate better performance when compared to traditional self-training methods.