 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeast but not Last: Fine-tuning Intermediate Principal Components for Better Performance-Forgetting Trade-Offs
Feb 03, 2026Low-Rank Adaptation (LoRA) methods have emerged as crucial techniques for adapting large pre-trained models to downstream tasks under computational and memory constraints. However, they face a fundamental challenge in balancing task-specific performance gains against catastrophic forgetting of pre-trained knowledge, where existing methods provide inconsistent recommendations. This paper presents a comprehensive analysis of the performance-forgetting trade-offs inherent in low-rank adaptation using principal components as initialization. Our investigation reveals that fine-tuning intermediate components leads to better balance and show more robustness to high learning rates than first (PiSSA) and last (MiLoRA) components in existing work. Building on these findings, we provide a practical approach for initialization of LoRA that offers superior trade-offs. We demonstrate in a thorough empirical study on a variety of computer vision and NLP tasks that our approach improves accuracy and reduces forgetting, also in continual learning scenarios.
Analysing Differences in Persuasive Language in LLM-Generated Text: Uncovering Stereotypical Gender Patterns
Jan 09, 2026Large language models (LLMs) are increasingly used for everyday communication tasks, including drafting interpersonal messages intended to influence and persuade. Prior work has shown that LLMs can successfully persuade humans and amplify persuasive language. It is therefore essential to understand how user instructions affect the generation of persuasive language, and to understand whether the generated persuasive language differs, for example, when targeting different groups. In this work, we propose a framework for evaluating how persuasive language generation is affected by recipient gender, sender intent, or output language. We evaluate 13 LLMs and 16 languages using pairwise prompt instructions. We evaluate model responses on 19 categories of persuasive language using an LLM-as-judge setup grounded in social psychology and communication science. Our results reveal significant gender differences in the persuasive language generated across all models. These patterns reflect biases consistent with gender-stereotypical linguistic tendencies documented in social psychology and sociolinguistics.
DCFO: Density-Based Counterfactuals for Outliers - Additional Material
Dec 18, 2025Outlier detection identifies data points that significantly deviate from the majority of the data distribution. Explaining outliers is crucial for understanding the underlying factors that contribute to their detection, validating their significance, and identifying potential biases or errors. Effective explanations provide actionable insights, facilitating preventive measures to avoid similar outliers in the future. Counterfactual explanations clarify why specific data points are classified as outliers by identifying minimal changes required to alter their prediction. Although valuable, most existing counterfactual explanation methods overlook the unique challenges posed by outlier detection, and fail to target classical, widely adopted outlier detection algorithms. Local Outlier Factor (LOF) is one the most popular unsupervised outlier detection methods, quantifying outlierness through relative local density. Despite LOF's widespread use across diverse applications, it lacks interpretability. To address this limitation, we introduce Density-based Counterfactuals for Outliers (DCFO), a novel method specifically designed to generate counterfactual explanations for LOF. DCFO partitions the data space into regions where LOF behaves smoothly, enabling efficient gradient-based optimisation. Extensive experimental validation on 50 OpenML datasets demonstrates that DCFO consistently outperforms benchmarked competitors, offering superior proximity and validity of generated counterfactuals.
Classifier Reconstruction Through Counterfactual-Aware Wasserstein Prototypes
Dec 11, 2025Counterfactual explanations provide actionable insights by identifying minimal input changes required to achieve a desired model prediction. Beyond their interpretability benefits, counterfactuals can also be leveraged for model reconstruction, where a surrogate model is trained to replicate the behavior of a target model. In this work, we demonstrate that model reconstruction can be significantly improved by recognizing that counterfactuals, which typically lie close to the decision boundary, can serve as informative though less representative samples for both classes. This is particularly beneficial in settings with limited access to labeled data. We propose a method that integrates original data samples with counterfactuals to approximate class prototypes using the Wasserstein barycenter, thereby preserving the underlying distributional structure of each class. This approach enhances the quality of the surrogate model and mitigates the issue of decision boundary shift, which commonly arises when counterfactuals are naively treated as ordinary training instances. Empirical results across multiple datasets show that our method improves fidelity between the surrogate and target models, validating its effectiveness.
RainPro-8: An Efficient Deep Learning Model to Estimate Rainfall Probabilities Over 8 Hours
May 15, 2025We present a deep learning model for high-resolution probabilistic precipitation forecasting over an 8-hour horizon in Europe, overcoming the limitations of radar-only deep learning models with short forecast lead times. Our model efficiently integrates multiple data sources - including radar, satellite, and physics-based numerical weather prediction (NWP) - while capturing long-range interactions, resulting in accurate forecasts with robust uncertainty quantification through consistent probabilistic maps. Featuring a compact architecture, it enables more efficient training and faster inference than existing models. Extensive experiments demonstrate that our model surpasses current operational NWP systems, extrapolation-based methods, and deep-learning nowcasting models, setting a new standard for high-resolution precipitation forecasting in Europe, ensuring a balance between accuracy, interpretability, and computational efficiency.
1LoRA: Summation Compression for Very Low-Rank Adaptation
Mar 11, 2025Parameter-Efficient Fine-Tuning (PEFT) methods have transformed the approach to fine-tuning large models for downstream tasks by enabling the adjustment of significantly fewer parameters than those in the original model matrices. In this work, we study the "very low rank regime", where we fine-tune the lowest amount of parameters per linear layer for each considered PEFT method. We propose 1LoRA (Summation Low-Rank Adaptation), a compute, parameter and memory efficient fine-tuning method which uses the feature sum as fixed compression and a single trainable vector as decompression. Differently from state-of-the-art PEFT methods like LoRA, VeRA, and the recent MoRA, 1LoRA uses fewer parameters per layer, reducing the memory footprint and the computational cost. We extensively evaluate our method against state-of-the-art PEFT methods on multiple fine-tuning tasks, and show that our method not only outperforms them, but is also more parameter, memory and computationally efficient. Moreover, thanks to its memory efficiency, 1LoRA allows to fine-tune more evenly across layers, instead of focusing on specific ones (e.g. attention layers), improving performance further.
A Meta-Evaluation of Style and Attribute Transfer Metrics
Feb 20, 2025
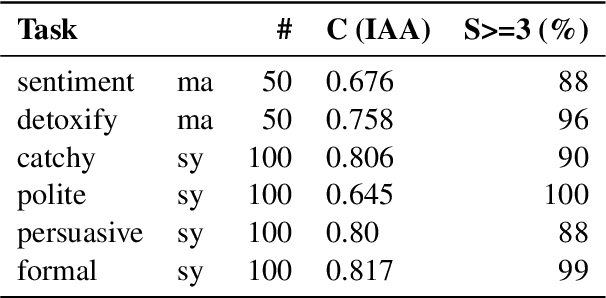
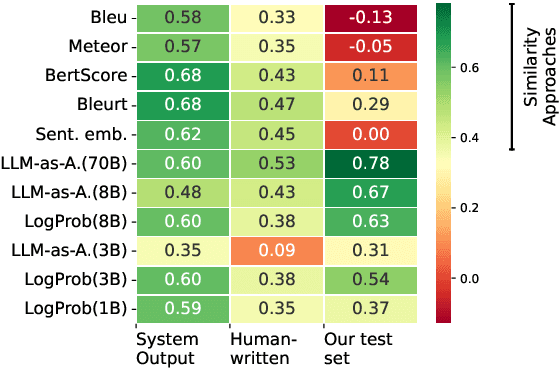

LLMs make it easy to rewrite text in any style, be it more polite, persuasive, or more positive. We present a large-scale study of evaluation metrics for style and attribute transfer with a focus on content preservation; meaning content not attributed to the style shift is preserved. The de facto evaluation approach uses lexical or semantic similarity metrics often between source sentences and rewrites. While these metrics are not designed to distinguish between style or content differences, empirical meta-evaluation shows a reasonable correlation to human judgment. In fact, recent works find that LLMs prompted as evaluators are only comparable to semantic similarity metrics, even though intuitively, the LLM approach should better fit the task. To investigate this discrepancy, we benchmark 8 metrics for evaluating content preservation on existing datasets and additionally construct a new test set that better aligns with the meta-evaluation aim. Indeed, we then find that the empirical conclusion aligns with the intuition: content preservation metrics for style/attribute transfer must be conditional on the style shift. To support this, we propose a new efficient zero-shot evaluation method using the likelihood of the next token. We hope our meta-evaluation can foster more research on evaluating content preservation metrics, and also to ensure fair evaluation of methods for conducting style transfer.
I Want 'Em All (At Once) -- Ultrametric Cluster Hierarchies
Feb 19, 2025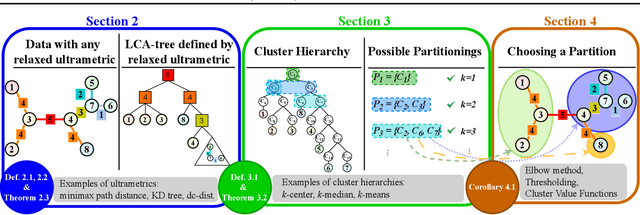

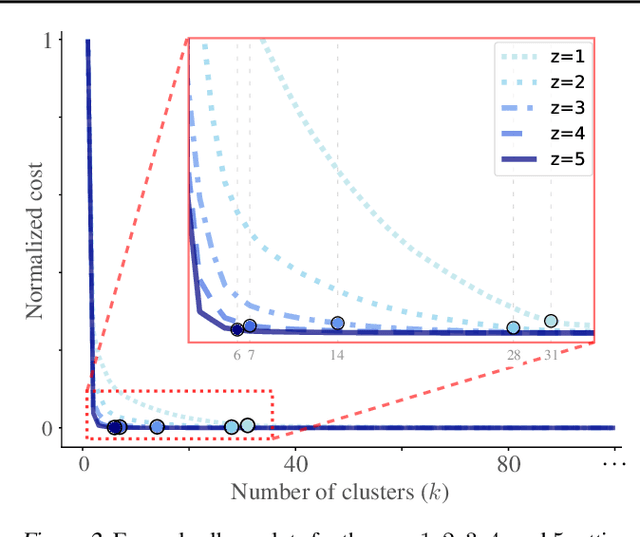
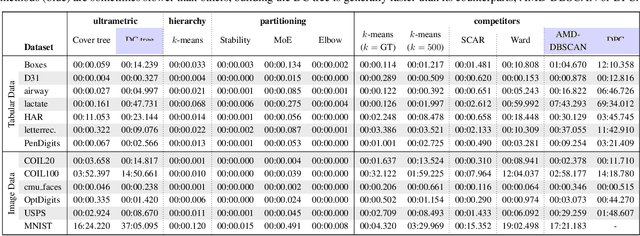
Hierarchical clustering is a powerful tool for exploratory data analysis, organizing data into a tree of clusterings from which a partition can be chosen. This paper generalizes these ideas by proving that, for any reasonable hierarchy, one can optimally solve any center-based clustering objective over it (such as $k$-means). Moreover, these solutions can be found exceedingly quickly and are themselves necessarily hierarchical. Thus, given a cluster tree, we show that one can quickly access a plethora of new, equally meaningful hierarchies. Just as in standard hierarchical clustering, one can then choose any desired partition from these new hierarchies. We conclude by verifying the utility of our proposed techniques across datasets, hierarchies, and partitioning schemes.
Multi-Source Temporal Attention Network for Precipitation Nowcasting
Oct 11, 2024



Precipitation nowcasting is crucial across various industries and plays a significant role in mitigating and adapting to climate change. We introduce an efficient deep learning model for precipitation nowcasting, capable of predicting rainfall up to 8 hours in advance with greater accuracy than existing operational physics-based and extrapolation-based models. Our model leverages multi-source meteorological data and physics-based forecasts to deliver high-resolution predictions in both time and space. It captures complex spatio-temporal dynamics through temporal attention networks and is optimized using data quality maps and dynamic thresholds. Experiments demonstrate that our model outperforms state-of-the-art, and highlight its potential for fast reliable responses to evolving weather conditions.
Temporal Subspace Clustering for Molecular Dynamics Data
Jul 31, 2024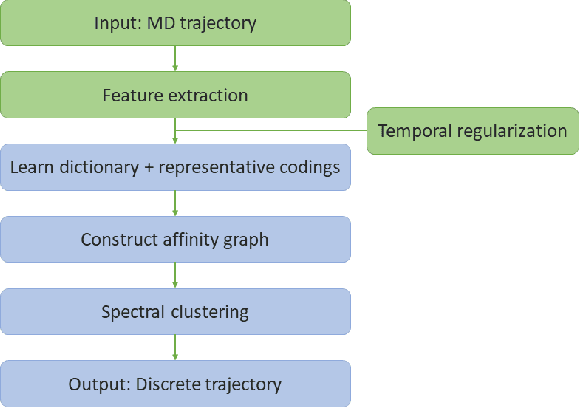
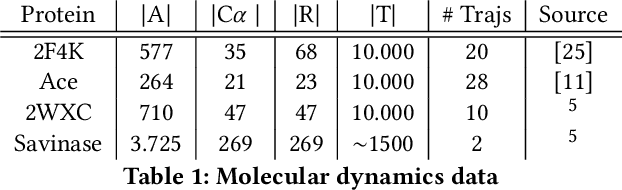
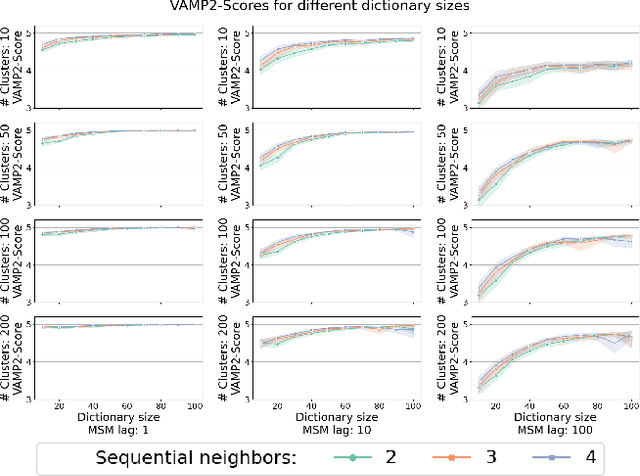
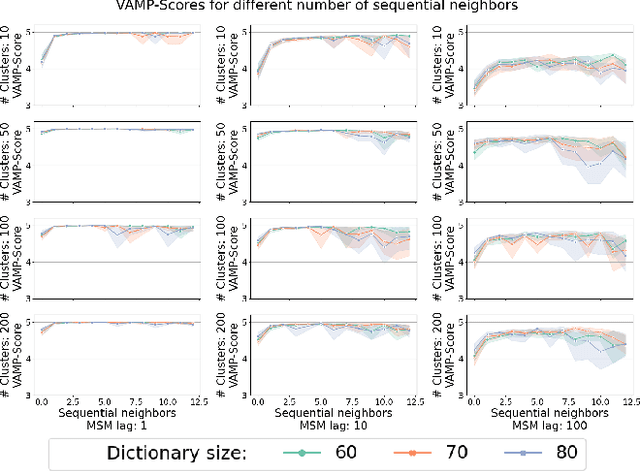
We introduce MOSCITO (MOlecular Dynamics Subspace Clustering with Temporal Observance), a subspace clustering for molecular dynamics data. MOSCITO groups those timesteps of a molecular dynamics trajectory together into clusters in which the molecule has similar conformations. In contrast to state-of-the-art methods, MOSCITO takes advantage of sequential relationships found in time series data. Unlike existing work, MOSCITO does not need a two-step procedure with tedious post-processing, but directly models essential properties of the data. Interpreting clusters as Markov states allows us to evaluate the clustering performance based on the resulting Markov state models. In experiments on 60 trajectories and 4 different proteins, we show that the performance of MOSCITO achieves state-of-the-art performance in a novel single-step method. Moreover, by modeling temporal aspects, MOSCITO obtains better segmentation of trajectories, especially for small numbers of clusters.