 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Dataset Inference
Paper and Code
Oct 24, 2022
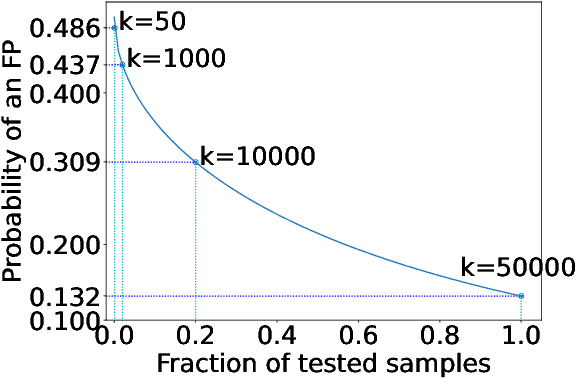
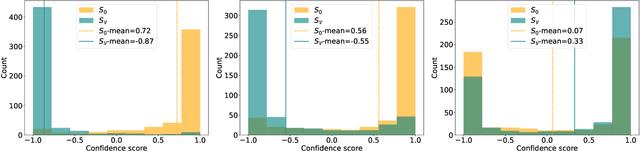

Machine learning (ML) models are costly to train as they can require a significant amount of data, computational resources and technical expertise. Thus, they constitute valuable intellectual property that needs protection from adversaries wanting to steal them. Ownership verification techniques allow the victims of model stealing attacks to demonstrate that a suspect model was in fact stolen from theirs. Although a number of ownership verification techniques based on watermarking or fingerprinting have been proposed, most of them fall short either in terms of security guarantees (well-equipped adversaries can evade verification) or computational cost. A fingerprinting technique introduced at ICLR '21, Dataset Inference (DI), has been shown to offer better robustness and efficiency than prior methods. The authors of DI provided a correctness proof for linear (suspect) models. However, in the same setting, we prove that DI suffers from high false positives (FPs) -- it can incorrectly identify an independent model trained with non-overlapping data from the same distribution as stolen. We further prove that DI also triggers FPs in realistic, non-linear suspect models. We then confirm empirically that DI leads to FPs, with high confidence. Second, we show that DI also suffers from false negatives (FNs) -- an adversary can fool DI by regularising a stolen model's decision boundaries using adversarial training, thereby leading to an FN. To this end, we demonstrate that DI fails to identify a model adversarially trained from a stolen dataset -- the setting where DI is the hardest to evade. Finally, we discuss the implications of our findings, the viability of fingerprinting-based ownership verification in general, and suggest directions for future work.