 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHAPr: An Efficient and Versatile Membership Privacy Risk Metric for Machine Learning
Paper and Code

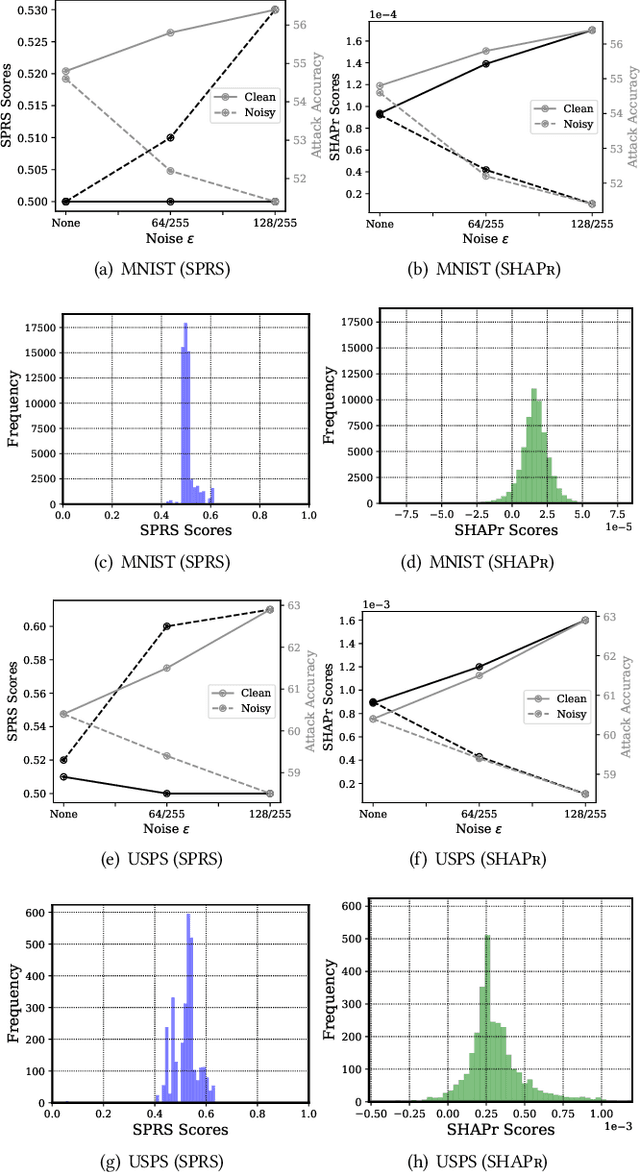
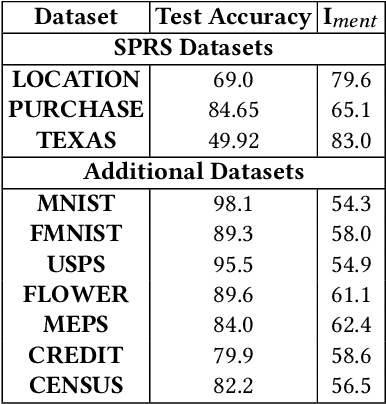

Data used to train machine learning (ML) models can be sensitive. Membership inference attacks (MIAs), attempting to determine whether a particular data record was used to train an ML model, risk violating membership privacy. ML model builders need a principled definition of a metric that enables them to quantify the privacy risk of (a) individual training data records, (b) independently of specific MIAs, (c) efficiently. None of the prior work on membership privacy risk metrics simultaneously meets all of these criteria. We propose such a metric, SHAPr, which uses Shapley values to quantify a model's memorization of an individual training data record by measuring its influence on the model's utility. This memorization is a measure of the likelihood of a successful MIA. Using ten benchmark datasets, we show that SHAPr is effective (precision: 0.94$\pm 0.06$, recall: 0.88$\pm 0.06$) in estimating susceptibility of a training data record for MIAs, and is efficient (computable within minutes for smaller datasets and in ~90 minutes for the largest dataset). SHAPr is also versatile in that it can be used for other purposes like assessing fairness or assigning valuation for subsets of a dataset. For example, we show that SHAPr correctly captures the disproportionate vulnerability of different subgroups to MIAs. Using SHAPr, we show that the membership privacy risk of a dataset is not necessarily improved by removing high risk training data records, thereby confirming an observation from prior work in a significantly extended setting (in ten datasets, removing up to 50% of data).