 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Network Model Observers Discount Signal-like Anatomical Structures During Search in Virtual Digital Breast Tomosynthesis Phantoms
May 23, 2024Model observers are computational tools to evaluate and optimize task-based medical image quality. Linear model observers, such as the Channelized Hotelling Observer (CHO), predict human accuracy in detection tasks with a few possible signal locations in clinical phantoms or real anatomic backgrounds. In recent years, Convolutional Neural Networks (CNNs) have been proposed as a new type of model observer. What is not well understood is what CNNs add over the more common linear model observer approaches. We compare the CHO and CNN detection accuracy to the radiologist's accuracy in searching for two types of signals (mass and microcalcification) embedded in 2D/3D breast tomosynthesis phantoms (DBT). We show that the CHO model's accuracy is comparable to the CNN's performance for a location-known-exactly detection task. However, for the search task with 2D/3D DBT phantoms, the CHO's detection accuracy was significantly lower than the CNN accuracy. A comparison to the radiologist's accuracy showed that the CNN but not the CHO could match or exceed the radiologist's accuracy in the 2D microcalcification and 3D mass search conditions. An analysis of the eye position showed that radiologists fixated more often and longer at the locations corresponding to CNN false positives. Most CHO false positives were the phantom's normal anatomy and were not fixated by radiologists. In conclusion, we show that CNNs can be used as an anthropomorphic model observer for the search task for which traditional linear model observers fail due to their inability to discount false positives arising from the anatomical backgrounds.
FoveaTer: Foveated Transformer for Image Classification
May 29, 2021
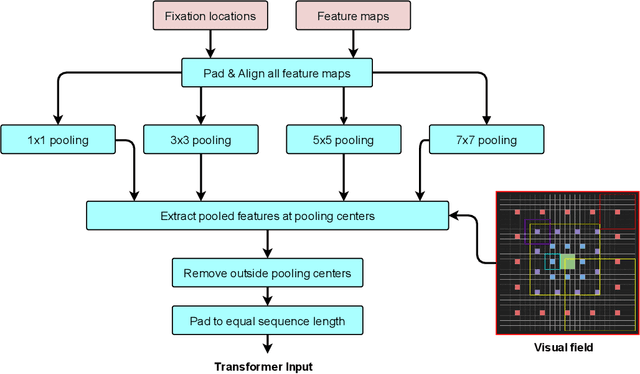
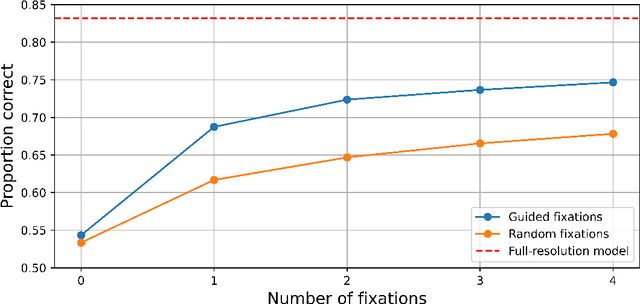
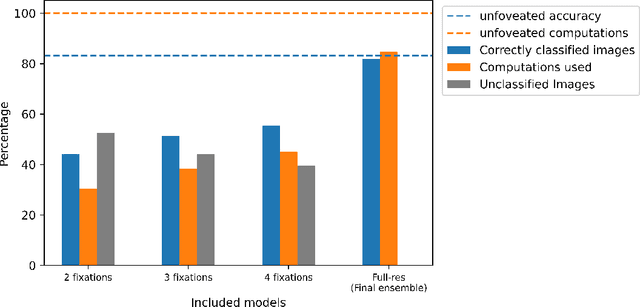
Many animals and humans process the visual field with a varying spatial resolution (foveated vision) and use peripheral processing to make eye movements and point the fovea to acquire high-resolution information about objects of interest. This architecture results in computationally efficient rapid scene exploration. Recent progress in vision Transformers has brought about new alternatives to the traditionally convolution-reliant computer vision systems. However, these models do not explicitly model the foveated properties of the visual system nor the interaction between eye movements and the classification task. We propose foveated Transformer (FoveaTer) model, which uses pooling regions and saccadic movements to perform object classification tasks using a vision Transformer architecture. Our proposed model pools the image features using squared pooling regions, an approximation to the biologically-inspired foveated architecture, and uses the pooled features as an input to a Transformer Network. It decides on the following fixation location based on the attention assigned by the Transformer to various locations from previous and present fixations. The model uses a confidence threshold to stop scene exploration, allowing to dynamically allocate more fixation/computational resources to more challenging images. We construct an ensemble model using our proposed model and unfoveated model, achieving an accuracy 1.36% below the unfoveated model with 22% computational savings. Finally, we demonstrate our model's robustness against adversarial attacks, where it outperforms the unfoveated model.
Robust Vision-Based Cheat Detection in Competitive Gaming
Mar 27, 2021



Game publishers and anti-cheat companies have been unsuccessful in blocking cheating in online gaming. We propose a novel, vision-based approach that captures the final state of the frame buffer and detects illicit overlays. To this aim, we train and evaluate a DNN detector on a new dataset, collected using two first-person shooter games and three cheating software. We study the advantages and disadvantages of different DNN architectures operating on a local or global scale. We use output confidence analysis to avoid unreliable detections and inform when network retraining is required. In an ablation study, we show how to use Interval Bound Propagation to build a detector that is also resistant to potential adversarial attacks and study its interaction with confidence analysis. Our results show that robust and effective anti-cheating through machine learning is practically feasible and can be used to guarantee fair play in online gaming.
Towards Metamerism via Foveated Style Transfer
Jun 28, 2017

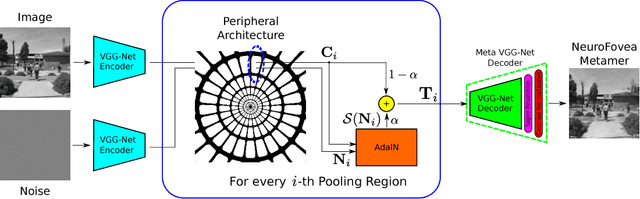
Given the recent successes of deep learning applied to style transfer and texture synthesis, we propose a new theoretical framework to construct visual metamers: \textit{a family of perceptually identical, yet physically different images}. We review work both in neuroscience related to metameric stimuli, as well as computer vision research in style transfer. We propose our NeuroFovea metamer model that is based on a mixture of peripheral representations and style transfer forward-pass algorithms for \emph{any} image from the recent work of Adaptive Instance Normalization (Huang~\&~Belongie). Our model is parametrized by a VGG-Net versus a set of joint statistics of complex wavelet coefficients which allows us to encode images in high dimensional space and interpolate between the content and texture information. We empirically show that human observers discriminate our metamers at a similar rate as the metamers of Freeman~\&~Simoncelli (FS) In addition, our NeuroFovea metamer model gives us the benefit of near real-time generation which presents a $\times1000$ speed-up compared to previous work. Critically, psychophysical studies show that both the FS and NeuroFovea metamers are discriminable from the original images highlighting an important limitation of current metamer generation methods.