 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobusto-1 Dataset: Comparing Humans and VLMs on real out-of-distribution Autonomous Driving VQA from Peru
Mar 10, 2025



As multimodal foundational models start being deployed experimentally in Self-Driving cars, a reasonable question we ask ourselves is how similar to humans do these systems respond in certain driving situations -- especially those that are out-of-distribution? To study this, we create the Robusto-1 dataset that uses dashcam video data from Peru, a country with one of the worst (aggressive) drivers in the world, a high traffic index, and a high ratio of bizarre to non-bizarre street objects likely never seen in training. In particular, to preliminarly test at a cognitive level how well Foundational Visual Language Models (VLMs) compare to Humans in Driving, we move away from bounding boxes, segmentation maps, occupancy maps or trajectory estimation to multi-modal Visual Question Answering (VQA) comparing both humans and machines through a popular method in systems neuroscience known as Representational Similarity Analysis (RSA). Depending on the type of questions we ask and the answers these systems give, we will show in what cases do VLMs and Humans converge or diverge allowing us to probe on their cognitive alignment. We find that the degree of alignment varies significantly depending on the type of questions asked to each type of system (Humans vs VLMs), highlighting a gap in their alignment.
Joint rotational invariance and adversarial training of a dual-stream Transformer yields state of the art Brain-Score for Area V4
Mar 08, 2022


Modern high-scoring models of vision in the brain score competition do not stem from Vision Transformers. However, in this short paper, we provide evidence against the unexpected trend of Vision Transformers (ViT) being not perceptually aligned with human visual representations by showing how a dual-stream Transformer, a CrossViT$~\textit{a la}$ Chen et al. (2021), under a joint rotationally-invariant and adversarial optimization procedure yields 2nd place in the aggregate Brain-Score 2022 competition averaged across all visual categories, and currently (March 1st, 2022) holds the 1st place for the highest explainable variance of area V4. In addition, our current Transformer-based model also achieves greater explainable variance for areas V4, IT and Behaviour than a biologically-inspired CNN (ResNet50) that integrates a frontal V1-like computation module(Dapello et al.,2020). Our team was also the only entry in the top-5 that shows a positive rank correlation between explained variance per area and depth in the visual hierarchy. Against our initial expectations, these results provide tentative support for an $\textit{"All roads lead to Rome"}$ argument enforced via a joint optimization rule even for non biologically-motivated models of vision such as Vision Transformers.
Finding Biological Plausibility for Adversarially Robust Features via Metameric Tasks
Feb 04, 2022
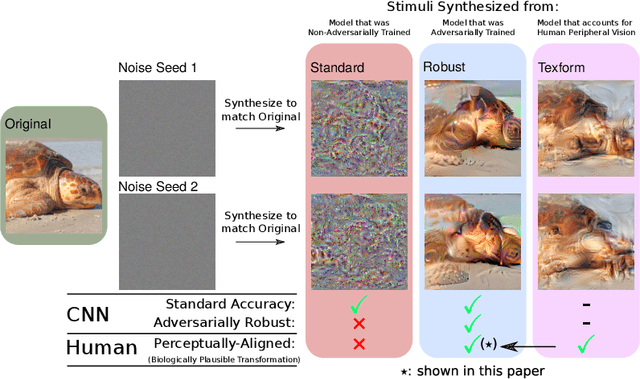
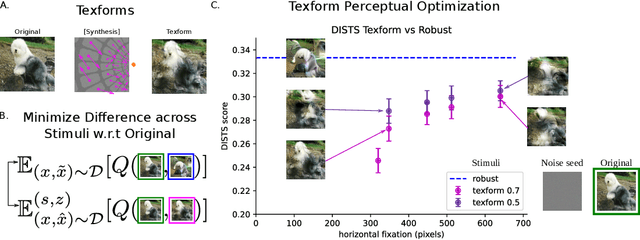
Recent work suggests that representations learned by adversarially robust networks are more human perceptually-aligned than non-robust networks via image manipulations. Despite appearing closer to human visual perception, it is unclear if the constraints in robust DNN representations match biological constraints found in human vision. Human vision seems to rely on texture-based/summary statistic representations in the periphery, which have been shown to explain phenomena such as crowding and performance on visual search tasks. To understand how adversarially robust optimizations/representations compare to human vision, we performed a psychophysics experiment using a set of metameric discrimination tasks where we evaluated how well human observers could distinguish between images synthesized to match adversarially robust representations compared to non-robust representations and a texture synthesis model of peripheral vision (Texforms). We found that the discriminability of robust representation and texture model images decreased to near chance performance as stimuli were presented farther in the periphery. Moreover, performance on robust and texture-model images showed similar trends within participants, while performance on non-robust representations changed minimally across the visual field. These results together suggest that (1) adversarially robust representations capture peripheral computation better than non-robust representations and (2) robust representations capture peripheral computation similar to current state-of-the-art texture peripheral vision models. More broadly, our findings support the idea that localized texture summary statistic representations may drive human invariance to adversarial perturbations and that the incorporation of such representations in DNNs could give rise to useful properties like adversarial robustness.
On the use of Cortical Magnification and Saccades as Biological Proxies for Data Augmentation
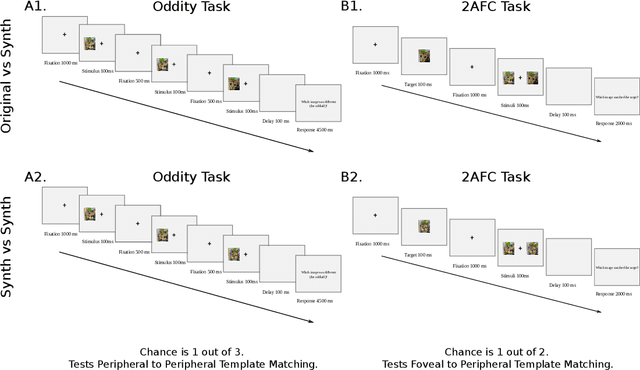
Dec 14, 2021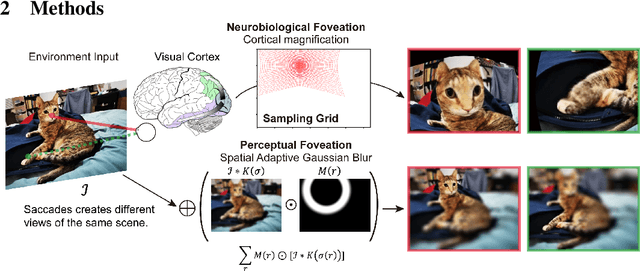
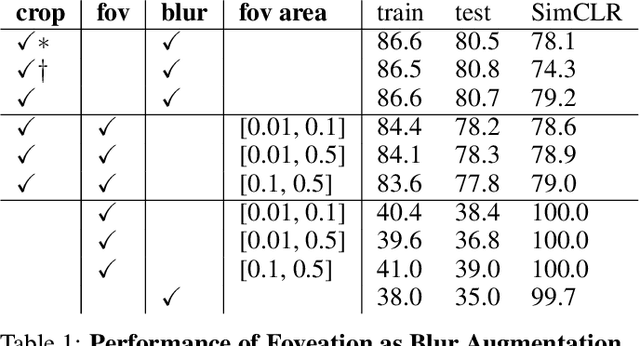
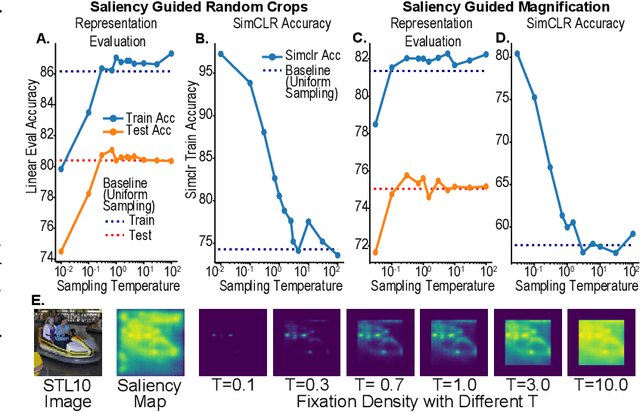
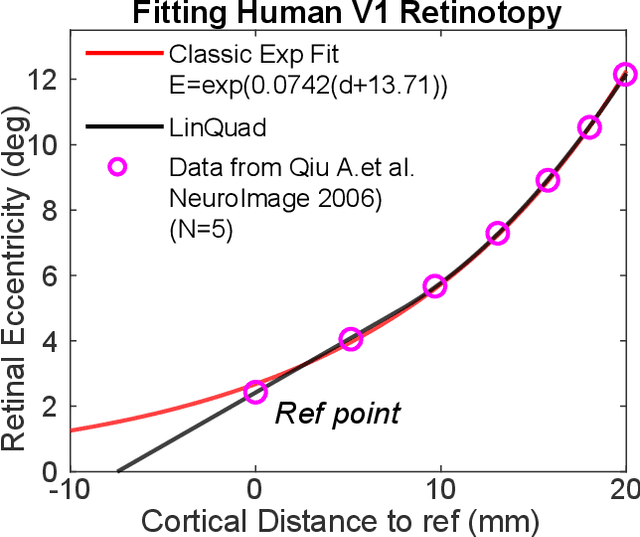
Self-supervised learning is a powerful way to learn useful representations from natural data. It has also been suggested as one possible means of building visual representation in humans, but the specific objective and algorithm are unknown. Currently, most self-supervised methods encourage the system to learn an invariant representation of different transformations of the same image in contrast to those of other images. However, such transformations are generally non-biologically plausible, and often consist of contrived perceptual schemes such as random cropping and color jittering. In this paper, we attempt to reverse-engineer these augmentations to be more biologically or perceptually plausible while still conferring the same benefits for encouraging robust representation. Critically, we find that random cropping can be substituted by cortical magnification, and saccade-like sampling of the image could also assist the representation learning. The feasibility of these transformations suggests a potential way that biological visual systems could implement self-supervision. Further, they break the widely accepted spatially-uniform processing assumption used in many computer vision algorithms, suggesting a role for spatially-adaptive computation in humans and machines alike. Our code and demo can be found here.
The Effects of Image Distribution and Task on Adversarial Robustness
Feb 21, 2021
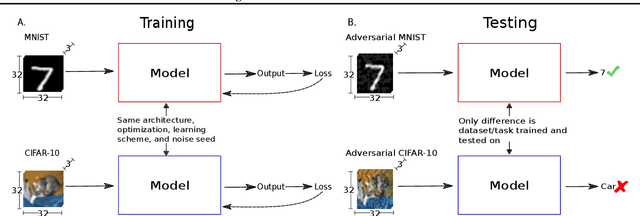


In this paper, we propose an adaptation to the area under the curve (AUC) metric to measure the adversarial robustness of a model over a particular $\epsilon$-interval $[\epsilon_0, \epsilon_1]$ (interval of adversarial perturbation strengths) that facilitates unbiased comparisons across models when they have different initial $\epsilon_0$ performance. This can be used to determine how adversarially robust a model is to different image distributions or task (or some other variable); and/or to measure how robust a model is comparatively to other models. We used this adversarial robustness metric on models of an MNIST, CIFAR-10, and a Fusion dataset (CIFAR-10 + MNIST) where trained models performed either a digit or object recognition task using a LeNet, ResNet50, or a fully connected network (FullyConnectedNet) architecture and found the following: 1) CIFAR-10 models are inherently less adversarially robust than MNIST models; 2) Both the image distribution and task that a model is trained on can affect the adversarial robustness of the resultant model. 3) Pretraining with a different image distribution and task sometimes carries over the adversarial robustness induced by that image distribution and task in the resultant model; Collectively, our results imply non-trivial differences of the learned representation space of one perceptual system over another given its exposure to different image statistics or tasks (mainly objects vs digits). Moreover, these results hold even when model systems are equalized to have the same level of performance, or when exposed to approximately matched image statistics of fusion images but with different tasks.
CUDA-Optimized real-time rendering of a Foveated Visual System
Dec 15, 2020

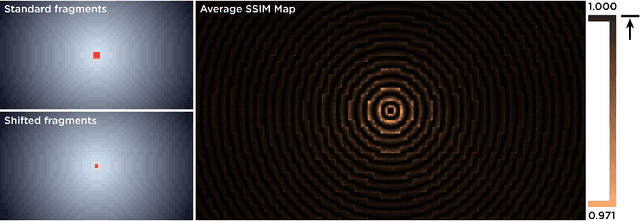
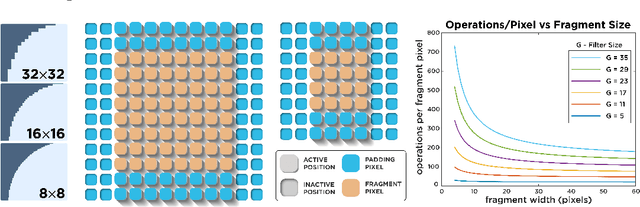
The spatially-varying field of the human visual system has recently received a resurgence of interest with the development of virtual reality (VR) and neural networks. The computational demands of high resolution rendering desired for VR can be offset by savings in the periphery, while neural networks trained with foveated input have shown perceptual gains in i.i.d and o.o.d generalization. In this paper, we present a technique that exploits the CUDA GPU architecture to efficiently generate Gaussian-based foveated images at high definition (1920x1080 px) in real-time (165 Hz), with a larger number of pooling regions than previous Gaussian-based foveation algorithms by several orders of magnitude, producing a smoothly foveated image that requires no further blending or stitching, and that can be well fit for any contrast sensitivity function. The approach described can be adapted from Gaussian blurring to any eccentricity-dependent image processing and our algorithm can meet demand for experimentation to evaluate the role of spatially-varying processing across biological and artificial agents, so that foveation can be added easily on top of existing systems rather than forcing their redesign (emulated foveated renderer). Altogether, this paper demonstrates how a GPU, with a CUDA block-wise architecture, can be employed for radially-variant rendering, with opportunities for more complex post-processing to ensure a metameric foveation scheme. Code is provided.
Hierarchically Local Tasks and Deep Convolutional Networks
Jun 29, 2020
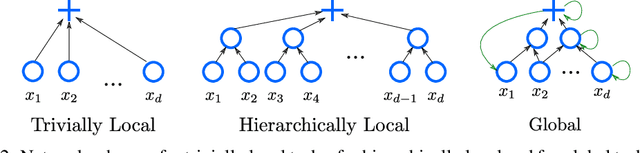
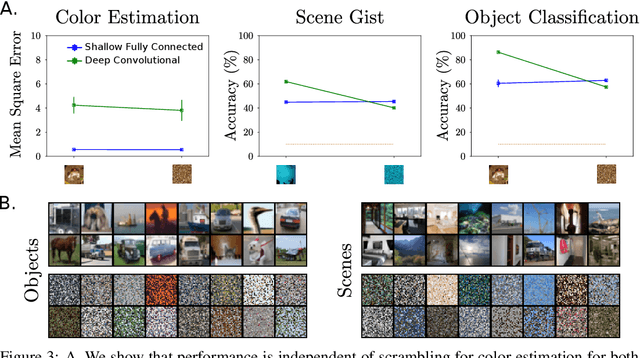
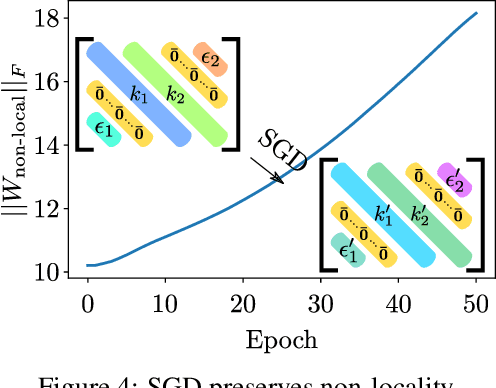
The main success stories of deep learning, starting with ImageNet, depend on convolutional networks, which on certain tasks perform significantly better than traditional shallow classifiers, such as support vector machines. Is there something special about deep convolutional networks that other learning machines do not possess? Recent results in approximation theory have shown that there is an exponential advantage of deep convolutional-like networks in approximating functions with hierarchical locality in their compositional structure. These mathematical results, however, do not say which tasks are expected to have input-output functions with hierarchical locality. Among all the possible hierarchically local tasks in vision, text and speech we explore a few of them experimentally by studying how they are affected by disrupting locality in the input images. We also discuss a taxonomy of tasks ranging from local, to hierarchically local, to global and make predictions about the type of networks required to perform efficiently on these different types of tasks.
Emergent Properties of Foveated Perceptual Systems
Jun 14, 2020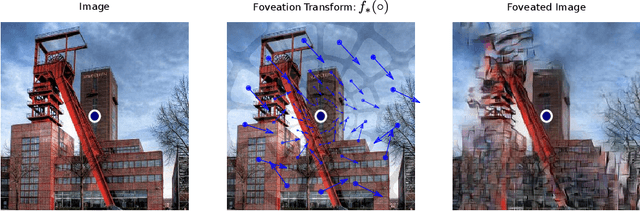
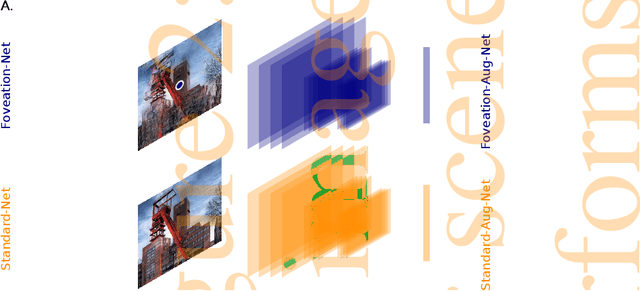
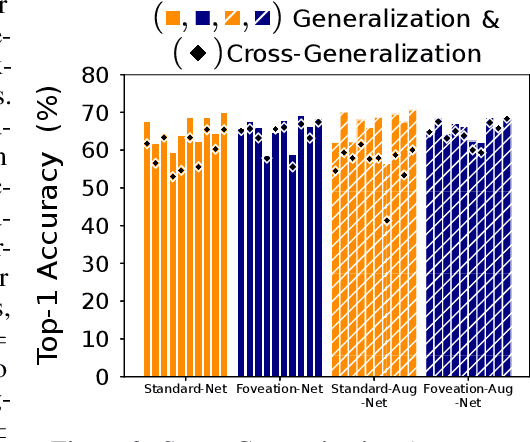
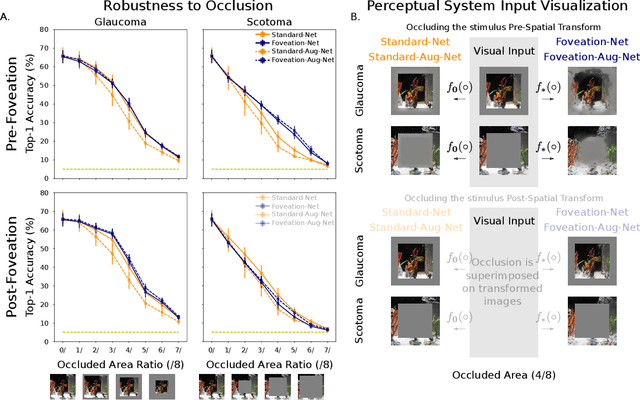
We introduce foveated perceptual systems, inspired by human biological systems, and examine the impact that this foveation stage has on the nature and robustness of subsequently learned visual representation. Specifically, these \textit{two-stage} perceptual systems first foveate an image, inducing a texture-like encoding of peripheral information, which is then inputted to a convolutional neural network (CNN) and trained to perform scene categorization. We find that: 1-- Systems trained on foveated inputs (Foveation-Nets) have similar generalization as networks trained on matched-resource networks without foveated input (Standard-Nets), yet show greater cross-generalization. 2-- Foveation-Nets show higher robustness than Standard-Nets to scotoma (fovea removed) occlusions, driven by the first foveation stage. 3-- Subsequent representations learned in the CNN of Foveation-Nets weigh center information more strongly than Standard-Nets. 4-- Foveation-Nets show less sensitivity to low-spatial frequency information than Standard-Nets. Furthermore, when we added biological and artificial augmentation mechanisms to each system through simulated eye-movements or random cropping and mirroring respectively, we found that these effects were amplified. Taken together, we find evidence that foveated perceptual systems learn a visual representation that is distinct from non-foveated perceptual systems, with implications in generalization, robustness, and perceptual sensitivity. These results provide computational support for the idea that the foveated nature of the human visual system might confer a functional advantage for scene representation.
Assessment of Faster R-CNN in Man-Machine collaborative search
Apr 04, 2019
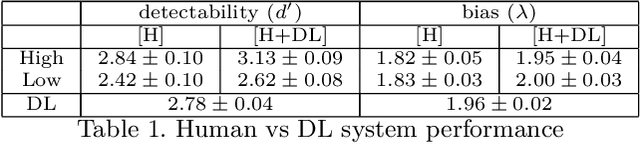


With the advent of modern expert systems driven by deep learning that supplement human experts (e.g. radiologists, dermatologists, surveillance scanners), we analyze how and when do such expert systems enhance human performance in a fine-grained small target visual search task. We set up a 2 session factorial experimental design in which humans visually search for a target with and without a Deep Learning (DL) expert system. We evaluate human changes of target detection performance and eye-movements in the presence of the DL system. We find that performance improvements with the DL system (computed via a Faster R-CNN with a VGG16) interacts with observer's perceptual abilities (e.g., sensitivity). The main results include: 1) The DL system reduces the False Alarm rate per Image on average across observer groups of both high/low sensitivity; 2) Only human observers with high sensitivity perform better than the DL system, while the low sensitivity group does not surpass individual DL system performance, even when aided with the DL system itself; 3) Increases in number of trials and decrease in viewing time were mainly driven by the DL system only for the low sensitivity group. 4) The DL system aids the human observer to fixate at a target by the 3rd fixation. These results provide insights of the benefits and limitations of deep learning systems that are collaborative or competitive with humans.
Towards Metamerism via Foveated Style Transfer
Jun 28, 2017

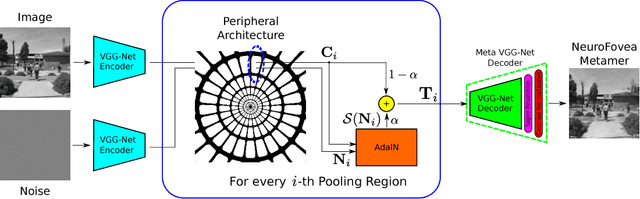
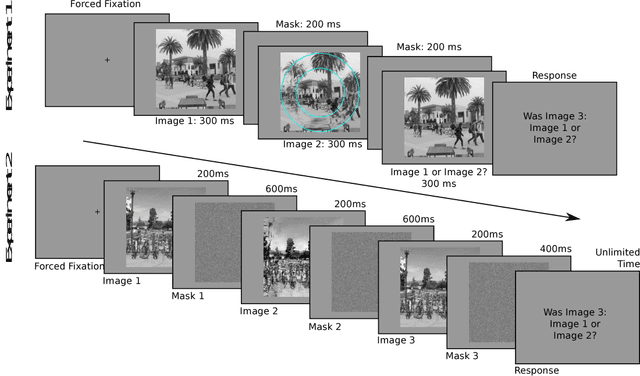
Given the recent successes of deep learning applied to style transfer and texture synthesis, we propose a new theoretical framework to construct visual metamers: \textit{a family of perceptually identical, yet physically different images}. We review work both in neuroscience related to metameric stimuli, as well as computer vision research in style transfer. We propose our NeuroFovea metamer model that is based on a mixture of peripheral representations and style transfer forward-pass algorithms for \emph{any} image from the recent work of Adaptive Instance Normalization (Huang~\&~Belongie). Our model is parametrized by a VGG-Net versus a set of joint statistics of complex wavelet coefficients which allows us to encode images in high dimensional space and interpolate between the content and texture information. We empirically show that human observers discriminate our metamers at a similar rate as the metamers of Freeman~\&~Simoncelli (FS) In addition, our NeuroFovea metamer model gives us the benefit of near real-time generation which presents a $\times1000$ speed-up compared to previous work. Critically, psychophysical studies show that both the FS and NeuroFovea metamers are discriminable from the original images highlighting an important limitation of current metamer generation methods.