 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Image Distribution and Task on Adversarial Robustness
Feb 21, 2021
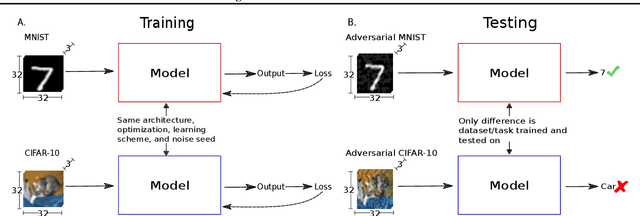


In this paper, we propose an adaptation to the area under the curve (AUC) metric to measure the adversarial robustness of a model over a particular $\epsilon$-interval $[\epsilon_0, \epsilon_1]$ (interval of adversarial perturbation strengths) that facilitates unbiased comparisons across models when they have different initial $\epsilon_0$ performance. This can be used to determine how adversarially robust a model is to different image distributions or task (or some other variable); and/or to measure how robust a model is comparatively to other models. We used this adversarial robustness metric on models of an MNIST, CIFAR-10, and a Fusion dataset (CIFAR-10 + MNIST) where trained models performed either a digit or object recognition task using a LeNet, ResNet50, or a fully connected network (FullyConnectedNet) architecture and found the following: 1) CIFAR-10 models are inherently less adversarially robust than MNIST models; 2) Both the image distribution and task that a model is trained on can affect the adversarial robustness of the resultant model. 3) Pretraining with a different image distribution and task sometimes carries over the adversarial robustness induced by that image distribution and task in the resultant model; Collectively, our results imply non-trivial differences of the learned representation space of one perceptual system over another given its exposure to different image statistics or tasks (mainly objects vs digits). Moreover, these results hold even when model systems are equalized to have the same level of performance, or when exposed to approximately matched image statistics of fusion images but with different tasks.