 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Text to Pixel: Advancing Long-Context Understanding in MLLMs
May 23, 2024



The rapid progress in Multimodal Large Language Models (MLLMs) has significantly advanced their ability to process and understand complex visual and textual information. However, the integration of multiple images and extensive textual contexts remains a challenge due to the inherent limitation of the models' capacity to handle long input sequences efficiently. In this paper, we introduce SEEKER, a multimodal large language model designed to tackle this issue. SEEKER aims to optimize the compact encoding of long text by compressing the text sequence into the visual pixel space via images, enabling the model to handle long text within a fixed token-length budget efficiently. Our empirical experiments on six long-context multimodal tasks demonstrate that SEEKER can leverage fewer image tokens to convey the same amount of textual information compared with the OCR-based approach, and is more efficient in understanding long-form multimodal input and generating long-form textual output, outperforming all existing proprietary and open-source MLLMs by large margins.
Collaborative Generative AI: Integrating GPT-k for Efficient Editing in Text-to-Image Generation
May 18, 2023



The field of text-to-image (T2I) generation has garnered significant attention both within the research community and among everyday users. Despite the advancements of T2I models, a common issue encountered by users is the need for repetitive editing of input prompts in order to receive a satisfactory image, which is time-consuming and labor-intensive. Given the demonstrated text generation power of large-scale language models, such as GPT-k, we investigate the potential of utilizing such models to improve the prompt editing process for T2I generation. We conduct a series of experiments to compare the common edits made by humans and GPT-k, evaluate the performance of GPT-k in prompting T2I, and examine factors that may influence this process. We found that GPT-k models focus more on inserting modifiers while humans tend to replace words and phrases, which includes changes to the subject matter. Experimental results show that GPT-k are more effective in adjusting modifiers rather than predicting spontaneous changes in the primary subject matters. Adopting the edit suggested by GPT-k models may reduce the percentage of remaining edits by 20-30%.
Visualize Before You Write: Imagination-Guided Open-Ended Text Generation
Oct 07, 2022
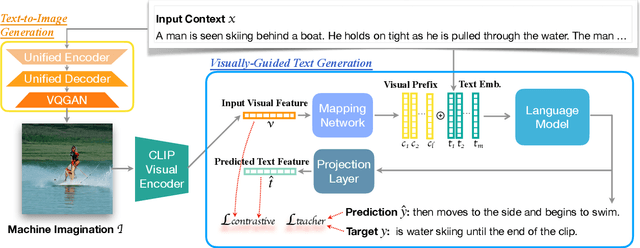
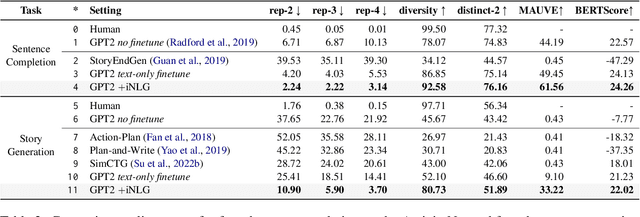
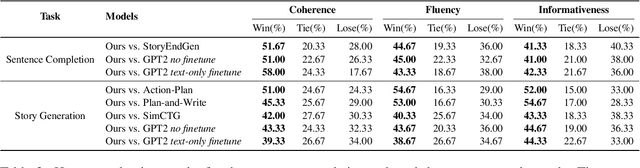
Recent advances in text-to-image synthesis make it possible to visualize machine imaginations for a given context. On the other hand, when generating text, human writers are gifted at creative visualization, which enhances their writings by forming imaginations as blueprints before putting down the stories in words. Inspired by such a cognitive process, we ask the natural question of whether we can endow machines with the same ability to utilize visual information and construct a general picture of the context to guide text generation. In this work, we propose iNLG that uses machine-generated images to guide language models (LM) in open-ended text generation. The experiments and analyses demonstrate the effectiveness of iNLG on open-ended text generation tasks, including text completion, story generation, and concept-to-text generation in few-shot scenarios. Both automatic metrics and human evaluations verify that the text snippets generated by our iNLG are coherent and informative while displaying minor degeneration.
Neuro-Symbolic Causal Language Planning with Commonsense Prompting
Jun 06, 2022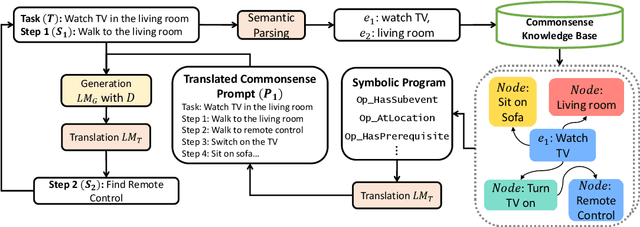


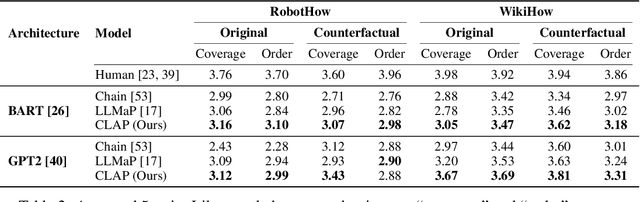
Language planning aims to implement complex high-level goals by decomposition into sequential simpler low-level steps. Such procedural reasoning ability is essential for applications such as household robots and virtual assistants. Although language planning is a basic skill set for humans in daily life, it remains a challenge for large language models (LLMs) that lack deep-level commonsense knowledge in the real world. Previous methods require either manual exemplars or annotated programs to acquire such ability from LLMs. In contrast, this paper proposes Neuro-Symbolic Causal Language Planner (CLAP) that elicits procedural knowledge from the LLMs with commonsense-infused prompting. Pre-trained knowledge in LLMs is essentially an unobserved confounder that causes spurious correlations between tasks and action plans. Through the lens of a Structural Causal Model (SCM), we propose an effective strategy in CLAP to construct prompts as a causal intervention toward our SCM. Using graph sampling techniques and symbolic program executors, our strategy formalizes the structured causal prompts from commonsense knowledge bases. CLAP obtains state-of-the-art performance on WikiHow and RobotHow, achieving a relative improvement of 5.28% in human evaluations under the counterfactual setting. This indicates the superiority of CLAP in causal language planning semantically and sequentially.
Imagination-Augmented Natural Language Understanding
Apr 21, 2022
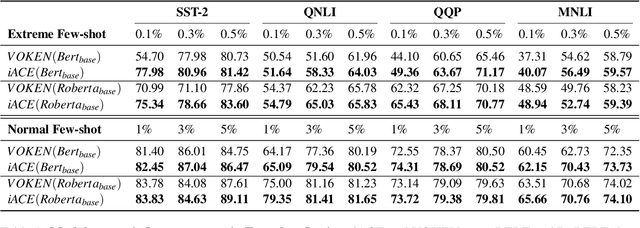
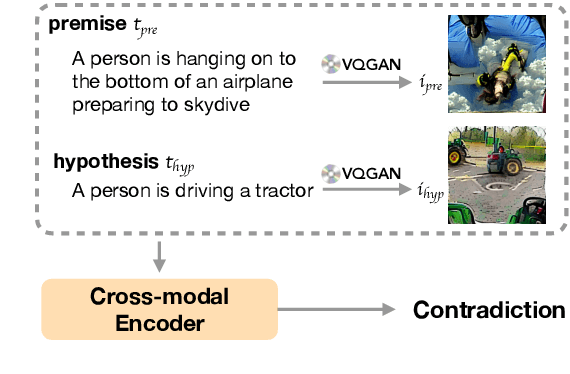
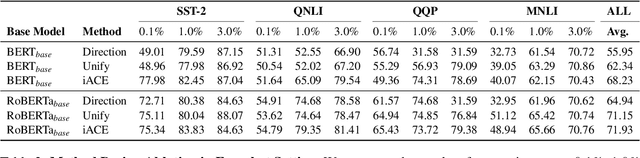
Human brains integrate linguistic and perceptual information simultaneously to understand natural language, and hold the critical ability to render imaginations. Such abilities enable us to construct new abstract concepts or concrete objects, and are essential in involving practical knowledge to solve problems in low-resource scenarios. However, most existing methods for Natural Language Understanding (NLU) are mainly focused on textual signals. They do not simulate human visual imagination ability, which hinders models from inferring and learning efficiently from limited data samples. Therefore, we introduce an Imagination-Augmented Cross-modal Encoder (iACE) to solve natural language understanding tasks from a novel learning perspective -- imagination-augmented cross-modal understanding. iACE enables visual imagination with external knowledge transferred from the powerful generative and pre-trained vision-and-language models. Extensive experiments on GLUE and SWAG show that iACE achieves consistent improvement over visually-supervised pre-trained models. More importantly, results in extreme and normal few-shot settings validate the effectiveness of iACE in low-resource natural language understanding circumstances.
ImaginE: An Imagination-Based Automatic Evaluation Metric for Natural Language Generation
Jun 10, 2021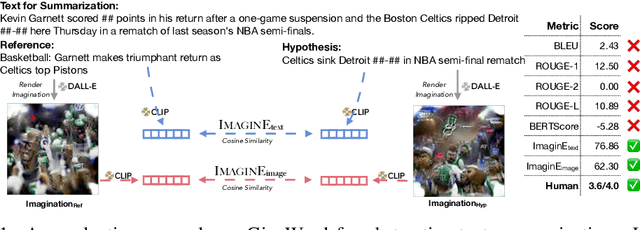
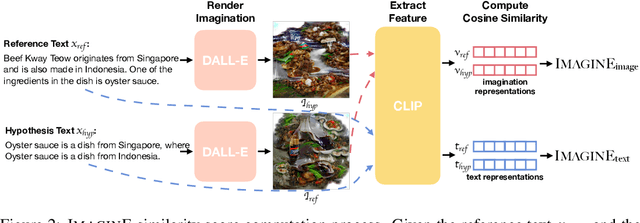
Automatic evaluations for natural language generation (NLG) conventionally rely on token-level or embedding-level comparisons with the text references. This is different from human language processing, for which visual imaginations often improve comprehension. In this work, we propose ImaginE, an imagination-based automatic evaluation metric for natural language generation. With the help of CLIP and DALL-E, two cross-modal models pre-trained on large-scale image-text pairs, we automatically generate an image as the embodied imagination for the text snippet and compute the imagination similarity using contextual embeddings. Experiments spanning several text generation tasks demonstrate that adding imagination with our ImaginE displays great potential in introducing multi-modal information into NLG evaluation, and improves existing automatic metrics' correlations with human similarity judgments in many circumstances.
Diagnosing Vision-and-Language Navigation: What Really Matters
Mar 30, 2021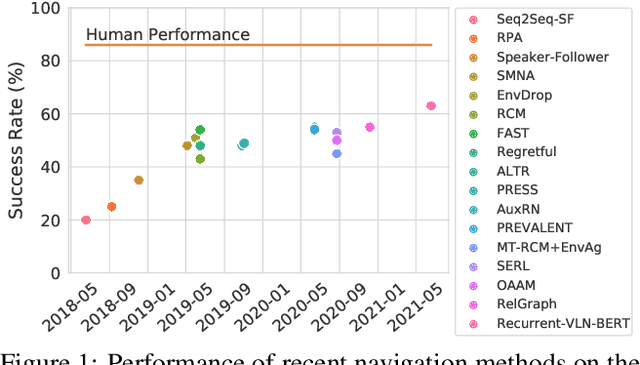

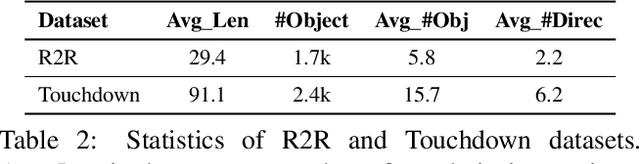
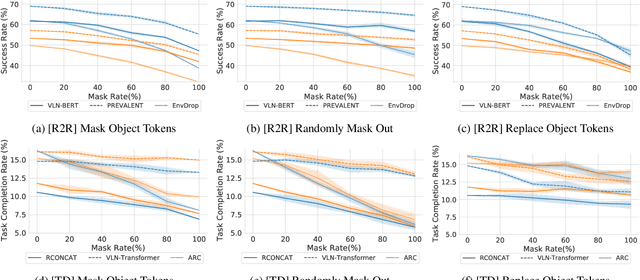
Vision-and-language navigation (VLN) is a multimodal task where an agent follows natural language instructions and navigates in visual environments. Multiple setups have been proposed, and researchers apply new model architectures or training techniques to boost navigation performance. However, recent studies witness a slow-down in the performance improvements in both indoor and outdoor VLN tasks, and the agents' inner mechanisms for making navigation decisions remain unclear. To the best of our knowledge, the way the agents perceive the multimodal input is under-studied and clearly needs investigations. In this work, we conduct a series of diagnostic experiments to unveil agents' focus during navigation. Results show that indoor navigation agents refer to both object tokens and direction tokens in the instruction when making decisions. In contrast, outdoor navigation agents heavily rely on direction tokens and have a poor understanding of the object tokens. Furthermore, instead of merely staring at surrounding objects, indoor navigation agents can set their sights on objects further from the current viewpoint. When it comes to vision-and-language alignments, many models claim that they are able to align object tokens with certain visual targets, but we cast doubt on the reliability of such alignments.
SSCR: Iterative Language-Based Image Editing via Self-Supervised Counterfactual Reasoning
Sep 29, 2020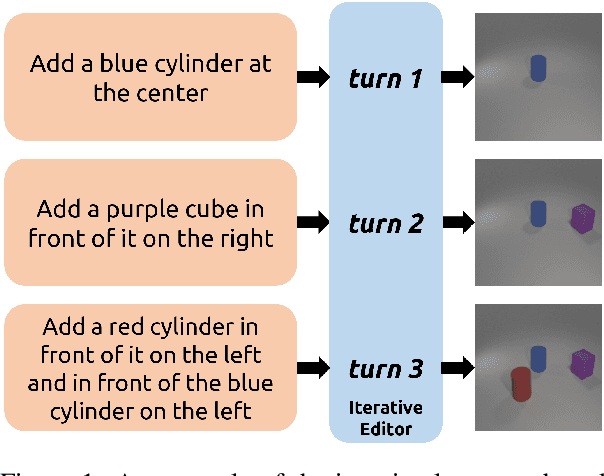

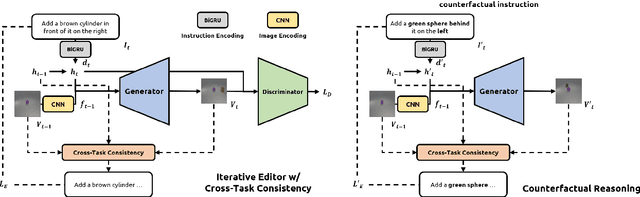
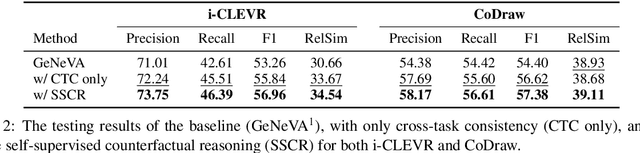
Iterative Language-Based Image Editing (IL-BIE) tasks follow iterative instructions to edit images step by step. Data scarcity is a significant issue for ILBIE as it is challenging to collect large-scale examples of images before and after instruction-based changes. However, humans still accomplish these editing tasks even when presented with an unfamiliar image-instruction pair. Such ability results from counterfactual thinking and the ability to think about alternatives to events that have happened already. In this paper, we introduce a Self-Supervised Counterfactual Reasoning (SSCR) framework that incorporates counterfactual thinking to overcome data scarcity. SSCR allows the model to consider out-of-distribution instructions paired with previous images. With the help of cross-task consistency (CTC), we train these counterfactual instructions in a self-supervised scenario. Extensive results show that SSCR improves the correctness of ILBIE in terms of both object identity and position, establishing a new state of the art (SOTA) on two IBLIE datasets (i-CLEVR and CoDraw). Even with only 50% of the training data, SSCR achieves a comparable result to using complete data.
Counterfactual Vision-and-Language Navigation via Adversarial Path Sampling
Nov 17, 2019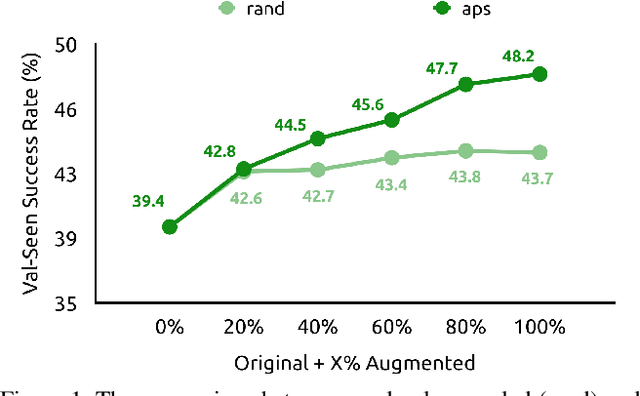
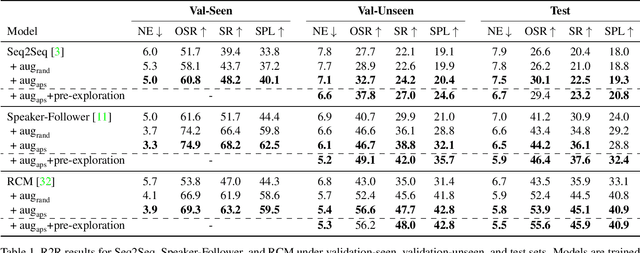

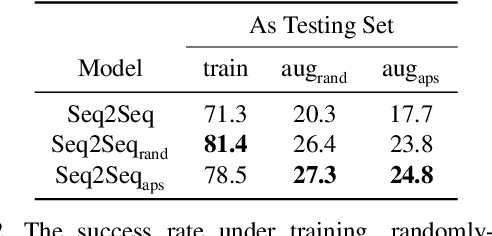
Vision-and-Language Navigation (VLN) is a task where agents must decide how to move through a 3D environment to reach a goal by grounding natural language instructions to the visual surroundings. One of the problems of the VLN task is data scarcity since it is difficult to collect enough navigation paths with human-annotated instructions for interactive environments. In this paper, we explore the use of counterfactual thinking as a human-inspired data augmentation method that results in robust models. Counterfactual thinking is a concept that describes the human propensity to create possible alternatives to life events that have already occurred. We propose an adversarial-driven counterfactual reasoning model that can consider effective conditions instead of low-quality augmented data. In particular, we present a model-agnostic adversarial path sampler (APS) that learns to sample challenging paths that force the navigator to improve based on the navigation performance. APS also serves to do pre-exploration of unseen environments to strengthen the model's ability to generalize. We evaluate the influence of APS on the performance of different VLN baseline models using the room-to-room dataset (R2R). The results show that the adversarial training process with our proposed APS benefits VLN models under both seen and unseen environments. And the pre-exploration process can further gain additional improvements under unseen environments.
Towards Metamerism via Foveated Style Transfer
Jun 28, 2017

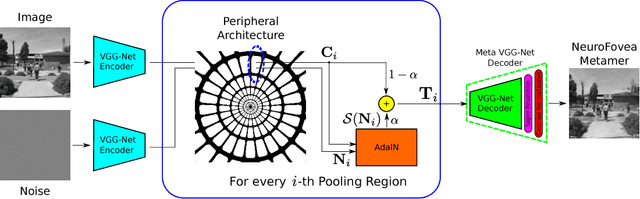
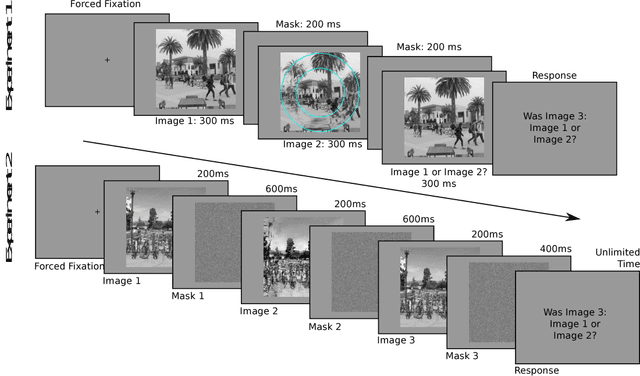
Given the recent successes of deep learning applied to style transfer and texture synthesis, we propose a new theoretical framework to construct visual metamers: \textit{a family of perceptually identical, yet physically different images}. We review work both in neuroscience related to metameric stimuli, as well as computer vision research in style transfer. We propose our NeuroFovea metamer model that is based on a mixture of peripheral representations and style transfer forward-pass algorithms for \emph{any} image from the recent work of Adaptive Instance Normalization (Huang~\&~Belongie). Our model is parametrized by a VGG-Net versus a set of joint statistics of complex wavelet coefficients which allows us to encode images in high dimensional space and interpolate between the content and texture information. We empirically show that human observers discriminate our metamers at a similar rate as the metamers of Freeman~\&~Simoncelli (FS) In addition, our NeuroFovea metamer model gives us the benefit of near real-time generation which presents a $\times1000$ speed-up compared to previous work. Critically, psychophysical studies show that both the FS and NeuroFovea metamers are discriminable from the original images highlighting an important limitation of current metamer generation methods.