 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
KAFA: Rethinking Image Ad Understanding with Knowledge-Augmented Feature Adaptation of Vision-Language Models
May 28, 2023



Image ad understanding is a crucial task with wide real-world applications. Although highly challenging with the involvement of diverse atypical scenes, real-world entities, and reasoning over scene-texts, how to interpret image ads is relatively under-explored, especially in the era of foundational vision-language models (VLMs) featuring impressive generalizability and adaptability. In this paper, we perform the first empirical study of image ad understanding through the lens of pre-trained VLMs. We benchmark and reveal practical challenges in adapting these VLMs to image ad understanding. We propose a simple feature adaptation strategy to effectively fuse multimodal information for image ads and further empower it with knowledge of real-world entities. We hope our study draws more attention to image ad understanding which is broadly relevant to the advertising industry.
Discriminative Diffusion Models as Few-shot Vision and Language Learners
May 18, 2023


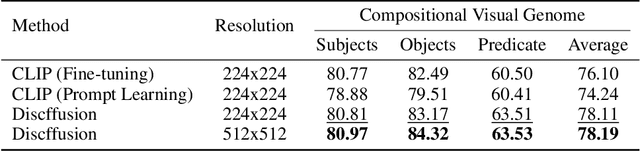
Diffusion models, such as Stable Diffusion, have shown incredible performance on text-to-image generation. Since text-to-image generation often requires models to generate visual concepts with fine-grained details and attributes specified in text prompts, can we leverage the powerful representations learned by pre-trained diffusion models for discriminative tasks such as image-text matching? To answer this question, we propose a novel approach, Discriminative Stable Diffusion (DSD), which turns pre-trained text-to-image diffusion models into few-shot discriminative learners. Our approach uses the cross-attention score of a Stable Diffusion model to capture the mutual influence between visual and textual information and fine-tune the model via attention-based prompt learning to perform image-text matching. By comparing DSD with state-of-the-art methods on several benchmark datasets, we demonstrate the potential of using pre-trained diffusion models for discriminative tasks with superior results on few-shot image-text matching.
MetaCLUE: Towards Comprehensive Visual Metaphors Research
Dec 19, 2022



Creativity is an indispensable part of human cognition and also an inherent part of how we make sense of the world. Metaphorical abstraction is fundamental in communicating creative ideas through nuanced relationships between abstract concepts such as feelings. While computer vision benchmarks and approaches predominantly focus on understanding and generating literal interpretations of images, metaphorical comprehension of images remains relatively unexplored. Towards this goal, we introduce MetaCLUE, a set of vision tasks on visual metaphor. We also collect high-quality and rich metaphor annotations (abstract objects, concepts, relationships along with their corresponding object boxes) as there do not exist any datasets that facilitate the evaluation of these tasks. We perform a comprehensive analysis of state-of-the-art models in vision and language based on our annotations, highlighting strengths and weaknesses of current approaches in visual metaphor Classification, Localization, Understanding (retrieval, question answering, captioning) and gEneration (text-to-image synthesis) tasks. We hope this work provides a concrete step towards developing AI systems with human-like creative capabilities.
Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis
Dec 09, 2022



Large-scale diffusion models have achieved state-of-the-art results on text-to-image synthesis (T2I) tasks. Despite their ability to generate high-quality yet creative images, we observe that attribution-binding and compositional capabilities are still considered major challenging issues, especially when involving multiple objects. In this work, we improve the compositional skills of T2I models, specifically more accurate attribute binding and better image compositions. To do this, we incorporate linguistic structures with the diffusion guidance process based on the controllable properties of manipulating cross-attention layers in diffusion-based T2I models. We observe that keys and values in cross-attention layers have strong semantic meanings associated with object layouts and content. Therefore, we can better preserve the compositional semantics in the generated image by manipulating the cross-attention representations based on linguistic insights. Built upon Stable Diffusion, a SOTA T2I model, our structured cross-attention design is efficient that requires no additional training samples. We achieve better compositional skills in qualitative and quantitative results, leading to a 5-8% advantage in head-to-head user comparison studies. Lastly, we conduct an in-depth analysis to reveal potential causes of incorrect image compositions and justify the properties of cross-attention layers in the generation process.
CPL: Counterfactual Prompt Learning for Vision and Language Models
Oct 19, 2022
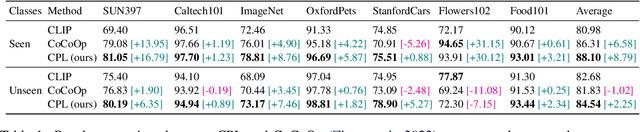
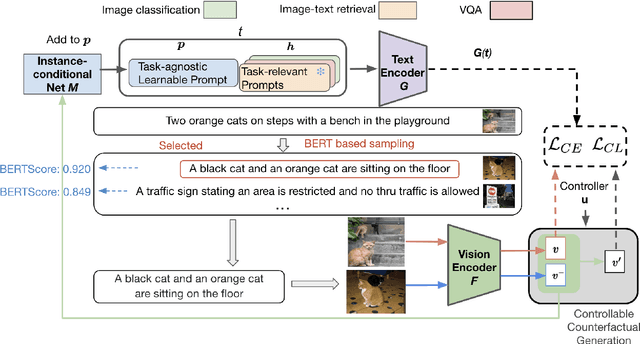
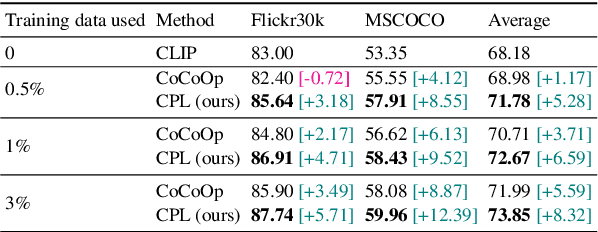
Prompt tuning is a new few-shot transfer learning technique that only tunes the learnable prompt for pre-trained vision and language models such as CLIP. However, existing prompt tuning methods tend to learn spurious or entangled representations, which leads to poor generalization to unseen concepts. Towards non-spurious and efficient prompt learning from limited examples, this paper presents a novel \underline{\textbf{C}}ounterfactual \underline{\textbf{P}}rompt \underline{\textbf{L}}earning (CPL) method for vision and language models, which simultaneously employs counterfactual generation and contrastive learning in a joint optimization framework. Particularly, CPL constructs counterfactual by identifying minimal non-spurious feature change between semantically-similar positive and negative samples that causes concept change, and learns more generalizable prompt representation from both factual and counterfactual examples via contrastive learning. Extensive experiments demonstrate that CPL can obtain superior few-shot performance on different vision and language tasks than previous prompt tuning methods on CLIP. On image classification, we achieve 3.55\% average relative improvement on unseen classes across seven datasets; on image-text retrieval and visual question answering, we gain up to 4.09\% and 25.08\% relative improvements across three few-shot scenarios on unseen test sets respectively.
Diagnosing Vision-and-Language Navigation: What Really Matters
Mar 30, 2021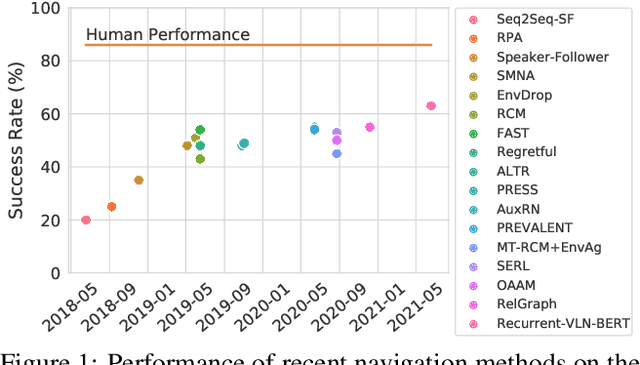

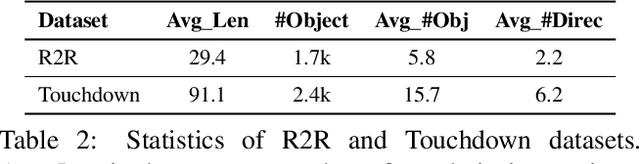
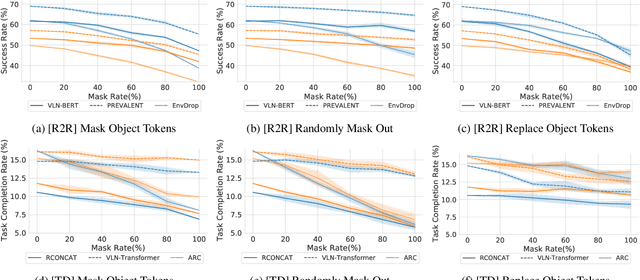
Vision-and-language navigation (VLN) is a multimodal task where an agent follows natural language instructions and navigates in visual environments. Multiple setups have been proposed, and researchers apply new model architectures or training techniques to boost navigation performance. However, recent studies witness a slow-down in the performance improvements in both indoor and outdoor VLN tasks, and the agents' inner mechanisms for making navigation decisions remain unclear. To the best of our knowledge, the way the agents perceive the multimodal input is under-studied and clearly needs investigations. In this work, we conduct a series of diagnostic experiments to unveil agents' focus during navigation. Results show that indoor navigation agents refer to both object tokens and direction tokens in the instruction when making decisions. In contrast, outdoor navigation agents heavily rely on direction tokens and have a poor understanding of the object tokens. Furthermore, instead of merely staring at surrounding objects, indoor navigation agents can set their sights on objects further from the current viewpoint. When it comes to vision-and-language alignments, many models claim that they are able to align object tokens with certain visual targets, but we cast doubt on the reliability of such alignments.
Towards Understanding Sample Variance in Visually Grounded Language Generation: Evaluations and Observations
Oct 07, 2020
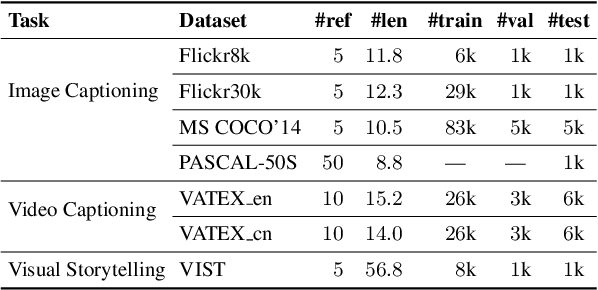
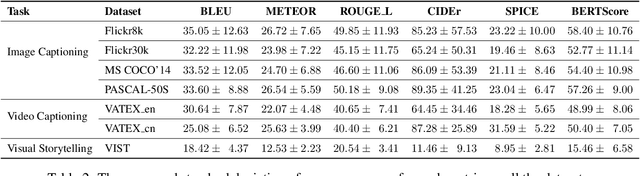
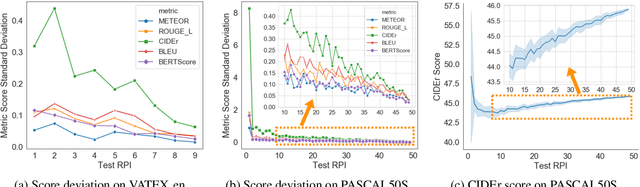
A major challenge in visually grounded language generation is to build robust benchmark datasets and models that can generalize well in real-world settings. To do this, it is critical to ensure that our evaluation protocols are correct, and benchmarks are reliable. In this work, we set forth to design a set of experiments to understand an important but often ignored problem in visually grounded language generation: given that humans have different utilities and visual attention, how will the sample variance in multi-reference datasets affect the models' performance? Empirically, we study several multi-reference datasets and corresponding vision-and-language tasks. We show that it is of paramount importance to report variance in experiments; that human-generated references could vary drastically in different datasets/tasks, revealing the nature of each task; that metric-wise, CIDEr has shown systematically larger variances than others. Our evaluations on reference-per-instance shed light on the design of reliable datasets in the future.
Leveraging Organizational Resources to Adapt Models to New Data Modalities
Aug 23, 2020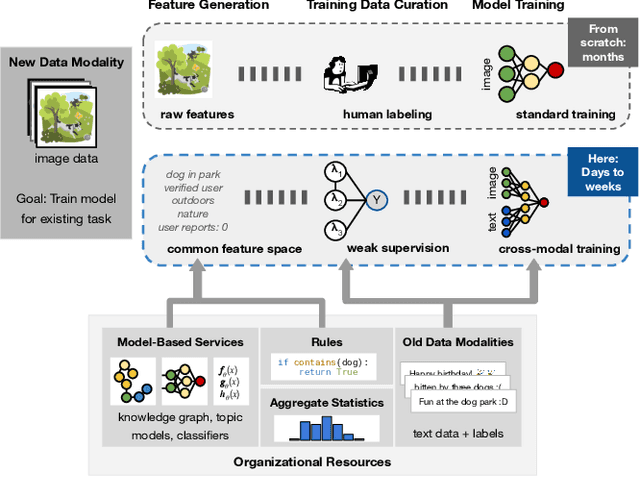

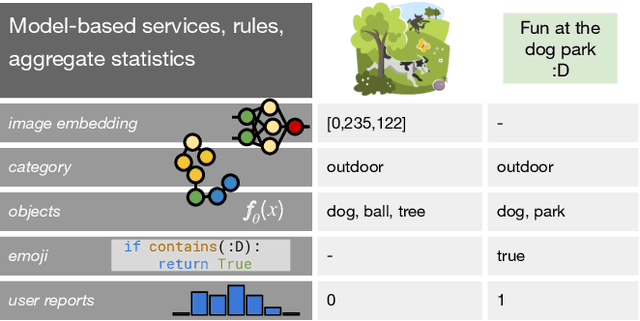
As applications in large organizations evolve, the machine learning (ML) models that power them must adapt the same predictive tasks to newly arising data modalities (e.g., a new video content launch in a social media application requires existing text or image models to extend to video). To solve this problem, organizations typically create ML pipelines from scratch. However, this fails to utilize the domain expertise and data they have cultivated from developing tasks for existing modalities. We demonstrate how organizational resources, in the form of aggregate statistics, knowledge bases, and existing services that operate over related tasks, enable teams to construct a common feature space that connects new and existing data modalities. This allows teams to apply methods for training data curation (e.g., weak supervision and label propagation) and model training (e.g., forms of multi-modal learning) across these different data modalities. We study how this use of organizational resources composes at production scale in over 5 classification tasks at Google, and demonstrate how it reduces the time needed to develop models for new modalities from months to weeks to days.
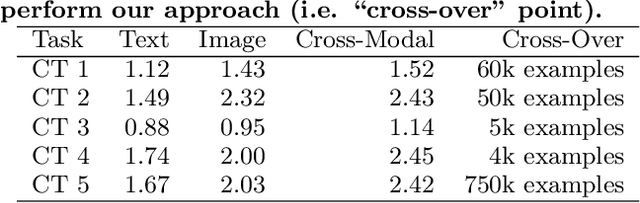
Multimodal Text Style Transfer for Outdoor Vision-and-Language Navigation
Jul 01, 2020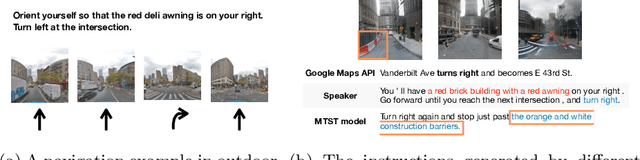
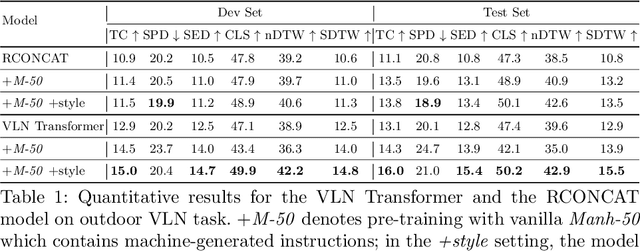
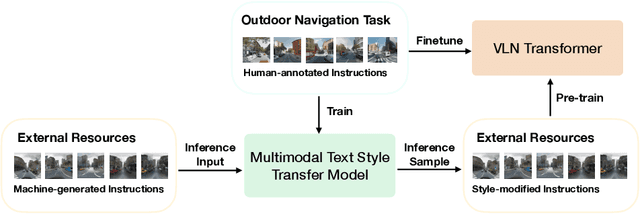

In the vision-and-language navigation (VLN) task, an agent follows natural language instructions and navigate in visual environments. Compared to the indoor navigation task that has been broadly studied, navigation in real-life outdoor environments remains a significant challenge with its complicated visual inputs and an insufficient amount of instructions that illustrate the intricate urban scenes. In this paper, we introduce a Multimodal Text Style Transfer (MTST) learning approach to mitigate the problem of data scarcity in outdoor navigation tasks by effectively leveraging external multimodal resources. We first enrich the navigation data by transferring the style of the instructions generated by Google Maps API, then pre-train the navigator with the augmented external outdoor navigation dataset. Experimental results show that our MTST learning approach is model-agnostic, and our MTST approach significantly outperforms the baseline models on the outdoor VLN task, improving task completion rate by 22\% relatively on the test set and achieving new state-of-the-art performance.