 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Organizational Resources to Adapt Models to New Data Modalities
Aug 23, 2020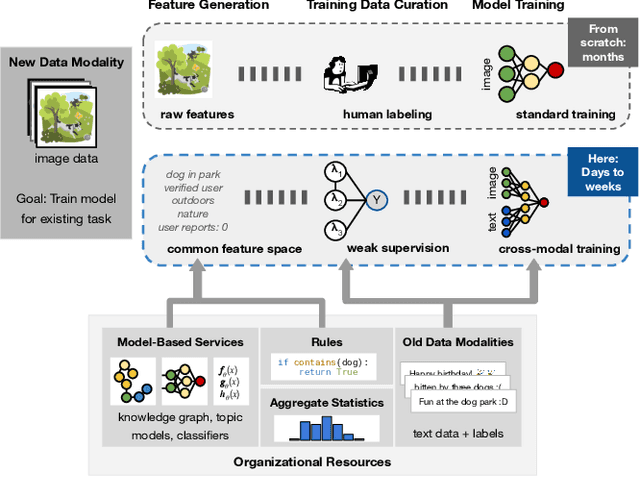

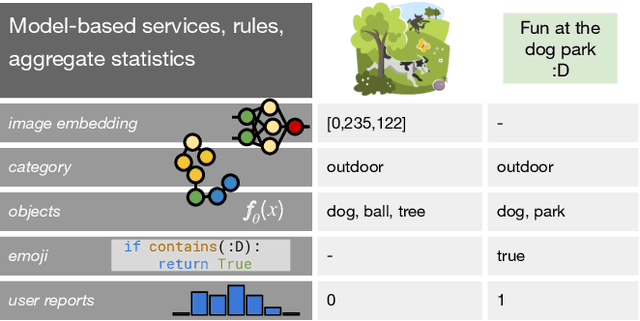
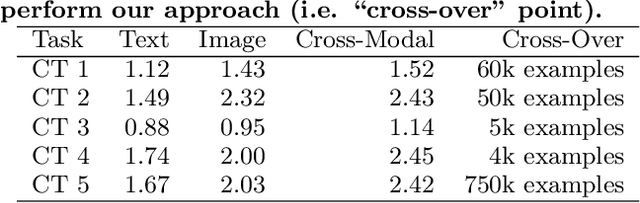
As applications in large organizations evolve, the machine learning (ML) models that power them must adapt the same predictive tasks to newly arising data modalities (e.g., a new video content launch in a social media application requires existing text or image models to extend to video). To solve this problem, organizations typically create ML pipelines from scratch. However, this fails to utilize the domain expertise and data they have cultivated from developing tasks for existing modalities. We demonstrate how organizational resources, in the form of aggregate statistics, knowledge bases, and existing services that operate over related tasks, enable teams to construct a common feature space that connects new and existing data modalities. This allows teams to apply methods for training data curation (e.g., weak supervision and label propagation) and model training (e.g., forms of multi-modal learning) across these different data modalities. We study how this use of organizational resources composes at production scale in over 5 classification tasks at Google, and demonstrate how it reduces the time needed to develop models for new modalities from months to weeks to days.
AmazonQA: A Review-Based Question Answering Task
Aug 20, 2019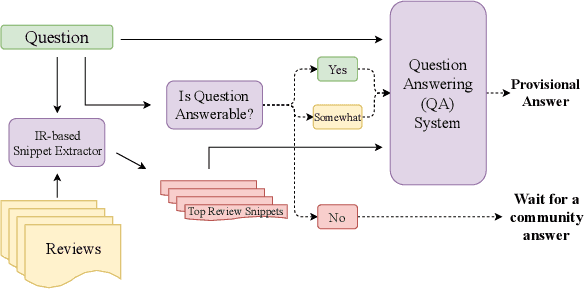
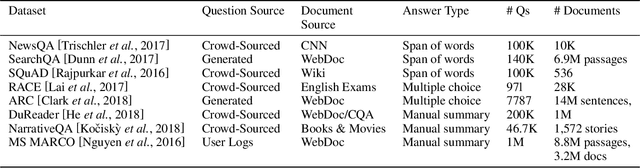
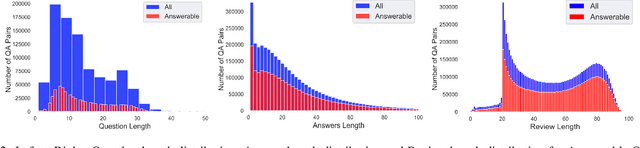
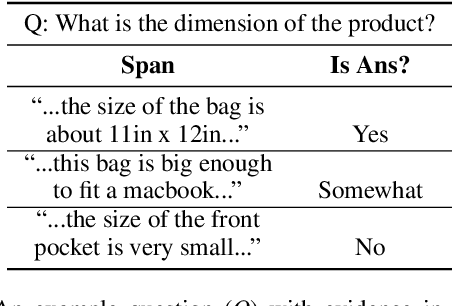
Every day, thousands of customers post questions on Amazon product pages. After some time, if they are fortunate, a knowledgeable customer might answer their question. Observing that many questions can be answered based upon the available product reviews, we propose the task of review-based QA. Given a corpus of reviews and a question, the QA system synthesizes an answer. To this end, we introduce a new dataset and propose a method that combines information retrieval techniques for selecting relevant reviews (given a question) and "reading comprehension" models for synthesizing an answer (given a question and review). Our dataset consists of 923k questions, 3.6M answers and 14M reviews across 156k products. Building on the well-known Amazon dataset, we collect additional annotations, marking each question as either answerable or unanswerable based on the available reviews. A deployed system could first classify a question as answerable and then attempt to generate an answer. Notably, unlike many popular QA datasets, here, the questions, passages, and answers are all extracted from real human interactions. We evaluate numerous models for answer generation and propose strong baselines, demonstrating the challenging nature of this new task.