 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Web Services Retrieval Using Bio Inspired Clustering
Oct 04, 2022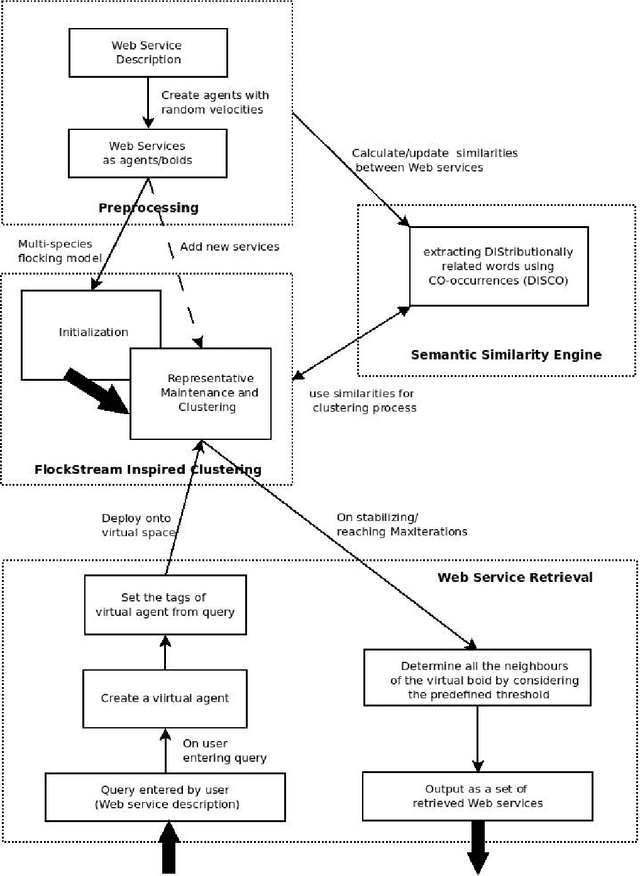
Efficiently discovering relevant Web services with respect to a specific user query has become a growing challenge owing to the incredible growth in the field of web technologies. In previous works, different clustering models have been used to address these issues. But, most of the traditional clustering techniques are computationally intensive and fail to address all the problems involved. Also, the current standards fail to incorporate the semantic relatedness of Web services during clustering and retrieval resulting in decreased performance. In this paper, we propose a framework for web services retrieval that uses a bottom-up, decentralized and self organising approach to cluster available services. It also provides online, dynamic computation of clusters thus overcoming the drawbacks of traditional clustering methods. We also use the semantic similarity between Web services for the clustering process to enhance the precision and lower the recall.
Robust self-healing prediction model for high dimensional data
Oct 04, 2022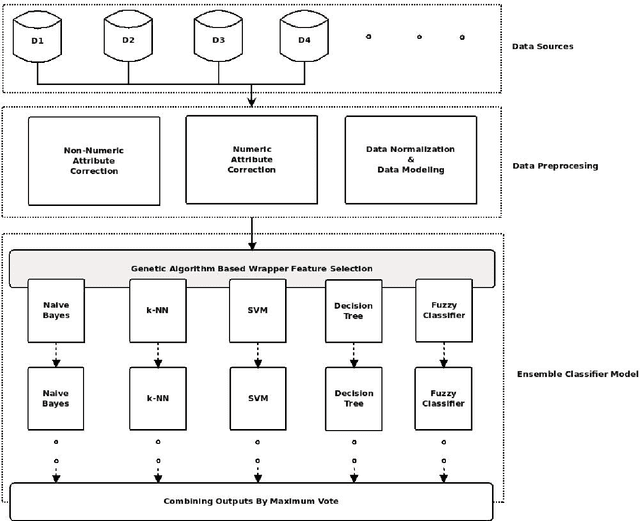
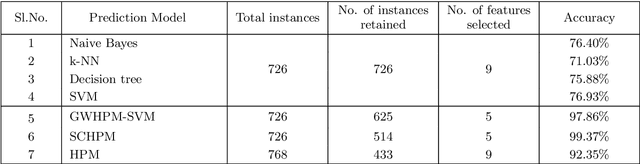
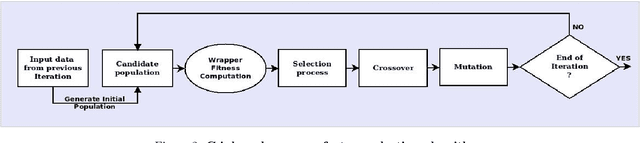
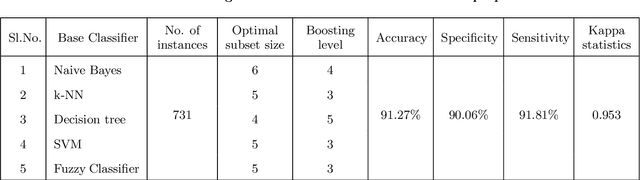
Owing to the advantages of increased accuracy and the potential to detect unseen patterns, provided by data mining techniques they have been widely incorporated for standard classification problems. They have often been used for high precision disease prediction in the medical field, and several hybrid prediction models capable of achieving high accuracies have been proposed. Though this stands true most of the previous models fail to efficiently address the recurring issue of bad data quality which plagues most high dimensional data, and especially proves troublesome in the highly sensitive medical data. This work proposes a robust self healing (RSH) hybrid prediction model which functions by using the data in its entirety by removing errors and inconsistencies from it rather than discarding any data. Initial processing involves data preparation followed by cleansing or scrubbing through context-dependent attribute correction, which ensures that there is no significant loss of relevant information before the feature selection and prediction phases. An ensemble of heterogeneous classifiers, subjected to local boosting, is utilized to build the prediction model and genetic algorithm based wrapper feature selection technique wrapped on the respective classifiers is employed to select the corresponding optimal set of features, which warrant higher accuracy. The proposed method is compared with some of the existing high performing models and the results are analyzed.
Modular Approach to Machine Reading Comprehension: Mixture of Task-Aware Experts
Oct 04, 2022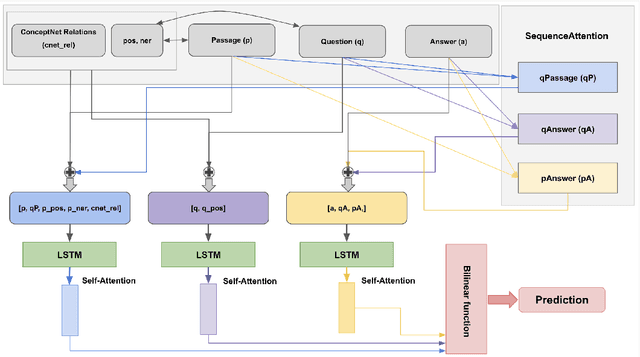

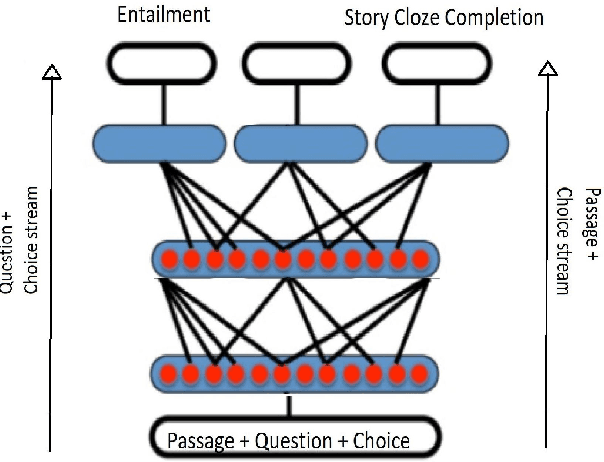
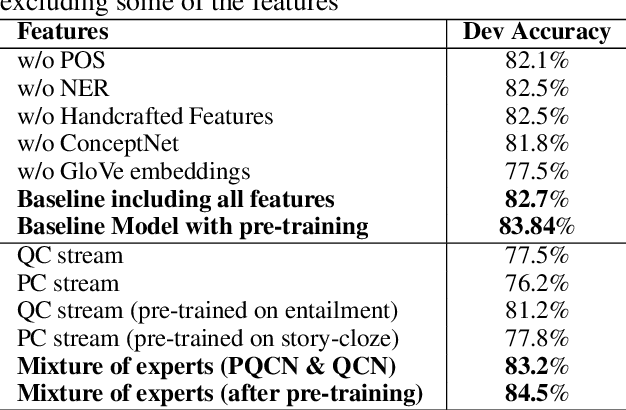
In this work we present a Mixture of Task-Aware Experts Network for Machine Reading Comprehension on a relatively small dataset. We particularly focus on the issue of common-sense learning, enforcing the common ground knowledge by specifically training different expert networks to capture different kinds of relationships between each passage, question and choice triplet. Moreover, we take inspi ration on the recent advancements of multitask and transfer learning by training each network a relevant focused task. By making the mixture-of-networks aware of a specific goal by enforcing a task and a relationship, we achieve state-of-the-art results and reduce over-fitting.
Mining Duplicate Questions of Stack Overflow
Oct 04, 2022
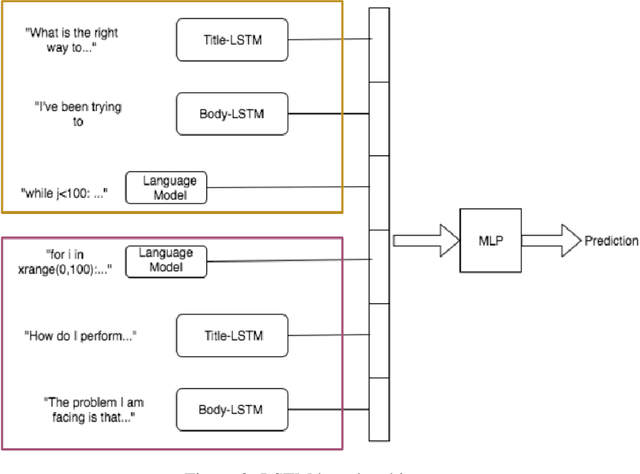
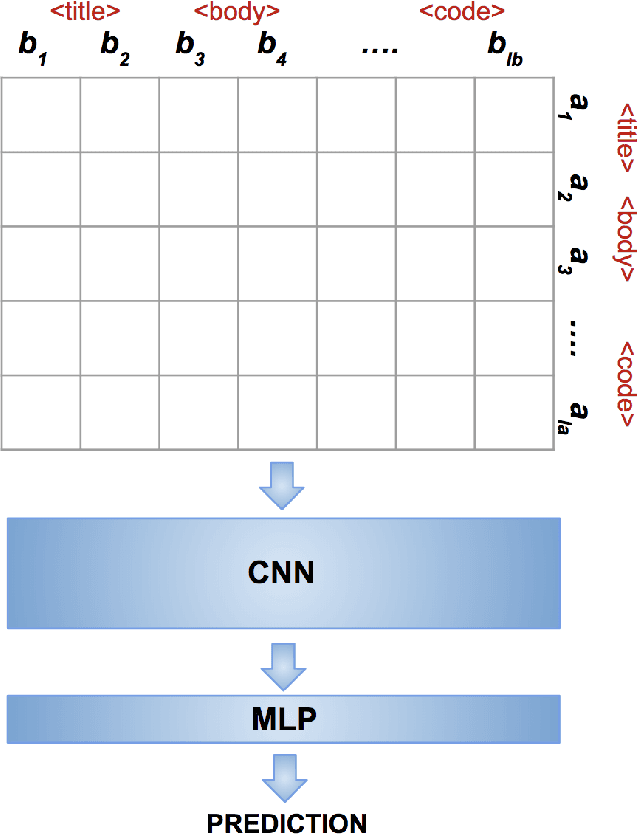
There has a been a significant rise in the use of Community Question Answering sites (CQAs) over the last decade owing primarily to their ability to leverage the wisdom of the crowd. Duplicate questions have a crippling effect on the quality of these sites. Tackling duplicate questions is therefore an important step towards improving quality of CQAs. In this regard, we propose two neural network based architectures for duplicate question detection on Stack Overflow. We also propose explicitly modeling the code present in questions to achieve results that surpass the state of the art.
AmazonQA: A Review-Based Question Answering Task
Aug 20, 2019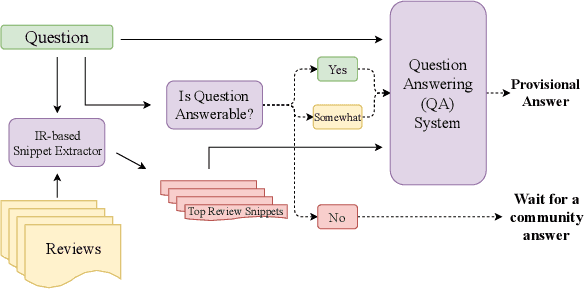
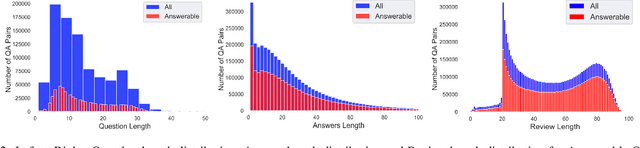
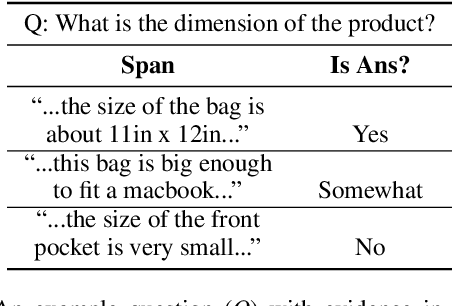
Every day, thousands of customers post questions on Amazon product pages. After some time, if they are fortunate, a knowledgeable customer might answer their question. Observing that many questions can be answered based upon the available product reviews, we propose the task of review-based QA. Given a corpus of reviews and a question, the QA system synthesizes an answer. To this end, we introduce a new dataset and propose a method that combines information retrieval techniques for selecting relevant reviews (given a question) and "reading comprehension" models for synthesizing an answer (given a question and review). Our dataset consists of 923k questions, 3.6M answers and 14M reviews across 156k products. Building on the well-known Amazon dataset, we collect additional annotations, marking each question as either answerable or unanswerable based on the available reviews. A deployed system could first classify a question as answerable and then attempt to generate an answer. Notably, unlike many popular QA datasets, here, the questions, passages, and answers are all extracted from real human interactions. We evaluate numerous models for answer generation and propose strong baselines, demonstrating the challenging nature of this new task.