 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Web Services Retrieval Using Bio Inspired Clustering
Oct 04, 2022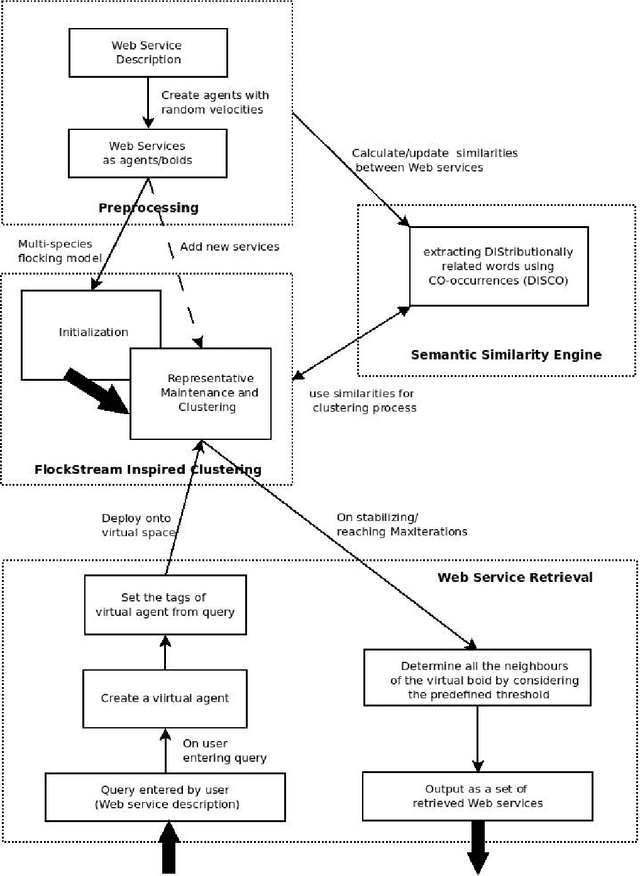
Efficiently discovering relevant Web services with respect to a specific user query has become a growing challenge owing to the incredible growth in the field of web technologies. In previous works, different clustering models have been used to address these issues. But, most of the traditional clustering techniques are computationally intensive and fail to address all the problems involved. Also, the current standards fail to incorporate the semantic relatedness of Web services during clustering and retrieval resulting in decreased performance. In this paper, we propose a framework for web services retrieval that uses a bottom-up, decentralized and self organising approach to cluster available services. It also provides online, dynamic computation of clusters thus overcoming the drawbacks of traditional clustering methods. We also use the semantic similarity between Web services for the clustering process to enhance the precision and lower the recall.