 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Duplicate Questions of Stack Overflow
Oct 04, 2022
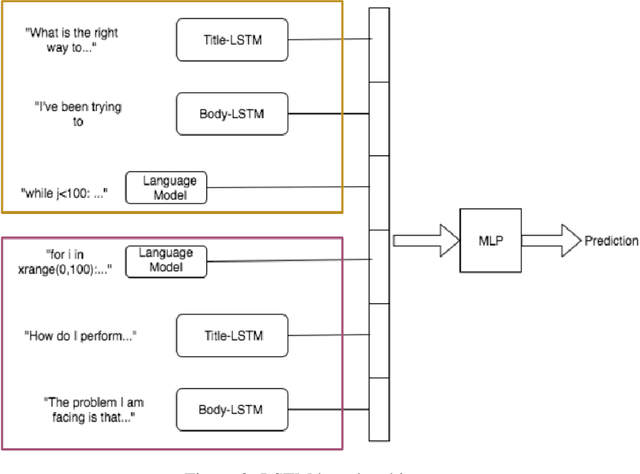
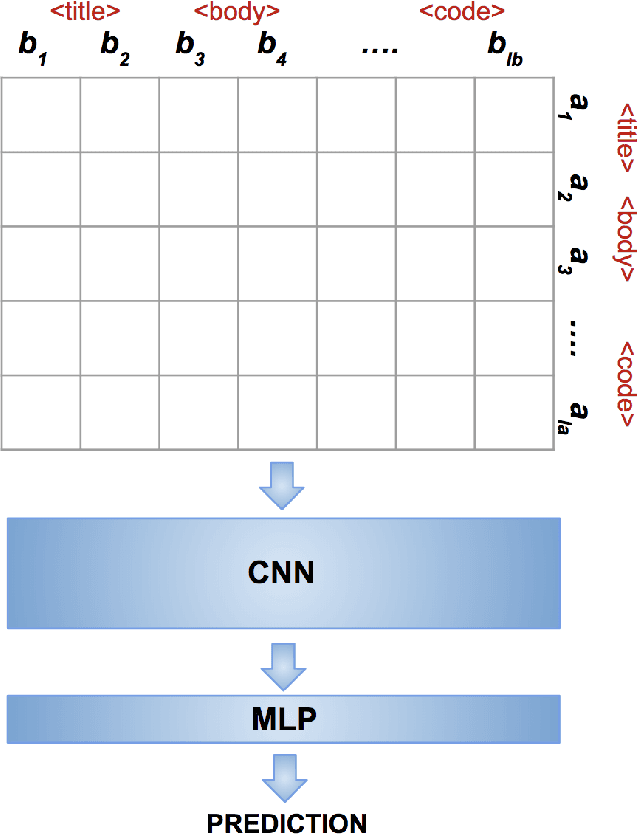
There has a been a significant rise in the use of Community Question Answering sites (CQAs) over the last decade owing primarily to their ability to leverage the wisdom of the crowd. Duplicate questions have a crippling effect on the quality of these sites. Tackling duplicate questions is therefore an important step towards improving quality of CQAs. In this regard, we propose two neural network based architectures for duplicate question detection on Stack Overflow. We also propose explicitly modeling the code present in questions to achieve results that surpass the state of the art.
Supervised Contextual Embeddings for Transfer Learning in Natural Language Processing Tasks
Jun 28, 2019


Pre-trained word embeddings are the primary method for transfer learning in several Natural Language Processing (NLP) tasks. Recent works have focused on using unsupervised techniques such as language modeling to obtain these embeddings. In contrast, this work focuses on extracting representations from multiple pre-trained supervised models, which enriches word embeddings with task and domain specific knowledge. Experiments performed in cross-task, cross-domain and cross-lingual settings indicate that such supervised embeddings are helpful, especially in the low-resource setting, but the extent of gains is dependent on the nature of the task and domain. We make our code publicly available.