 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmazonQA: A Review-Based Question Answering Task
Paper and Code
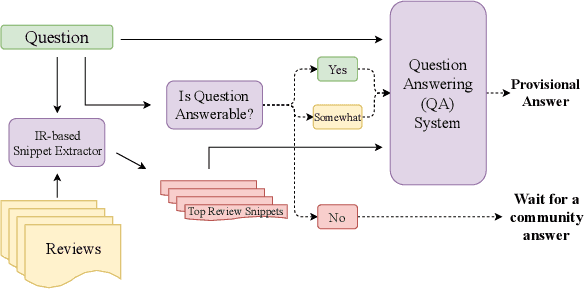
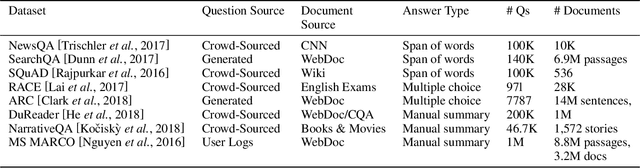
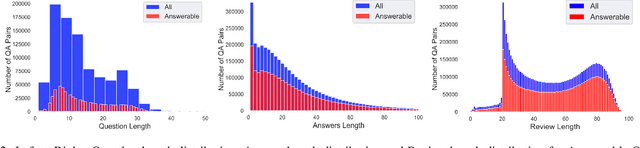
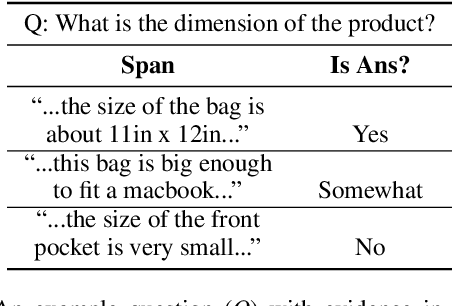
Every day, thousands of customers post questions on Amazon product pages. After some time, if they are fortunate, a knowledgeable customer might answer their question. Observing that many questions can be answered based upon the available product reviews, we propose the task of review-based QA. Given a corpus of reviews and a question, the QA system synthesizes an answer. To this end, we introduce a new dataset and propose a method that combines information retrieval techniques for selecting relevant reviews (given a question) and "reading comprehension" models for synthesizing an answer (given a question and review). Our dataset consists of 923k questions, 3.6M answers and 14M reviews across 156k products. Building on the well-known Amazon dataset, we collect additional annotations, marking each question as either answerable or unanswerable based on the available reviews. A deployed system could first classify a question as answerable and then attempt to generate an answer. Notably, unlike many popular QA datasets, here, the questions, passages, and answers are all extracted from real human interactions. We evaluate numerous models for answer generation and propose strong baselines, demonstrating the challenging nature of this new task.