 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Faithfulness in Abstractive Summarization with Contrast Candidate Generation and Selection
Apr 19, 2021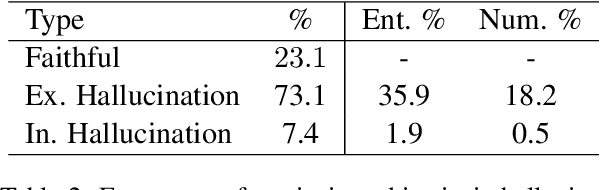
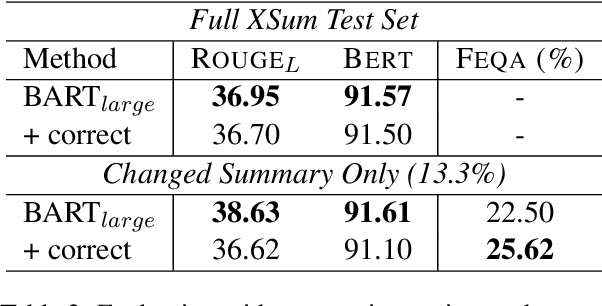


Despite significant progress in neural abstractive summarization, recent studies have shown that the current models are prone to generating summaries that are unfaithful to the original context. To address the issue, we study contrast candidate generation and selection as a model-agnostic post-processing technique to correct the extrinsic hallucinations (i.e. information not present in the source text) in unfaithful summaries. We learn a discriminative correction model by generating alternative candidate summaries where named entities and quantities in the generated summary are replaced with ones with compatible semantic types from the source document. This model is then used to select the best candidate as the final output summary. Our experiments and analysis across a number of neural summarization systems show that our proposed method is effective in identifying and correcting extrinsic hallucinations. We analyze the typical hallucination phenomenon by different types of neural summarization systems, in hope to provide insights for future work on the direction.
Diagnosing Vision-and-Language Navigation: What Really Matters
Mar 30, 2021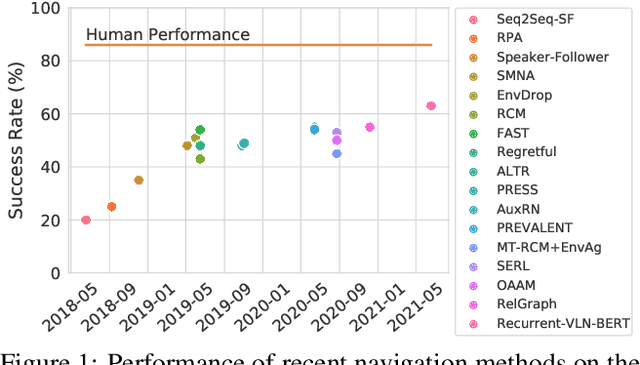

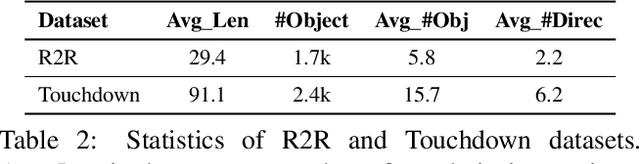
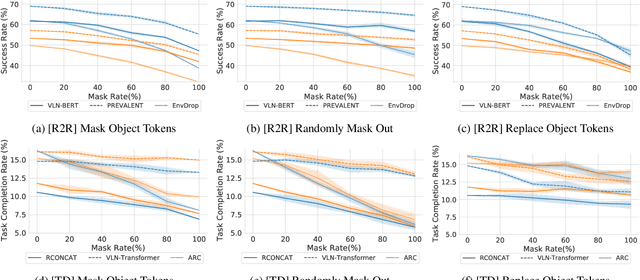
Vision-and-language navigation (VLN) is a multimodal task where an agent follows natural language instructions and navigates in visual environments. Multiple setups have been proposed, and researchers apply new model architectures or training techniques to boost navigation performance. However, recent studies witness a slow-down in the performance improvements in both indoor and outdoor VLN tasks, and the agents' inner mechanisms for making navigation decisions remain unclear. To the best of our knowledge, the way the agents perceive the multimodal input is under-studied and clearly needs investigations. In this work, we conduct a series of diagnostic experiments to unveil agents' focus during navigation. Results show that indoor navigation agents refer to both object tokens and direction tokens in the instruction when making decisions. In contrast, outdoor navigation agents heavily rely on direction tokens and have a poor understanding of the object tokens. Furthermore, instead of merely staring at surrounding objects, indoor navigation agents can set their sights on objects further from the current viewpoint. When it comes to vision-and-language alignments, many models claim that they are able to align object tokens with certain visual targets, but we cast doubt on the reliability of such alignments.
Towards Understanding Sample Variance in Visually Grounded Language Generation: Evaluations and Observations
Oct 07, 2020
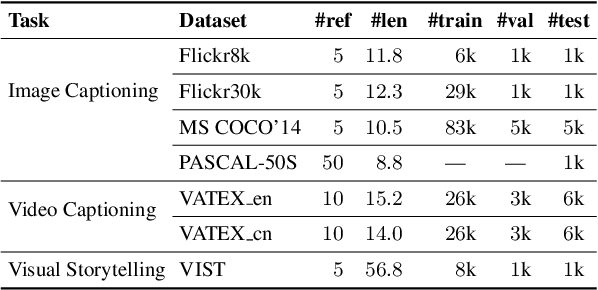
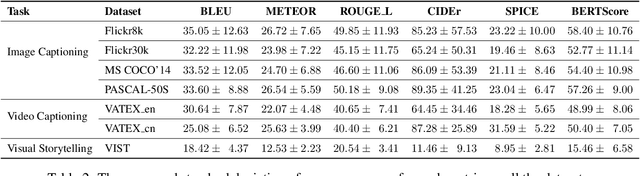
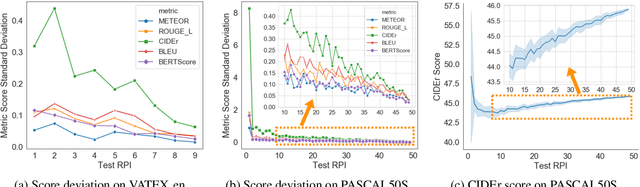
A major challenge in visually grounded language generation is to build robust benchmark datasets and models that can generalize well in real-world settings. To do this, it is critical to ensure that our evaluation protocols are correct, and benchmarks are reliable. In this work, we set forth to design a set of experiments to understand an important but often ignored problem in visually grounded language generation: given that humans have different utilities and visual attention, how will the sample variance in multi-reference datasets affect the models' performance? Empirically, we study several multi-reference datasets and corresponding vision-and-language tasks. We show that it is of paramount importance to report variance in experiments; that human-generated references could vary drastically in different datasets/tasks, revealing the nature of each task; that metric-wise, CIDEr has shown systematically larger variances than others. Our evaluations on reference-per-instance shed light on the design of reliable datasets in the future.
Multimodal Text Style Transfer for Outdoor Vision-and-Language Navigation
Jul 01, 2020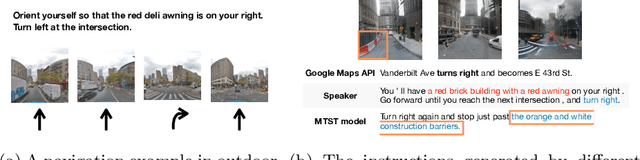
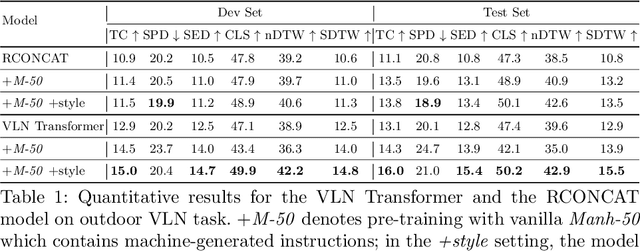
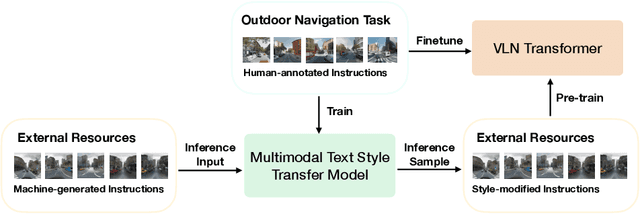

In the vision-and-language navigation (VLN) task, an agent follows natural language instructions and navigate in visual environments. Compared to the indoor navigation task that has been broadly studied, navigation in real-life outdoor environments remains a significant challenge with its complicated visual inputs and an insufficient amount of instructions that illustrate the intricate urban scenes. In this paper, we introduce a Multimodal Text Style Transfer (MTST) learning approach to mitigate the problem of data scarcity in outdoor navigation tasks by effectively leveraging external multimodal resources. We first enrich the navigation data by transferring the style of the instructions generated by Google Maps API, then pre-train the navigator with the augmented external outdoor navigation dataset. Experimental results show that our MTST learning approach is model-agnostic, and our MTST approach significantly outperforms the baseline models on the outdoor VLN task, improving task completion rate by 22\% relatively on the test set and achieving new state-of-the-art performance.
Multi-Image Summarization: Textual Summary from a Set of Cohesive Images
Jun 15, 2020

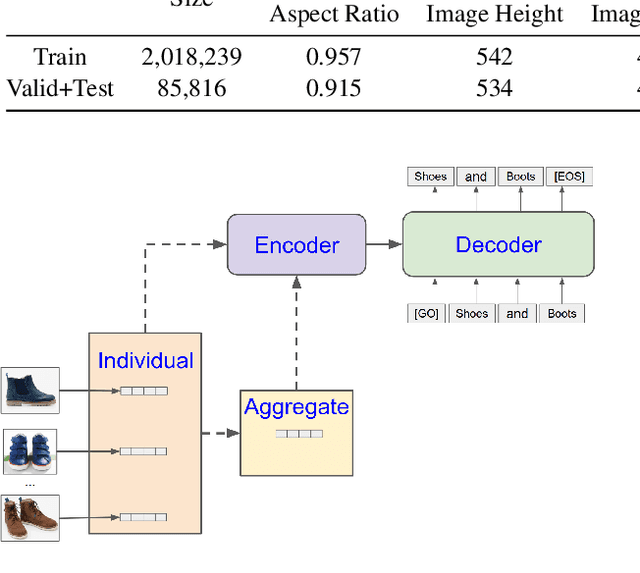

Multi-sentence summarization is a well studied problem in NLP, while generating image descriptions for a single image is a well studied problem in Computer Vision. However, for applications such as image cluster labeling or web page summarization, summarizing a set of images is also a useful and challenging task. This paper proposes the new task of multi-image summarization, which aims to generate a concise and descriptive textual summary given a coherent set of input images. We propose a model that extends the image-captioning Transformer-based architecture for single image to multi-image. A dense average image feature aggregation network allows the model to focus on a coherent subset of attributes across the input images. We explore various input representations to the Transformer network and empirically show that aggregated image features are superior to individual image embeddings. We additionally show that the performance of the model is further improved by pretraining the model parameters on a single-image captioning task, which appears to be particularly effective in eliminating hallucinations in the output.
HUSE: Hierarchical Universal Semantic Embeddings
Nov 14, 2019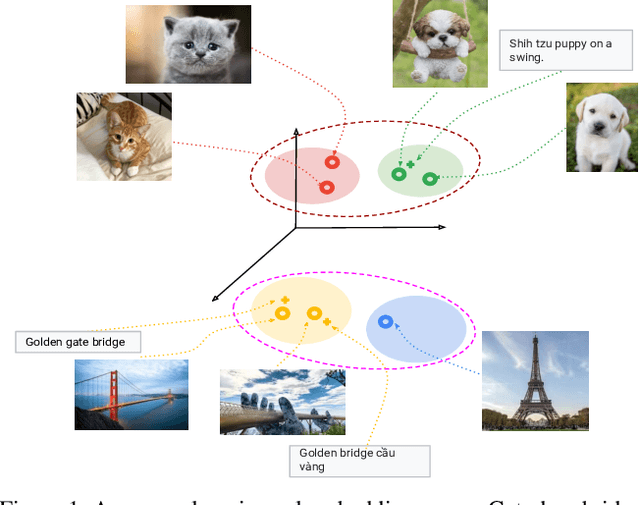
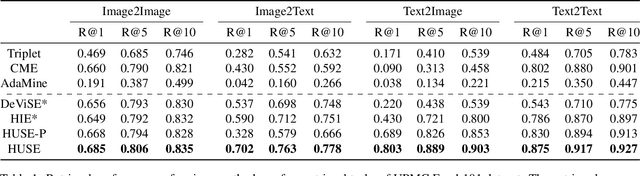
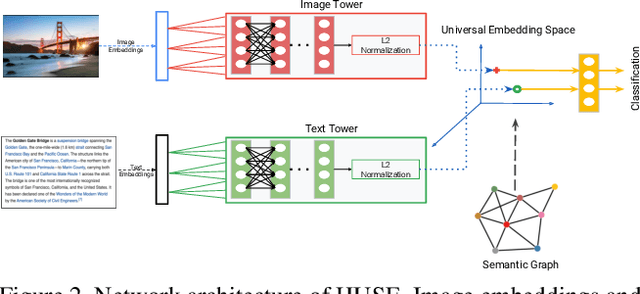

There is a recent surge of interest in cross-modal representation learning corresponding to images and text. The main challenge lies in mapping images and text to a shared latent space where the embeddings corresponding to a similar semantic concept lie closer to each other than the embeddings corresponding to different semantic concepts, irrespective of the modality. Ranking losses are commonly used to create such shared latent space -- however, they do not impose any constraints on inter-class relationships resulting in neighboring clusters to be completely unrelated. The works in the domain of visual semantic embeddings address this problem by first constructing a semantic embedding space based on some external knowledge and projecting image embeddings onto this fixed semantic embedding space. These works are confined only to image domain and constraining the embeddings to a fixed space adds additional burden on learning. This paper proposes a novel method, HUSE, to learn cross-modal representation with semantic information. HUSE learns a shared latent space where the distance between any two universal embeddings is similar to the distance between their corresponding class embeddings in the semantic embedding space. HUSE also uses a classification objective with a shared classification layer to make sure that the image and text embeddings are in the same shared latent space. Experiments on UPMC Food-101 show our method outperforms previous state-of-the-art on retrieval, hierarchical precision and classification results.