 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Image Summarization: Textual Summary from a Set of Cohesive Images
Paper and Code
Jun 15, 2020

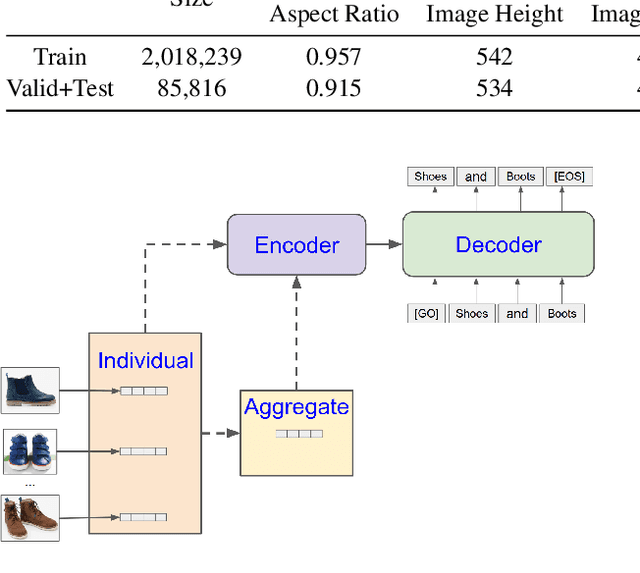

Multi-sentence summarization is a well studied problem in NLP, while generating image descriptions for a single image is a well studied problem in Computer Vision. However, for applications such as image cluster labeling or web page summarization, summarizing a set of images is also a useful and challenging task. This paper proposes the new task of multi-image summarization, which aims to generate a concise and descriptive textual summary given a coherent set of input images. We propose a model that extends the image-captioning Transformer-based architecture for single image to multi-image. A dense average image feature aggregation network allows the model to focus on a coherent subset of attributes across the input images. We explore various input representations to the Transformer network and empirically show that aggregated image features are superior to individual image embeddings. We additionally show that the performance of the model is further improved by pretraining the model parameters on a single-image captioning task, which appears to be particularly effective in eliminating hallucinations in the output.