 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualize Before You Write: Imagination-Guided Open-Ended Text Generation
Paper and Code

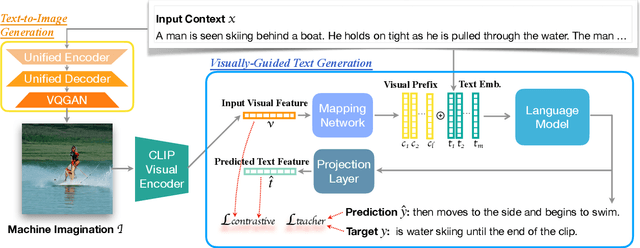
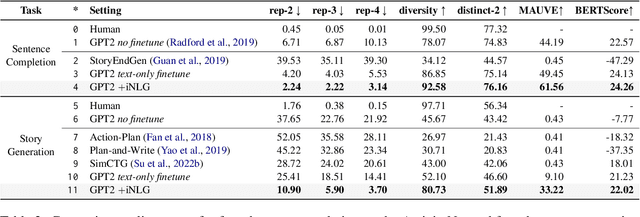
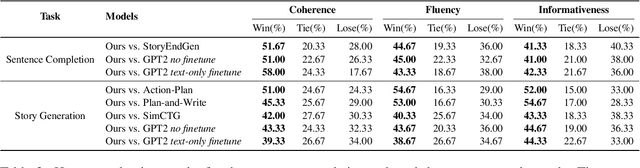
Recent advances in text-to-image synthesis make it possible to visualize machine imaginations for a given context. On the other hand, when generating text, human writers are gifted at creative visualization, which enhances their writings by forming imaginations as blueprints before putting down the stories in words. Inspired by such a cognitive process, we ask the natural question of whether we can endow machines with the same ability to utilize visual information and construct a general picture of the context to guide text generation. In this work, we propose iNLG that uses machine-generated images to guide language models (LM) in open-ended text generation. The experiments and analyses demonstrate the effectiveness of iNLG on open-ended text generation tasks, including text completion, story generation, and concept-to-text generation in few-shot scenarios. Both automatic metrics and human evaluations verify that the text snippets generated by our iNLG are coherent and informative while displaying minor degeneration.