 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe two clocks and the innovation window: When and how generative models learn rules
May 11, 2026Generative models trained on finite data face a fundamental tension: their score-matching or next-token objective converges to the empirical training distribution rather than the population distribution we seek to learn. Using rule-valid synthetic tasks, we trace this tension across two training timescales: $τ_{\mathrm{rule}}$, the step at which generations first become rule-valid, and $τ_{\mathrm{mem}}$, the step at which models begin reproducing training samples. Focusing on parity and extending to other binary rules and combinatorial puzzles, we characterize how these two clocks, $τ_{\mathrm{rule}}$ and $τ_{\mathrm{mem}}$, depend on key aspects of the learning setup. Specifically, we show that $τ_{\mathrm{rule}}$ increases with rule complexity and decreases with model capacity, while $τ_{\mathrm{mem}}$ is approximately invariant to the rule and scales nearly linearly with dataset size $N$. We define the \emph{innovation window} as the interval $[τ_{\mathrm{rule}}, τ_{\mathrm{mem}}]$. This window widens with increasing $N$ and narrows with rule complexity, and may vanish entirely when $τ_{\mathrm{rule}} \geq τ_{\mathrm{mem}}$. The same two-clock structure arises in both diffusion (DiT) and autoregressive (GPT) models, with architecture-dependent offsets. Dissecting the learned score of DiT models reveals a corresponding evolution of the optimization landscapes, where rule-valid samples' basins expand substantially around $τ_{\mathrm{rule}}$, while training samples' basins begin to dominate around $τ_{\mathrm{mem}}$. Together, these results yield a unified and predictive account of when and how generative models exhibit genuine innovation.
Differentiable Faithfulness Alignment for Cross-Model Circuit Transfer
Apr 27, 2026Mechanistic interpretability has made it possible to localize circuits underlying specific behaviors in language models, but existing methods are expensive, model-specific, and difficult to scale to larger architectures. We introduce \textbf{Differentiable Faithfulness Alignment (DFA)}, a framework that transfers circuit information from a smaller source model to a larger target model through a learned differentiable alignment. DFA projects source-model node importance scores into the target model and trains this mapping with a soft faithfulness objective, avoiding full circuit discovery on the target model. We evaluate DFA on Llama-3 and Qwen-2.5 across six tasks spanning factual retrieval, multiple-choice reasoning, and arithmetic. The strongest results occur on Llama-3 $1$B$\rightarrow3$B, where aligned circuits are often competitive with direct node attribution and zero-shot transfer remains effective. Recovery weakens for larger source--target gaps and is substantially lower on Qwen-2.5, suggesting that transfer becomes harder as architectural and scaling differences increase. Overall, DFA consistently outperforms simple baselines and, in some settings, recovers target-model circuits with faithfulness comparable to or stronger than direct attribution. These results suggest that smaller models can provide useful mechanistic priors for larger ones, while highlighting both the promise and the limits of node-level cross-model circuit alignment.\footnote{Code is available at https://github.com/jasonshaoshun/dfa-circuits.
Matching Accuracy, Different Geometry: Evolution Strategies vs GRPO in LLM Post-Training
Apr 02, 2026Evolution Strategies (ES) have emerged as a scalable gradient-free alternative to reinforcement learning based LLM fine-tuning, but it remains unclear whether comparable task performance implies comparable solutions in parameter space. We compare ES and Group Relative Policy Optimization (GRPO) across four tasks in both single-task and sequential continual-learning settings. ES matches or exceeds GRPO in single-task accuracy and remains competitive sequentially when its iteration budget is controlled. Despite this similarity in task performance, the two methods produce markedly different model updates: ES makes much larger changes and induces broader off-task KL drift, whereas GRPO makes smaller, more localized updates. Strikingly, the ES and GRPO solutions are linearly connected with no loss barrier, even though their update directions are nearly orthogonal. We develop an analytical theory of ES that explains all these phenomena within a unified framework, showing how ES can accumulate large off-task movement on weakly informative directions while still making enough progress on the task to match gradient-based RL in downstream accuracy. These results show that gradient-free and gradient-based fine-tuning can reach similarly accurate yet geometrically distinct solutions, with important consequences for forgetting and knowledge preservation. The source code is publicly available: https://github.com/Bhoy1/ESvsGRPO.
Circuit Mechanisms for Spatial Relation Generation in Diffusion Transformers
Jan 09, 2026Diffusion Transformers (DiTs) have greatly advanced text-to-image generation, but models still struggle to generate the correct spatial relations between objects as specified in the text prompt. In this study, we adopt a mechanistic interpretability approach to investigate how a DiT can generate correct spatial relations between objects. We train, from scratch, DiTs of different sizes with different text encoders to learn to generate images containing two objects whose attributes and spatial relations are specified in the text prompt. We find that, although all the models can learn this task to near-perfect accuracy, the underlying mechanisms differ drastically depending on the choice of text encoder. When using random text embeddings, we find that the spatial-relation information is passed to image tokens through a two-stage circuit, involving two cross-attention heads that separately read the spatial relation and single-object attributes in the text prompt. When using a pretrained text encoder (T5), we find that the DiT uses a different circuit that leverages information fusion in the text tokens, reading spatial-relation and single-object information together from a single text token. We further show that, although the in-domain performance is similar for the two settings, their robustness to out-of-domain perturbations differs, potentially suggesting the difficulty of generating correct relations in real-world scenarios.
An Analytical Theory of Power Law Spectral Bias in the Learning Dynamics of Diffusion Models
Mar 05, 2025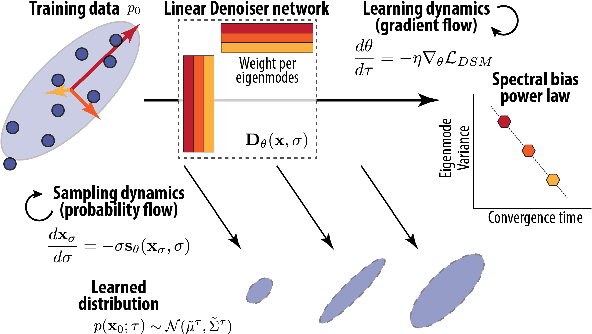

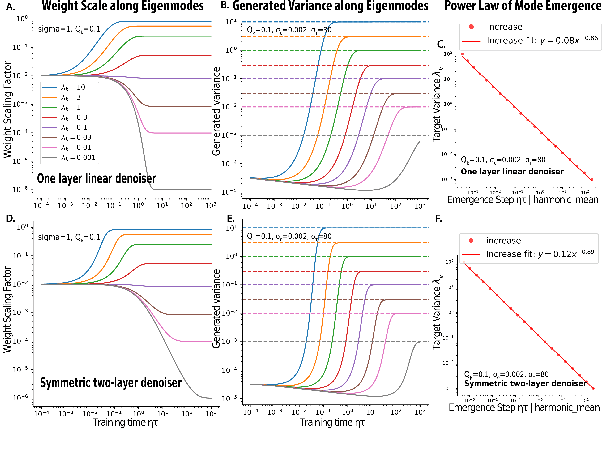
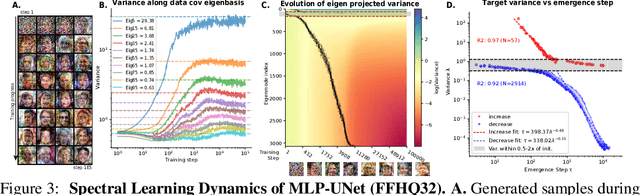
We developed an analytical framework for understanding how the learned distribution evolves during diffusion model training. Leveraging the Gaussian equivalence principle, we derived exact solutions for the gradient-flow dynamics of weights in one- or two-layer linear denoiser settings with arbitrary data. Remarkably, these solutions allowed us to derive the generated distribution in closed form and its KL divergence through training. These analytical results expose a pronounced power-law spectral bias, i.e., for weights and distributions, the convergence time of a mode follows an inverse power law of its variance. Empirical experiments on both Gaussian and image datasets demonstrate that the power-law spectral bias remains robust even when using deeper or convolutional architectures. Our results underscore the importance of the data covariance in dictating the order and rate at which diffusion models learn different modes of the data, providing potential explanations for why earlier stopping could lead to incorrect details in image generative models.
Archetypal SAE: Adaptive and Stable Dictionary Learning for Concept Extraction in Large Vision Models
Feb 18, 2025Sparse Autoencoders (SAEs) have emerged as a powerful framework for machine learning interpretability, enabling the unsupervised decomposition of model representations into a dictionary of abstract, human-interpretable concepts. However, we reveal a fundamental limitation: existing SAEs exhibit severe instability, as identical models trained on similar datasets can produce sharply different dictionaries, undermining their reliability as an interpretability tool. To address this issue, we draw inspiration from the Archetypal Analysis framework introduced by Cutler & Breiman (1994) and present Archetypal SAEs (A-SAE), wherein dictionary atoms are constrained to the convex hull of data. This geometric anchoring significantly enhances the stability of inferred dictionaries, and their mildly relaxed variants RA-SAEs further match state-of-the-art reconstruction abilities. To rigorously assess dictionary quality learned by SAEs, we introduce two new benchmarks that test (i) plausibility, if dictionaries recover "true" classification directions and (ii) identifiability, if dictionaries disentangle synthetic concept mixtures. Across all evaluations, RA-SAEs consistently yield more structured representations while uncovering novel, semantically meaningful concepts in large-scale vision models.
The Unreasonable Effectiveness of Gaussian Score Approximation for Diffusion Models and its Applications
Dec 12, 2024
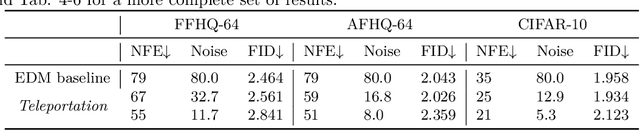
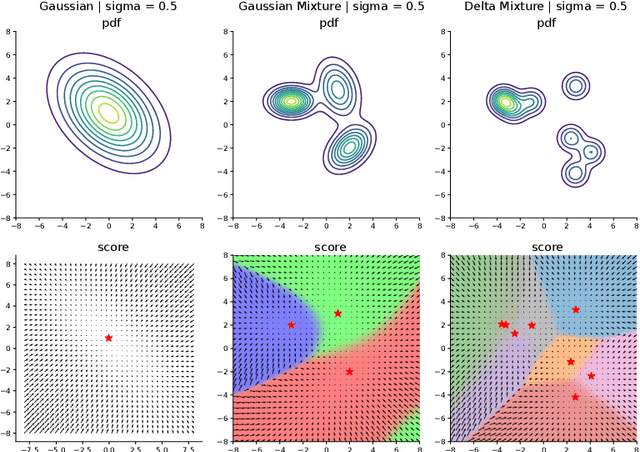

By learning the gradient of smoothed data distributions, diffusion models can iteratively generate samples from complex distributions. The learned score function enables their generalization capabilities, but how the learned score relates to the score of the underlying data manifold remains largely unclear. Here, we aim to elucidate this relationship by comparing learned neural scores to the scores of two kinds of analytically tractable distributions: Gaussians and Gaussian mixtures. The simplicity of the Gaussian model makes it theoretically attractive, and we show that it admits a closed-form solution and predicts many qualitative aspects of sample generation dynamics. We claim that the learned neural score is dominated by its linear (Gaussian) approximation for moderate to high noise scales, and supply both theoretical and empirical arguments to support this claim. Moreover, the Gaussian approximation empirically works for a larger range of noise scales than naive theory suggests it should, and is preferentially learned early in training. At smaller noise scales, we observe that learned scores are better described by a coarse-grained (Gaussian mixture) approximation of training data than by the score of the training distribution, a finding consistent with generalization. Our findings enable us to precisely predict the initial phase of trained models' sampling trajectories through their Gaussian approximations. We show that this allows the skipping of the first 15-30% of sampling steps while maintaining high sample quality (with a near state-of-the-art FID score of 1.93 on CIFAR-10 unconditional generation). This forms the foundation of a novel hybrid sampling method, termed analytical teleportation, which can seamlessly integrate with and accelerate existing samplers, including DPM-Solver-v3 and UniPC. Our findings suggest ways to improve the design and training of diffusion models.
* 69 pages, 34 figures. Published in TMLR. Previous shorter versions at arxiv.org/abs/2303.02490 and arxiv.org/abs/2311.10892
Diverse capability and scaling of diffusion and auto-regressive models when learning abstract rules
Nov 12, 2024



Humans excel at discovering regular structures from limited samples and applying inferred rules to novel settings. We investigate whether modern generative models can similarly learn underlying rules from finite samples and perform reasoning through conditional sampling. Inspired by Raven's Progressive Matrices task, we designed GenRAVEN dataset, where each sample consists of three rows, and one of 40 relational rules governing the object position, number, or attributes applies to all rows. We trained generative models to learn the data distribution, where samples are encoded as integer arrays to focus on rule learning. We compared two generative model families: diffusion (EDM, DiT, SiT) and autoregressive models (GPT2, Mamba). We evaluated their ability to generate structurally consistent samples and perform panel completion via unconditional and conditional sampling. We found diffusion models excel at unconditional generation, producing more novel and consistent samples from scratch and memorizing less, but performing less well in panel completion, even with advanced conditional sampling methods. Conversely, autoregressive models excel at completing missing panels in a rule-consistent manner but generate less consistent samples unconditionally. We observe diverse data scaling behaviors: for both model families, rule learning emerges at a certain dataset size - around 1000s examples per rule. With more training data, diffusion models improve both their unconditional and conditional generation capabilities. However, for autoregressive models, while panel completion improves with more training data, unconditional generation consistency declines. Our findings highlight complementary capabilities and limitations of diffusion and autoregressive models in rule learning and reasoning tasks, suggesting avenues for further research into their mechanisms and potential for human-like reasoning.
The Hidden Linear Structure in Score-Based Models and its Application
Nov 17, 2023Score-based models have achieved remarkable results in the generative modeling of many domains. By learning the gradient of smoothed data distribution, they can iteratively generate samples from complex distribution e.g. natural images. However, is there any universal structure in the gradient field that will eventually be learned by any neural network? Here, we aim to find such structures through a normative analysis of the score function. First, we derived the closed-form solution to the scored-based model with a Gaussian score. We claimed that for well-trained diffusion models, the learned score at a high noise scale is well approximated by the linear score of Gaussian. We demonstrated this through empirical validation of pre-trained images diffusion model and theoretical analysis of the score function. This finding enabled us to precisely predict the initial diffusion trajectory using the analytical solution and to accelerate image sampling by 15-30\% by skipping the initial phase without sacrificing image quality. Our finding of the linear structure in the score-based model has implications for better model design and data pre-processing.
Diffusion Models Generate Images Like Painters: an Analytical Theory of Outline First, Details Later
Mar 04, 2023

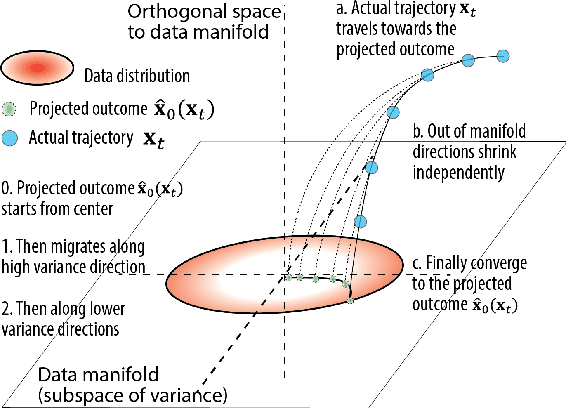
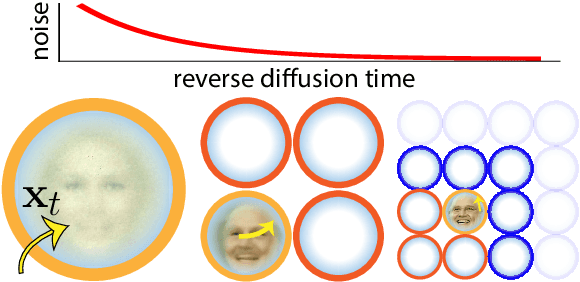
How do diffusion generative models convert pure noise into meaningful images? We argue that generation involves first committing to an outline, and then to finer and finer details. The corresponding reverse diffusion process can be modeled by dynamics on a (time-dependent) high-dimensional landscape full of Gaussian-like modes, which makes the following predictions: (i) individual trajectories tend to be very low-dimensional; (ii) scene elements that vary more within training data tend to emerge earlier; and (iii) early perturbations substantially change image content more often than late perturbations. We show that the behavior of a variety of trained unconditional and conditional diffusion models like Stable Diffusion is consistent with these predictions. Finally, we use our theory to search for the latent image manifold of diffusion models, and propose a new way to generate interpretable image variations. Our viewpoint suggests generation by GANs and diffusion models have unexpected similarities.