 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analytical Theory of Power Law Spectral Bias in the Learning Dynamics of Diffusion Models
Paper and Code
Mar 05, 2025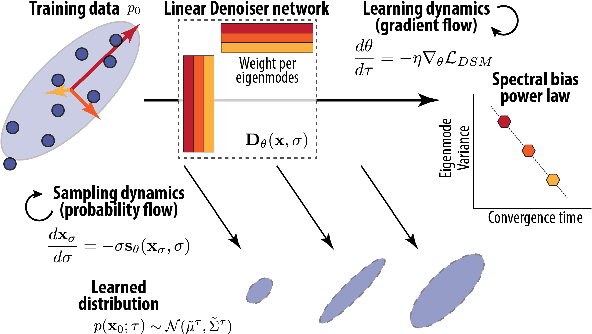

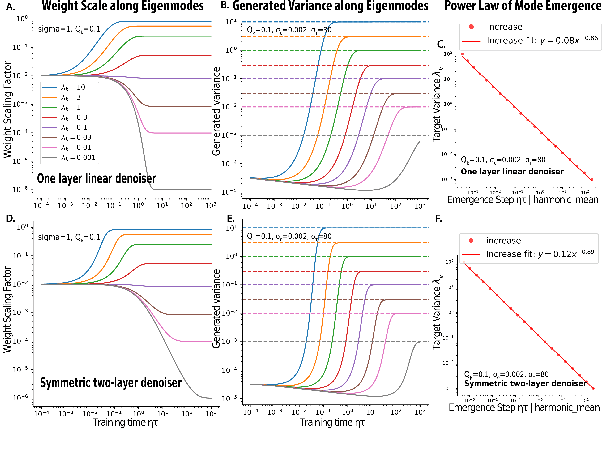
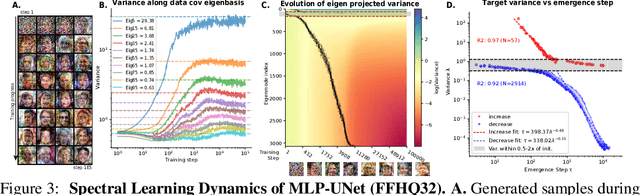
We developed an analytical framework for understanding how the learned distribution evolves during diffusion model training. Leveraging the Gaussian equivalence principle, we derived exact solutions for the gradient-flow dynamics of weights in one- or two-layer linear denoiser settings with arbitrary data. Remarkably, these solutions allowed us to derive the generated distribution in closed form and its KL divergence through training. These analytical results expose a pronounced power-law spectral bias, i.e., for weights and distributions, the convergence time of a mode follows an inverse power law of its variance. Empirical experiments on both Gaussian and image datasets demonstrate that the power-law spectral bias remains robust even when using deeper or convolutional architectures. Our results underscore the importance of the data covariance in dictating the order and rate at which diffusion models learn different modes of the data, providing potential explanations for why earlier stopping could lead to incorrect details in image generative models.