 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelations, Negations, and Numbers: Looking for Logic in Generative Text-to-Image Models
Nov 26, 2024



Despite remarkable progress in multi-modal AI research, there is a salient domain in which modern AI continues to lag considerably behind even human children: the reliable deployment of logical operators. Here, we examine three forms of logical operators: relations, negations, and discrete numbers. We asked human respondents (N=178 in total) to evaluate images generated by a state-of-the-art image-generating AI (DALL-E 3) prompted with these `logical probes', and find that none reliably produce human agreement scores greater than 50\%. The negation probes and numbers (beyond 3) fail most frequently. In a 4th experiment, we assess a `grounded diffusion' pipeline that leverages targeted prompt engineering and structured intermediate representations for greater compositional control, but find its performance is judged even worse than that of DALL-E 3 across prompts. To provide further clarity on potential sources of success and failure in these text-to-image systems, we supplement our 4 core experiments with multiple auxiliary analyses and schematic diagrams, directly quantifying, for example, the relationship between the N-gram frequency of relational prompts and the average match to generated images; the success rates for 3 different prompt modification strategies in the rendering of negation prompts; and the scalar variability / ratio dependence (`approximate numeracy') of prompts involving integers. We conclude by discussing the limitations inherent to `grounded' multimodal learning systems whose grounding relies heavily on vector-based semantics (e.g. DALL-E 3), or under-specified syntactical constraints (e.g. `grounded diffusion'), and propose minimal modifications (inspired by development, based in imagery) that could help to bridge the lingering compositional gap between scale and structure. All data and code is available at https://github.com/ColinConwell/T2I-Probology
Using Multimodal Deep Neural Networks to Disentangle Language from Visual Aesthetics
Oct 31, 2024



When we experience a visual stimulus as beautiful, how much of that experience derives from perceptual computations we cannot describe versus conceptual knowledge we can readily translate into natural language? Disentangling perception from language in visually-evoked affective and aesthetic experiences through behavioral paradigms or neuroimaging is often empirically intractable. Here, we circumnavigate this challenge by using linear decoding over the learned representations of unimodal vision, unimodal language, and multimodal (language-aligned) deep neural network (DNN) models to predict human beauty ratings of naturalistic images. We show that unimodal vision models (e.g. SimCLR) account for the vast majority of explainable variance in these ratings. Language-aligned vision models (e.g. SLIP) yield small gains relative to unimodal vision. Unimodal language models (e.g. GPT2) conditioned on visual embeddings to generate captions (via CLIPCap) yield no further gains. Caption embeddings alone yield less accurate predictions than image and caption embeddings combined (concatenated). Taken together, these results suggest that whatever words we may eventually find to describe our experience of beauty, the ineffable computations of feedforward perception may provide sufficient foundation for that experience.
Training the Untrainable: Introducing Inductive Bias via Representational Alignment
Oct 26, 2024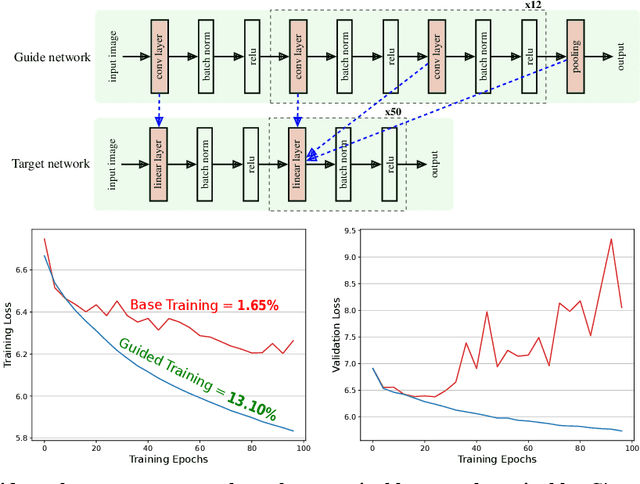
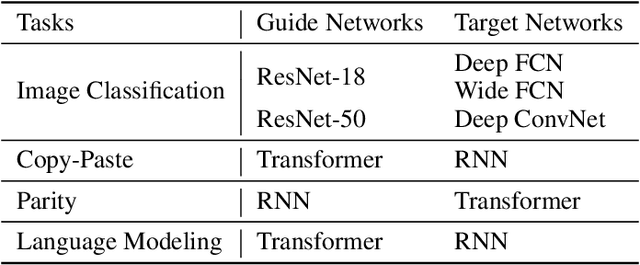
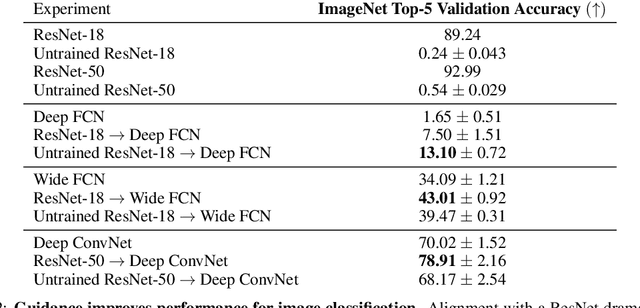
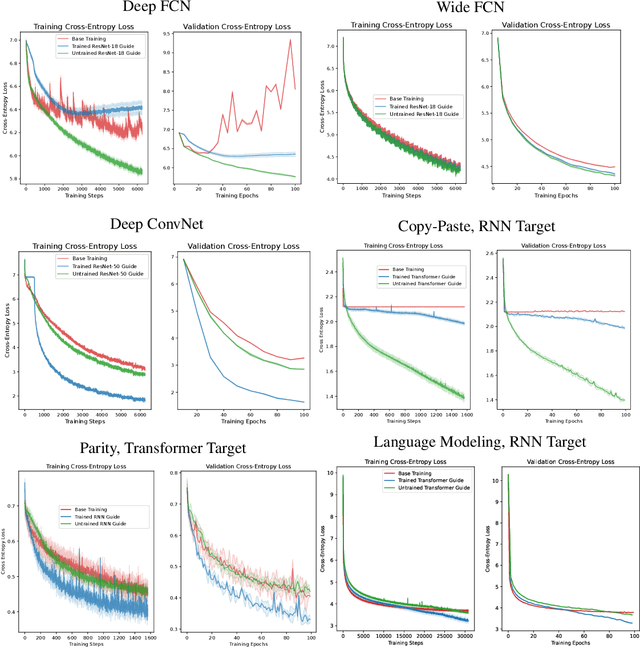
We demonstrate that architectures which traditionally are considered to be ill-suited for a task can be trained using inductive biases from another architecture. Networks are considered untrainable when they overfit, underfit, or converge to poor results even when tuning their hyperparameters. For example, plain fully connected networks overfit on object recognition while deep convolutional networks without residual connections underfit. The traditional answer is to change the architecture to impose some inductive bias, although what that bias is remains unknown. We introduce guidance, where a guide network guides a target network using a neural distance function. The target is optimized to perform well and to match its internal representations, layer-by-layer, to those of the guide; the guide is unchanged. If the guide is trained, this transfers over part of the architectural prior and knowledge of the guide to the target. If the guide is untrained, this transfers over only part of the architectural prior of the guide. In this manner, we can investigate what kinds of priors different architectures place on untrainable networks such as fully connected networks. We demonstrate that this method overcomes the immediate overfitting of fully connected networks on vision tasks, makes plain CNNs competitive to ResNets, closes much of the gap between plain vanilla RNNs and Transformers, and can even help Transformers learn tasks which RNNs can perform more easily. We also discover evidence that better initializations of fully connected networks likely exist to avoid overfitting. Our method provides a mathematical tool to investigate priors and architectures, and in the long term, may demystify the dark art of architecture creation, even perhaps turning architectures into a continuous optimizable parameter of the network.
Revealing Vision-Language Integration in the Brain with Multimodal Networks
Jun 20, 2024

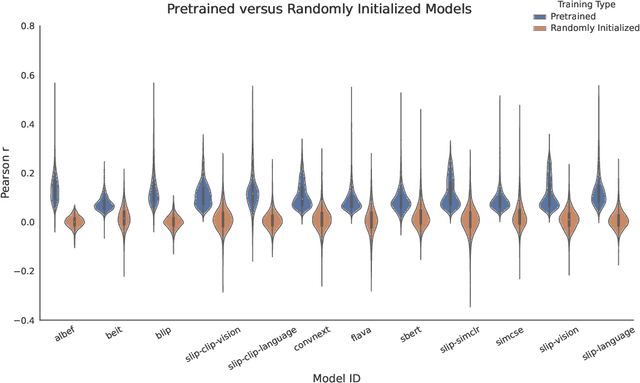
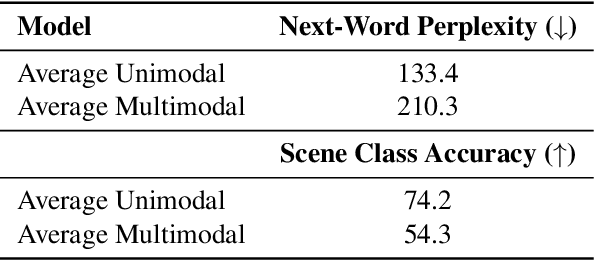
We use (multi)modal deep neural networks (DNNs) to probe for sites of multimodal integration in the human brain by predicting stereoencephalography (SEEG) recordings taken while human subjects watched movies. We operationalize sites of multimodal integration as regions where a multimodal vision-language model predicts recordings better than unimodal language, unimodal vision, or linearly-integrated language-vision models. Our target DNN models span different architectures (e.g., convolutional networks and transformers) and multimodal training techniques (e.g., cross-attention and contrastive learning). As a key enabling step, we first demonstrate that trained vision and language models systematically outperform their randomly initialized counterparts in their ability to predict SEEG signals. We then compare unimodal and multimodal models against one another. Because our target DNN models often have different architectures, number of parameters, and training sets (possibly obscuring those differences attributable to integration), we carry out a controlled comparison of two models (SLIP and SimCLR), which keep all of these attributes the same aside from input modality. Using this approach, we identify a sizable number of neural sites (on average 141 out of 1090 total sites or 12.94%) and brain regions where multimodal integration seems to occur. Additionally, we find that among the variants of multimodal training techniques we assess, CLIP-style training is the best suited for downstream prediction of the neural activity in these sites.
Testing Relational Understanding in Text-Guided Image Generation
Jul 29, 2022
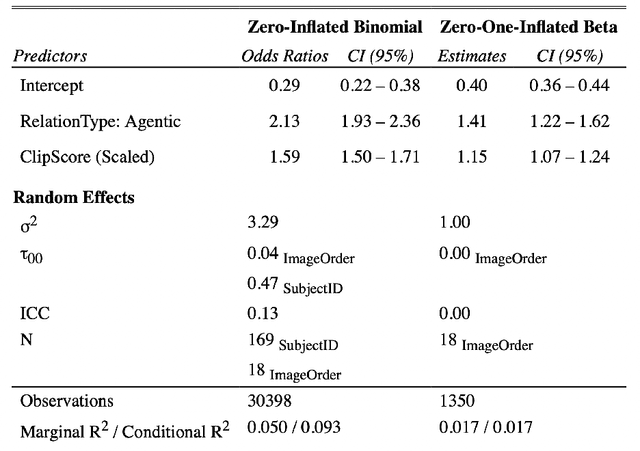
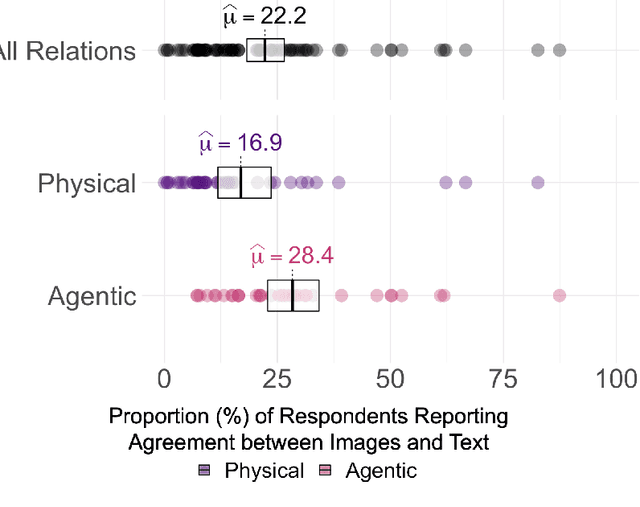
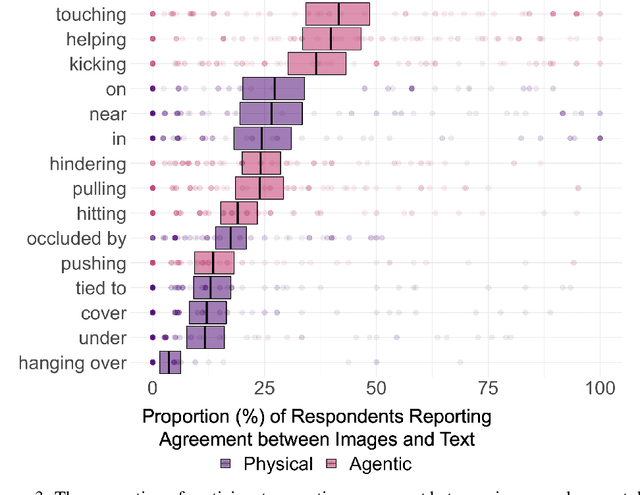
Relations are basic building blocks of human cognition. Classic and recent work suggests that many relations are early developing, and quickly perceived. Machine models that aspire to human-level perception and reasoning should reflect the ability to recognize and reason generatively about relations. We report a systematic empirical examination of a recent text-guided image generation model (DALL-E 2), using a set of 15 basic physical and social relations studied or proposed in the literature, and judgements from human participants (N = 169). Overall, we find that only ~22% of images matched basic relation prompts. Based on a quantitative examination of people's judgments, we suggest that current image generation models do not yet have a grasp of even basic relations involving simple objects and agents. We examine reasons for model successes and failures, and suggest possible improvements based on computations observed in biological intelligence.
On the use of Cortical Magnification and Saccades as Biological Proxies for Data Augmentation
Dec 14, 2021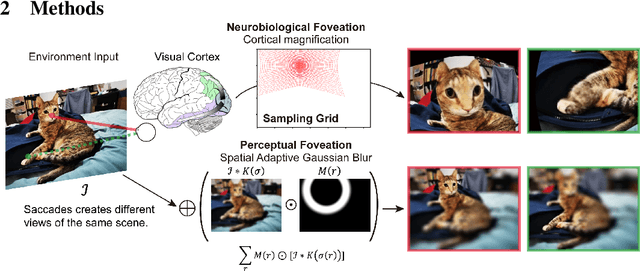
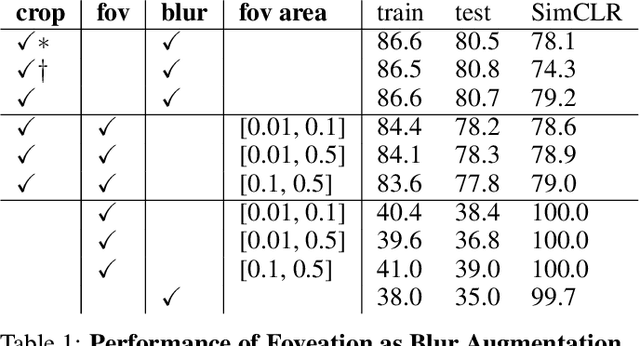
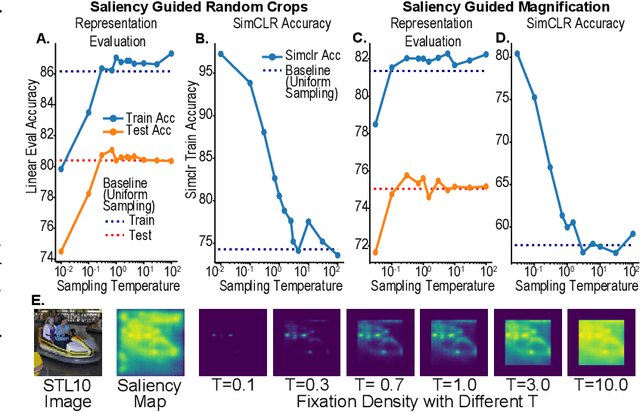
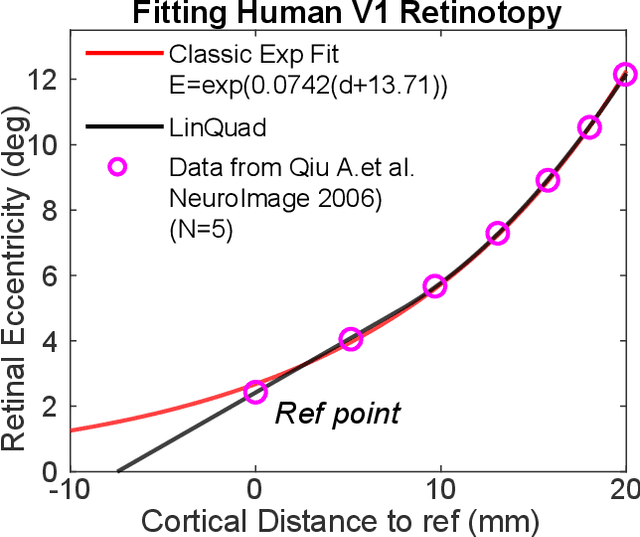
Self-supervised learning is a powerful way to learn useful representations from natural data. It has also been suggested as one possible means of building visual representation in humans, but the specific objective and algorithm are unknown. Currently, most self-supervised methods encourage the system to learn an invariant representation of different transformations of the same image in contrast to those of other images. However, such transformations are generally non-biologically plausible, and often consist of contrived perceptual schemes such as random cropping and color jittering. In this paper, we attempt to reverse-engineer these augmentations to be more biologically or perceptually plausible while still conferring the same benefits for encouraging robust representation. Critically, we find that random cropping can be substituted by cortical magnification, and saccade-like sampling of the image could also assist the representation learning. The feasibility of these transformations suggests a potential way that biological visual systems could implement self-supervision. Further, they break the widely accepted spatially-uniform processing assumption used in many computer vision algorithms, suggesting a role for spatially-adaptive computation in humans and machines alike. Our code and demo can be found here.