 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the use of Cortical Magnification and Saccades as Biological Proxies for Data Augmentation
Paper and Code
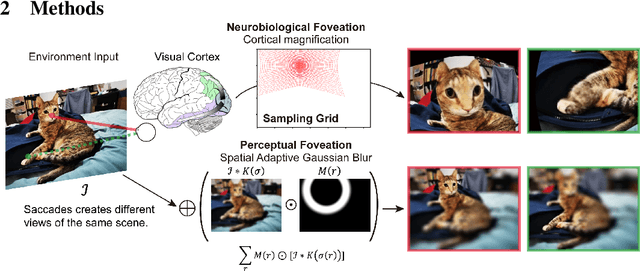
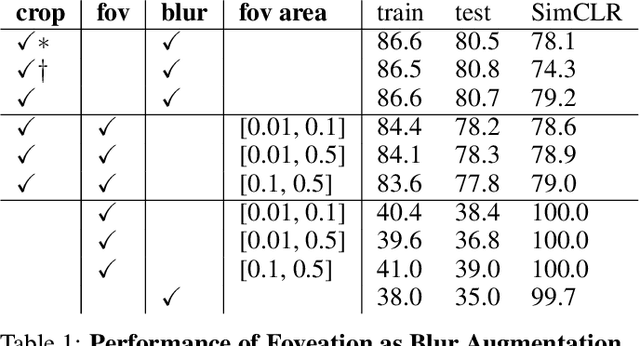
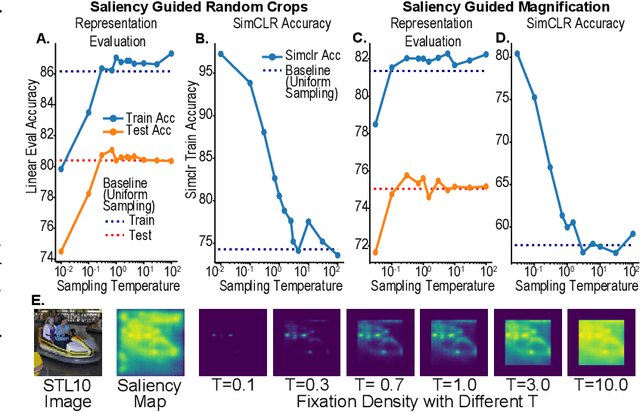
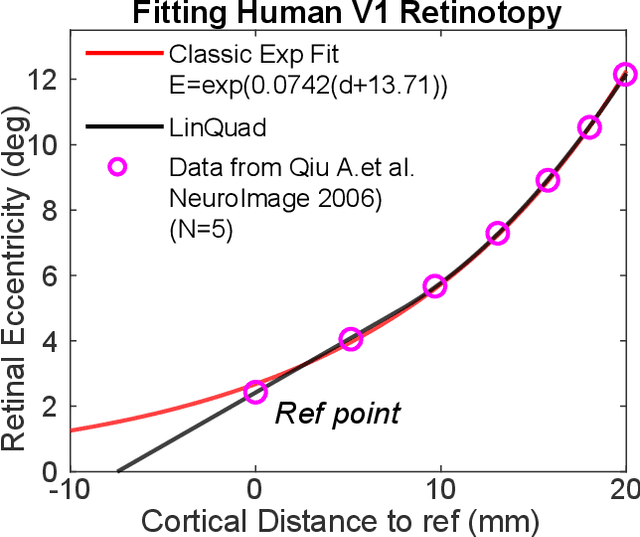
Self-supervised learning is a powerful way to learn useful representations from natural data. It has also been suggested as one possible means of building visual representation in humans, but the specific objective and algorithm are unknown. Currently, most self-supervised methods encourage the system to learn an invariant representation of different transformations of the same image in contrast to those of other images. However, such transformations are generally non-biologically plausible, and often consist of contrived perceptual schemes such as random cropping and color jittering. In this paper, we attempt to reverse-engineer these augmentations to be more biologically or perceptually plausible while still conferring the same benefits for encouraging robust representation. Critically, we find that random cropping can be substituted by cortical magnification, and saccade-like sampling of the image could also assist the representation learning. The feasibility of these transformations suggests a potential way that biological visual systems could implement self-supervision. Further, they break the widely accepted spatially-uniform processing assumption used in many computer vision algorithms, suggesting a role for spatially-adaptive computation in humans and machines alike. Our code and demo can be found here.