 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unreasonable Effectiveness of Gaussian Score Approximation for Diffusion Models and its Applications
Paper and Code
Dec 12, 2024
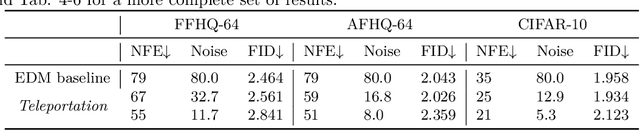
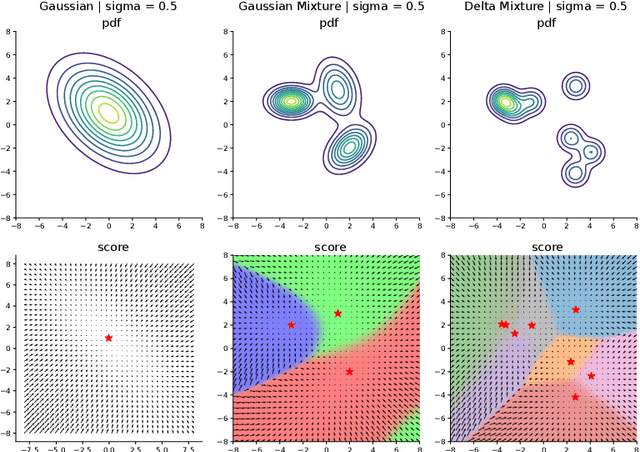

By learning the gradient of smoothed data distributions, diffusion models can iteratively generate samples from complex distributions. The learned score function enables their generalization capabilities, but how the learned score relates to the score of the underlying data manifold remains largely unclear. Here, we aim to elucidate this relationship by comparing learned neural scores to the scores of two kinds of analytically tractable distributions: Gaussians and Gaussian mixtures. The simplicity of the Gaussian model makes it theoretically attractive, and we show that it admits a closed-form solution and predicts many qualitative aspects of sample generation dynamics. We claim that the learned neural score is dominated by its linear (Gaussian) approximation for moderate to high noise scales, and supply both theoretical and empirical arguments to support this claim. Moreover, the Gaussian approximation empirically works for a larger range of noise scales than naive theory suggests it should, and is preferentially learned early in training. At smaller noise scales, we observe that learned scores are better described by a coarse-grained (Gaussian mixture) approximation of training data than by the score of the training distribution, a finding consistent with generalization. Our findings enable us to precisely predict the initial phase of trained models' sampling trajectories through their Gaussian approximations. We show that this allows the skipping of the first 15-30% of sampling steps while maintaining high sample quality (with a near state-of-the-art FID score of 1.93 on CIFAR-10 unconditional generation). This forms the foundation of a novel hybrid sampling method, termed analytical teleportation, which can seamlessly integrate with and accelerate existing samplers, including DPM-Solver-v3 and UniPC. Our findings suggest ways to improve the design and training of diffusion models.